Probabilidad condicionada
La probabilidad condicionada responde a la pregunta: dado que sabemos que \(B\) ha ocurrido, ¿cómo cambia eso la probabilidad de \(A\)? Es el fundamento del razonamiento bayesiano, los tests médicos, los filtros de spam y cualquier situación en la que nueva información actualiza nuestra incertidumbre.
Definición
La probabilidad condicionada de \(A\) dado \(B\) es la probabilidad de que \(A\) ocurra, restringida a los casos en que \(B\) ya ha ocurrido:
\[P(A \mid B) = \frac{P(A \cap B)}{P(B)}, \quad P(B) > 0\]
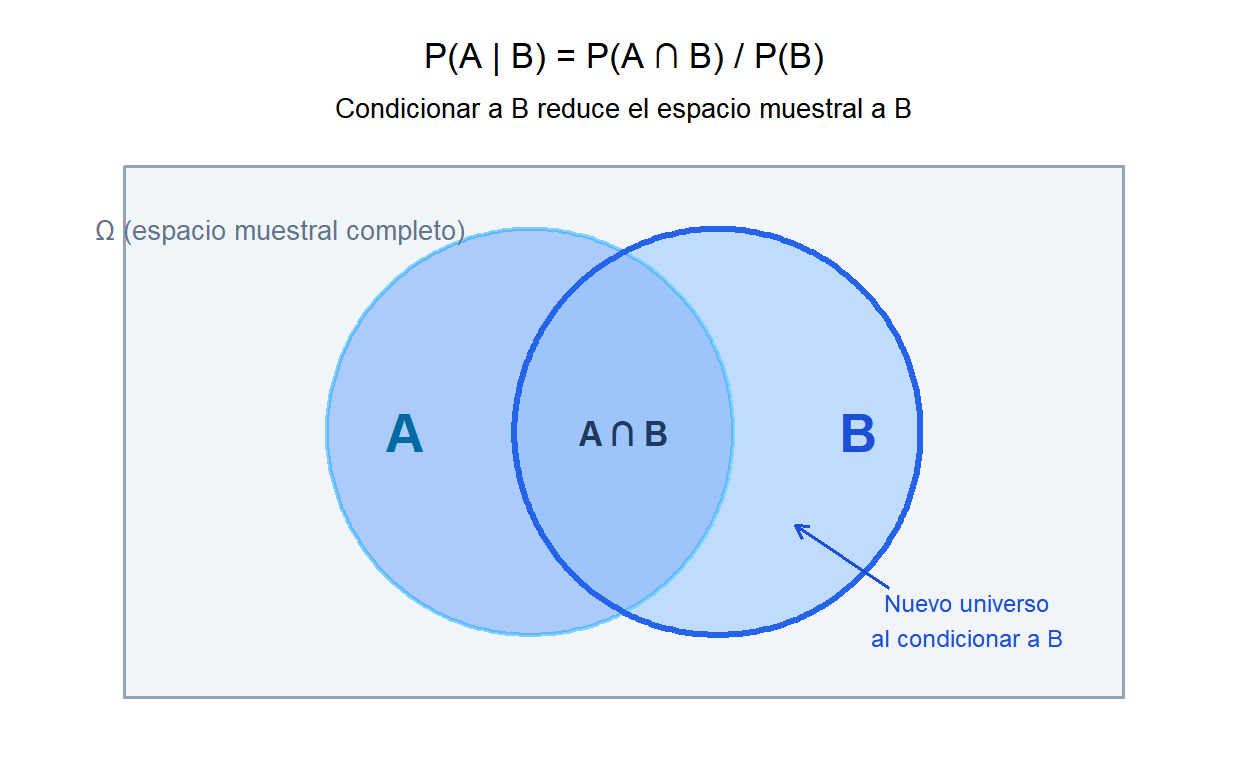
Geométricamente, condicionar a \(B\) significa reducir el espacio muestral a \(B\) y preguntar qué fracción de \(B\) está también en \(A\). La fórmula divide la intersección \(P(A \cap B)\) entre el nuevo “universo” \(P(B)\).
