¿Qué es el bootstrap?
El bootstrap, introducido por Bradley Efron en 1979, es un método de remuestreo que estima la distribución muestral de cualquier estadístico mediante extracciones repetidas con reemplazamiento de los datos originales. No requiere supuestos sobre la distribución de la población y funciona para estadísticos cuya distribución teórica es intratable.
La idea fundamental
La inferencia clásica deriva la distribución muestral de \(\hat{\theta}\) a partir de supuestos sobre la población (por ejemplo, normalidad). El bootstrap invierte esta lógica: usa los propios datos como sustituto de la población y simula el proceso de muestreo remuestreando los datos observados.
El razonamiento: si la muestra es una buena representación de la población, las muestras extraídas de la muestra con reemplazamiento se comportan como muestras extraídas de la población. La distribución de \(\hat{\theta}^*\) a lo largo de muchas muestras bootstrap aproxima la verdadera distribución muestral de \(\hat{\theta}\).
El principio bootstrap:
\[\text{Población} \xrightarrow{\text{muestreo}} \text{Muestra} \xrightarrow{\text{remuestreo con reemplazamiento}} \text{Muestras bootstrap}\]
\[\text{Distribución real de } \hat{\theta} \approx \text{Distribución bootstrap de } \hat{\theta}^*\]
El algoritmo
Dada una muestra original \(\mathbf{x} = (x_1, x_2, \ldots, x_n)\) y un estadístico de interés \(\hat{\theta} = g(\mathbf{x})\):
- Extrae una muestra bootstrap \(\mathbf{x}^* = (x_1^*, \ldots, x_n^*)\) de tamaño \(n\) muestreando con reemplazamiento de \(\mathbf{x}\).
- Calcula \(\hat{\theta}^* = g(\mathbf{x}^*)\).
- Repite los pasos 1-2 \(B\) veces, obteniendo \(\hat{\theta}^*_1, \hat{\theta}^*_2, \ldots, \hat{\theta}^*_B\).
- Usa la distribución de \(\{\hat{\theta}^*_b\}\) para estimar la distribución muestral de \(\hat{\theta}\).
