Programación dinámica
La programación dinámica (PD) resuelve problemas de optimización dividiéndolos en subproblemas solapados, resolviendo cada uno una sola vez y almacenando el resultado. Convierte algoritmos recursivos de tiempo exponencial en algoritmos de tiempo polinomial. La clave: si la solución óptima global puede construirse a partir de soluciones óptimas de subproblemas, la PD es aplicable.
Dos condiciones para la programación dinámica
La PD funciona cuando un problema tiene dos propiedades:
1. Subestructura óptima
La solución óptima del problema contiene soluciones óptimas de sus subproblemas. Este es el principio de optimalidad de Bellman: una política óptima tiene la propiedad de que, cualesquiera que sean el estado y la decisión iniciales, las decisiones restantes deben constituir una política óptima respecto al estado resultante de la primera decisión.
Si la solución óptima del problema completo puede construirse a partir de soluciones óptimas de instancias más pequeñas, el problema tiene subestructura óptima.
2. Subproblemas solapados
La solución recursiva resuelve los mismos subproblemas repetidamente. Esto distingue la PD de divide y vencerás (que también usa subestructura óptima pero tiene subproblemas no solapados, por ejemplo, merge sort).
Si los mismos subproblemas aparecen muchas veces, almacenar sus soluciones (memoización o tabulación) evita la computación redundante y reduce el tiempo exponencial a polinomial.
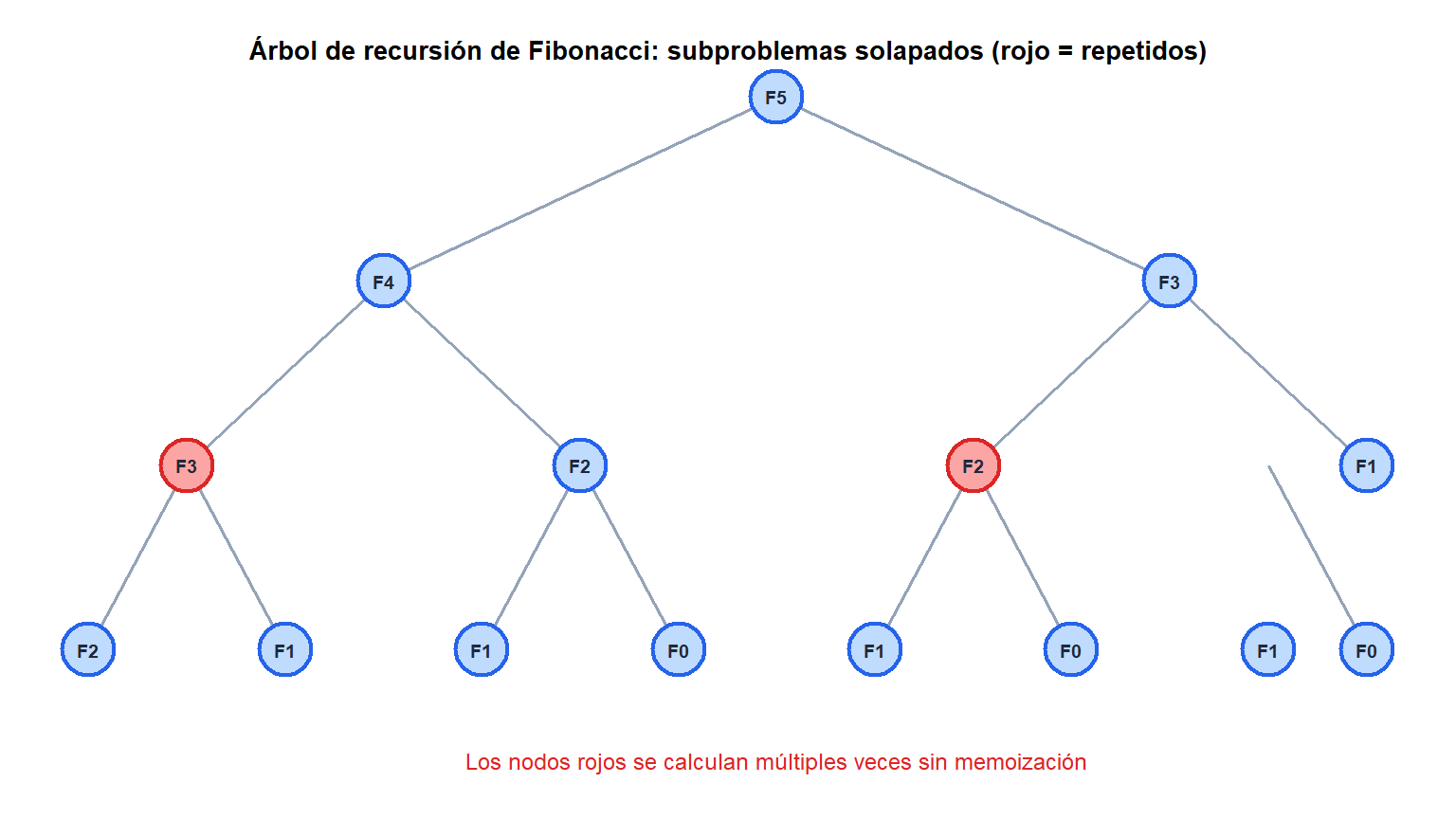
Sin memoización, calcular \(F_n\) tarda \(O(2^n)\). Con memoización, cada uno de los \(n\) subproblemas distintos se resuelve una sola vez: \(O(n)\).
Arriba-abajo vs abajo-arriba
Hay dos formas equivalentes de implementar la PD:
Arriba-abajo (memoización)