De esta definición se obtiene de inmediato la regla de la multiplicación:
\[P(A \cap B) = P(A \mid B) \cdot P(B) = P(B \mid A) \cdot P(A)\]
⚠️ P(A|B) ≠ P(B|A): la asimetría más importante en probabilidad
\(P(A \mid B)\) y \(P(B \mid A)\) son cantidades completamente distintas. Confundirlas tiene consecuencias graves:
- \(P(\text{test positivo} \mid \text{tiene la enfermedad})\) es la sensibilidad del test, lo que informa el laboratorio.
- \(P(\text{tiene la enfermedad} \mid \text{test positivo})\) es lo que el paciente quiere saber, y depende de manera decisiva de la rareza de la enfermedad.
En el contexto judicial esto se llama falacia del fiscal: confundir \(P(\text{evidencia} \mid \text{inocente})\) con \(P(\text{inocente} \mid \text{evidencia})\). Varias condenas erróneas se han vinculado a este error.
Ley de la probabilidad total
Para calcular \(P(B)\) en el denominador de la fórmula de la probabilidad condicionada, a menudo hay que tener en cuenta todas las formas en que \(B\) puede ocurrir. Si \(A_1, A_2, \ldots, A_n\) forman una partición del espacio muestral (mutuamente excluyentes y exhaustivos), entonces:
\[P(B) = \sum_{i=1}^{n} P(B \mid A_i) \cdot P(A_i)\]
Esta es la ley de la probabilidad total. Descompone \(P(B)\) en las contribuciones de cada escenario \(A_i\).
Una fábrica tiene tres líneas de producción que contribuyen el 50%, el 30% y el 20% de la producción total. Sus tasas de defectos son el 2%, el 4% y el 6% respectivamente. ¿Cuál es la tasa de defectos global?
\[P(\text{defecto}) = 0{,}02 \times 0{,}50 + 0{,}04 \times 0{,}30 + 0{,}06 \times 0{,}20\] \[= 0{,}010 + 0{,}012 + 0{,}012 = 0{,}034\]
La tasa de defectos global es del 3,4%.
Ejemplos paso a paso
Ejemplo 1: test médico (cálculo completo)
Una enfermedad afecta al 1% de la población (\(P(E) = 0{,}01\)). Un test diagnóstico tiene: - Sensibilidad: \(P(\text{pos} \mid E) = 0{,}95\) (detecta el 95% de los casos verdaderos). - Tasa de falsos positivos: \(P(\text{pos} \mid E^c) = 0{,}05\) (marca al 5% de las personas sanas).
Un paciente da positivo. ¿Cuál es la probabilidad de que tenga la enfermedad?
Paso 1: calcula \(P(\text{pos})\) usando la ley de la probabilidad total:
\[P(\text{pos}) = P(\text{pos} \mid E) \cdot P(E) + P(\text{pos} \mid E^c) \cdot P(E^c)\] \[= 0{,}95 \times 0{,}01 + 0{,}05 \times 0{,}99 = 0{,}0095 + 0{,}0495 = 0{,}059\]
Paso 2: aplica la fórmula de la probabilidad condicionada:
\[P(E \mid \text{pos}) = \frac{P(\text{pos} \mid E) \cdot P(E)}{P(\text{pos})} = \frac{0{,}0095}{0{,}059} \approx 0{,}161\]
Solo el 16% de las personas que dan positivo tienen realmente la enfermedad. El test es preciso, pero la enfermedad es suficientemente rara como para que la mayoría de los positivos sean falsas alarmas. Este es el efecto de la tasa base: la probabilidad a priori de tener la enfermedad (\(P(E) = 0{,}01\)) domina el resultado.
En lugar de probabilidades, piensa en 10.000 personas:
- 100 tienen la enfermedad. De ellas, \(95\) dan positivo (verdaderos positivos).