\(B = 1{.}000\) es un mínimo habitual para la estimación del error estándar; \(B = 10{.}000\) para intervalos de confianza.
Ejemplo: distribución bootstrap de la mediana
La distribución muestral de la mediana no tiene forma cerrada sencilla para la mayoría de las poblaciones. El bootstrap proporciona una aproximación empírica.
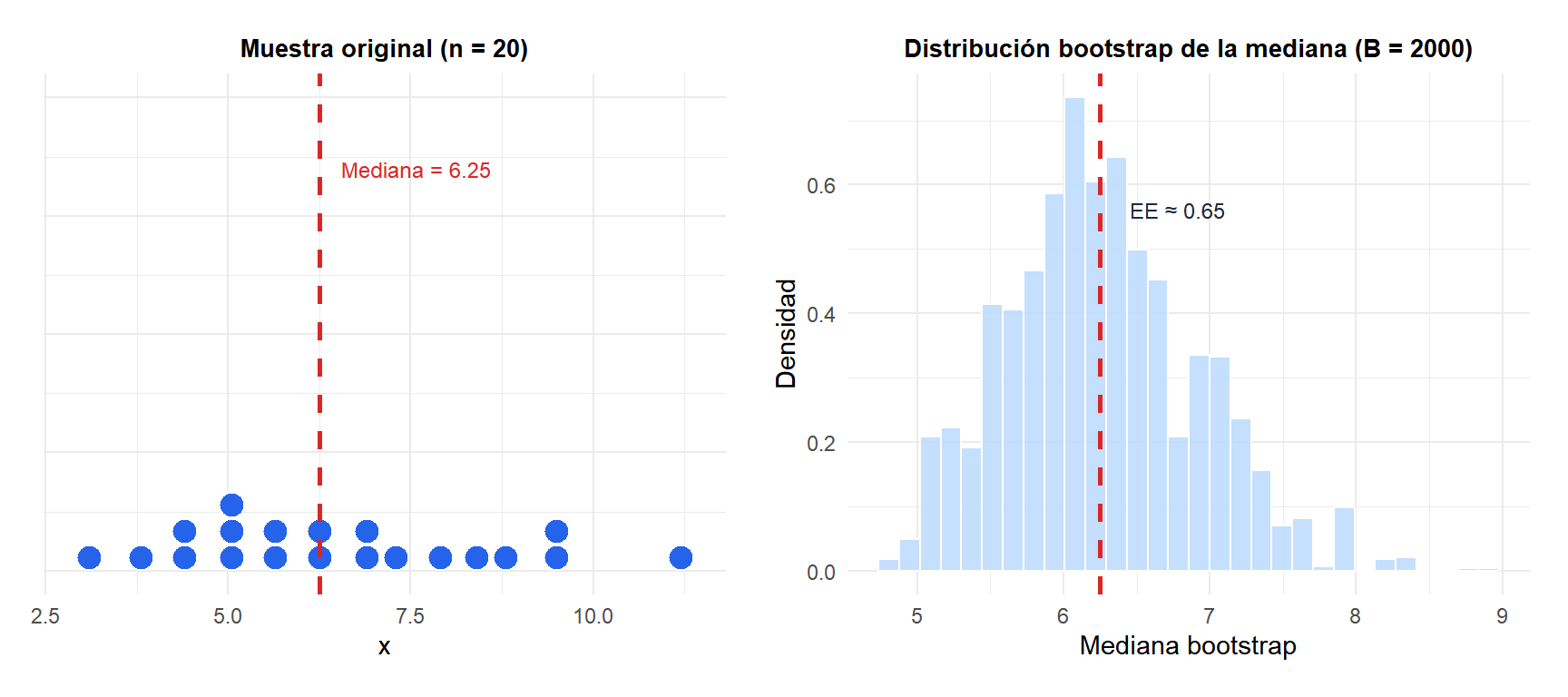
El panel izquierdo muestra la muestra original con su mediana observada. El panel derecho muestra la distribución de la mediana a lo largo de 2.000 remuestras bootstrap: aproximadamente normal y centrada en la mediana observada. La desviación típica de esta distribución es el error estándar bootstrap de la mediana.
Qué estima el bootstrap
La distribución bootstrap de \(\hat{\theta}^*\) centrada en \(\hat{\theta}\) aproxima la distribución muestral de \(\hat{\theta}\) centrada en \(\theta\). A partir de ella podemos estimar:
- Error estándar: \(\widehat{\text{EE}}_\text{boot} = \text{DT}(\hat{\theta}^*_1, \ldots, \hat{\theta}^*_B)\).
- Sesgo: \(\widehat{\text{Sesgo}}_\text{boot} = \bar{\hat{\theta}}^* - \hat{\theta}\), donde \(\bar{\hat{\theta}}^*\) es la media de las estimaciones bootstrap.
- Intervalos de confianza: percentil, básico, BCa (cubiertos en el post sobre IC bootstrap).
- Forma de la distribución muestral: útil para detectar asimetría o multimodalidad.
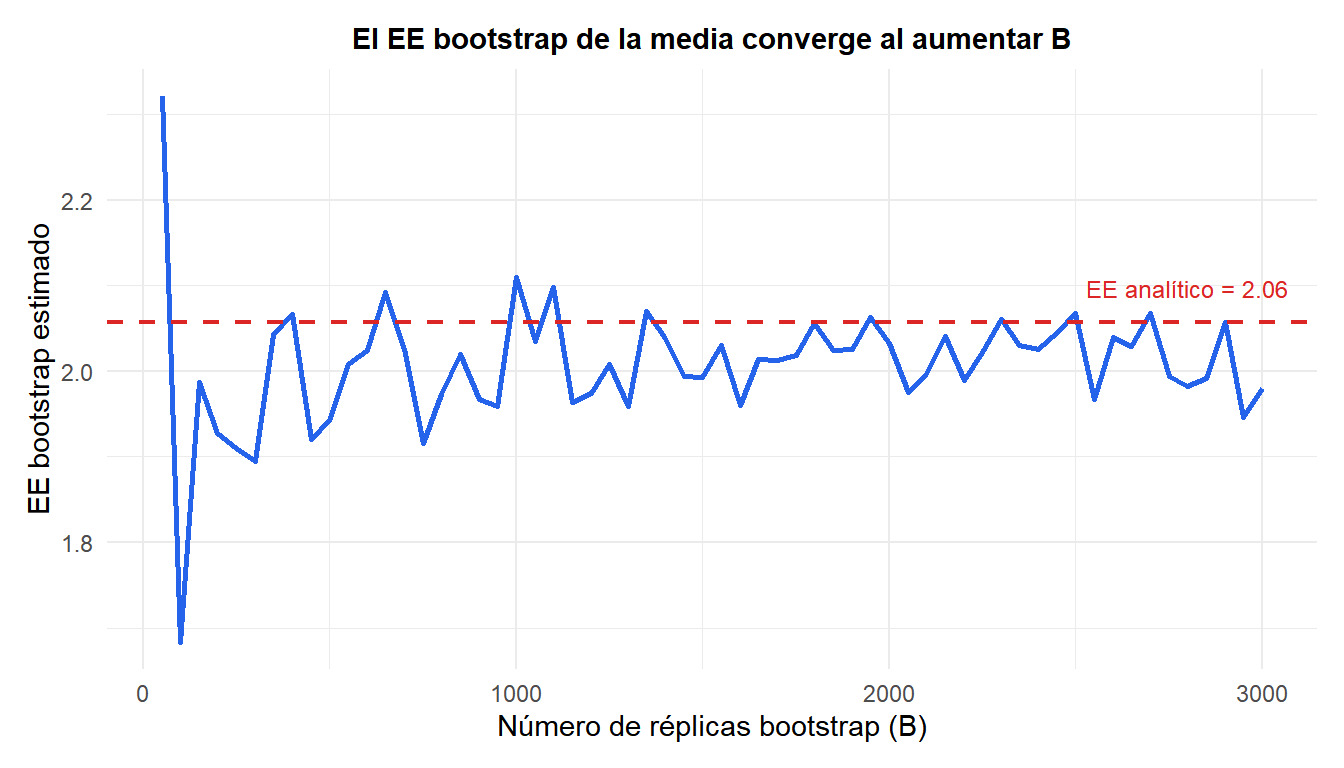
El EE bootstrap converge rápidamente: en \(B = 500\) ya está próximo al valor analítico. Para los intervalos de confianza se recomienda un \(B\) mayor (típicamente 2.000-10.000) para obtener estabilidad en las colas.
Por qué funciona