- 9.900 están sanas. De ellas, \(495\) dan positivo (falsos positivos).
Total de positivos: \(95 + 495 = 590\).
\(P(E \mid \text{pos}) = 95/590 \approx 0{,}161\). La misma respuesta, mucho más intuitiva.
Este enfoque de frecuencias naturales es el recomendado por los estadísticos para comunicar riesgos a pacientes o responsables políticos.
Ejemplo 2: proceso de selección secuencial
Un proceso de selección tiene dos etapas. Los datos históricos muestran: - El 40% de los candidatos supera la primera entrevista: \(P(S_1) = 0{,}40\). - De ellos, el 35% supera la segunda: \(P(S_2 \mid S_1) = 0{,}35\).
Probabilidad de superar ambas:
\[P(S_1 \cap S_2) = P(S_2 \mid S_1) \cdot P(S_1) = 0{,}35 \times 0{,}40 = 0{,}14\]
El 14% de los candidatos pasa las dos rondas.
Ahora supón que sabemos que un candidato superó la segunda entrevista. ¿Cuál es la probabilidad de que también superara la primera? (Necesariamente la superó, ya que la segunda requiere haber pasado la primera.)
\[P(S_1 \mid S_2) = \frac{P(S_1 \cap S_2)}{P(S_2)}\]
Necesitamos \(P(S_2)\). Como no se puede llegar a la segunda etapa sin superar la primera: \(P(S_2) = P(S_1 \cap S_2) = 0{,}14\).
\[P(S_1 \mid S_2) = \frac{0{,}14}{0{,}14} = 1\]
Como era de esperar: si superaste la segunda etapa, necesariamente superaste la primera.
Ejemplo 3: filtro de spam
Un filtro de spam analiza la palabra “gratis” en los correos: - El 60% de los correos spam contienen “gratis”: \(P(\text{gratis} \mid \text{spam}) = 0{,}60\). - El 5% de los correos legítimos contienen “gratis”: \(P(\text{gratis} \mid \text{legít.}) = 0{,}05\). - El 30% de los correos entrantes son spam: \(P(\text{spam}) = 0{,}30\).
Llega un correo con la palabra “gratis”. ¿Cuál es la probabilidad de que sea spam?
\[P(\text{gratis}) = 0{,}60 \times 0{,}30 + 0{,}05 \times 0{,}70 = 0{,}180 + 0{,}035 = 0{,}215\]
\[P(\text{spam} \mid \text{gratis}) = \frac{0{,}60 \times 0{,}30}{0{,}215} = \frac{0{,}18}{0{,}215} \approx 0{,}837\]
Un 84% de probabilidad de spam por la presencia de la palabra “gratis”. Los filtros de spam reales aplican esta lógica a cientos de palabras simultáneamente usando la clasificación de Naive Bayes.
Conexión con la independencia
Los eventos \(A\) y \(B\) son independientes si y solo si:
\[P(A \mid B) = P(A)\]
Es decir, saber que \(B\) ha ocurrido no cambia la probabilidad de \(A\). Cuando esto se cumple, la fórmula de la probabilidad condicionada da \(P(A \cap B) = P(A) \cdot P(B)\), que es la definición de independencia.
La probabilidad condicionada es, por tanto, el caso general: la independencia es el caso especial en que condicionar no tiene efecto.
💡 La probabilidad condicionada cambia el espacio muestral
La intuición clave: condicionar a \(B\) reemplaza el espacio muestral original \(\Omega\) por el espacio restringido \(B\). Todas las probabilidades se recalculan dentro de este universo más pequeño. Por eso \(P(A \mid B)\) puede ser muy distinta de \(P(A)\): estamos haciendo una pregunta completamente diferente. No “¿con qué frecuencia ocurre \(A\)?” sino “entre los casos en que ocurrió \(B\), ¿con qué frecuencia ocurre también \(A\)?”