El bootstrap se justifica por el principio del complemento: sustituir la distribución poblacional desconocida \(F\) por la distribución empírica \(\hat{F}_n\) (que asigna probabilidad \(1/n\) a cada valor observado). Cualquier funcional de \(F\) (media, varianza, cuantil) puede entonces estimarse mediante el funcional correspondiente de \(\hat{F}_n\).
Remuestrear con reemplazamiento de la muestra original equivale a muestrear de \(\hat{F}_n\). Cuando \(n \to \infty\), \(\hat{F}_n \to F\) (por el teorema de Glivenko-Cantelli), por lo que la aproximación bootstrap mejora con muestras más grandes.
Limitaciones
⚠️ Cuándo el bootstrap falla o funciona mal
El bootstrap no es universalmente válido. Puede fallar cuando:
- Muestras pequeñas: \(\hat{F}_n\) es una mala aproximación de \(F\) con pocas observaciones. El bootstrap suavizado (siguiente post) aborda parcialmente esto.
- Cuantiles extremos: estimar el percentil 99 a partir de \(n = 50\) observaciones es poco fiable incluso con bootstrap, porque las colas de \(\hat{F}_n\) están mal estimadas.
- Datos dependientes: el bootstrap estándar asume observaciones i.i.d. Para series temporales, usa el bootstrap por bloques o el bootstrap por bloques circular.
- Estadísticos no suaves: el bootstrap puede ser inconsistente para estadísticos como el máximo muestral o estadísticos con discontinuidades.
Cuando el bootstrap falla, el bootstrap paramétrico (asumiendo una familia distribucional específica) es a menudo una alternativa mejor.
💡 ¿Cuántas réplicas bootstrap?
- Estimación del error estándar: \(B = 200\)-\(500\) suele ser suficiente.
- Intervalos de confianza percentil: \(B = 1{.}000\)-\(2{.}000\).
- Intervalos de confianza BCa: \(B = 5{.}000\)-\(10{.}000\) para resultados estables.
- P-valores de contrastes de hipótesis: \(B \geq 10{.}000\) para p-valores próximos al umbral de significación.
En R: boot::boot(data, statistic, R = 1000). La función statistic debe aceptar los datos y un vector de índices como argumentos.