Escribir la solución recursiva de forma natural. Añadir una caché (tabla hash o array) para almacenar los resultados de los subproblemas a medida que se calculan. Antes de resolver un subproblema, comprobar si el resultado ya está en caché.
memo <- c()
fib <- function(n) {
if (n <= 1) return(n)
if (!is.na(memo[n])) return(memo[n])
result <- fib(n-1) + fib(n-2)
memo[n] <<- result
result
}Ventaja: solo calcula los subproblemas que realmente se necesitan. Desventaja: coste de la pila de llamadas recursivas; puede alcanzar el límite de pila para \(n\) grande.
Abajo-arriba (tabulación)
Rellenar una tabla de soluciones de subproblemas en orden de menor a mayor. Cada entrada se calcula usando las entradas ya rellenadas.
fib_dp <- function(n) {
if (n <= 1) return(n)
dp <- numeric(n+1)
dp[1] <- 0; dp[2] <- 1
for (i in 3:(n+1)) dp[i] <- dp[i-1] + dp[i-2]
dp[n+1]
}Ventaja: sin coste de recursión; naturalmente iterativa; más fácil de analizar la complejidad espacial. Desventaja: calcula todos los subproblemas aunque algunos no sean necesarios.
En la práctica, la versión abajo-arriba suele preferirse por su simplicidad y eficiencia.
Ejemplo 1: mochila 0/1
\(n\) objetos con valores \(v_i\) y pesos \(w_i\). Capacidad de la mochila \(W\). Maximizar el valor total sujeto al límite de peso. Cada objeto se toma (1) o no (0).
Subestructura: definir \(dp[i][w]\) = valor máximo usando los objetos \(1,\ldots,i\) con capacidad \(w\).
Recurrencia:
\[dp[i][w] = \begin{cases} dp[i-1][w] & \text{si } w_i > w \text{ (el objeto } i \text{ no cabe)} \\ \max(dp[i-1][w],\; v_i + dp[i-1][w-w_i]) & \text{en caso contrario} \end{cases}\]
Caso base: \(dp[0][w] = 0\) para todo \(w\) (sin objetos, sin valor).
Complejidad: \(O(nW)\) (pseudopolinomial: polinomial en \(n\) y \(W\), pero exponencial en el número de bits de \(W\)).
| Objeto | Valor | Peso |
|---|---|---|
| 1 | 3 | 2 |
| 2 | 4 | 3 |
| 3 | 5 | 4 |
| 4 | 6 | 5 |
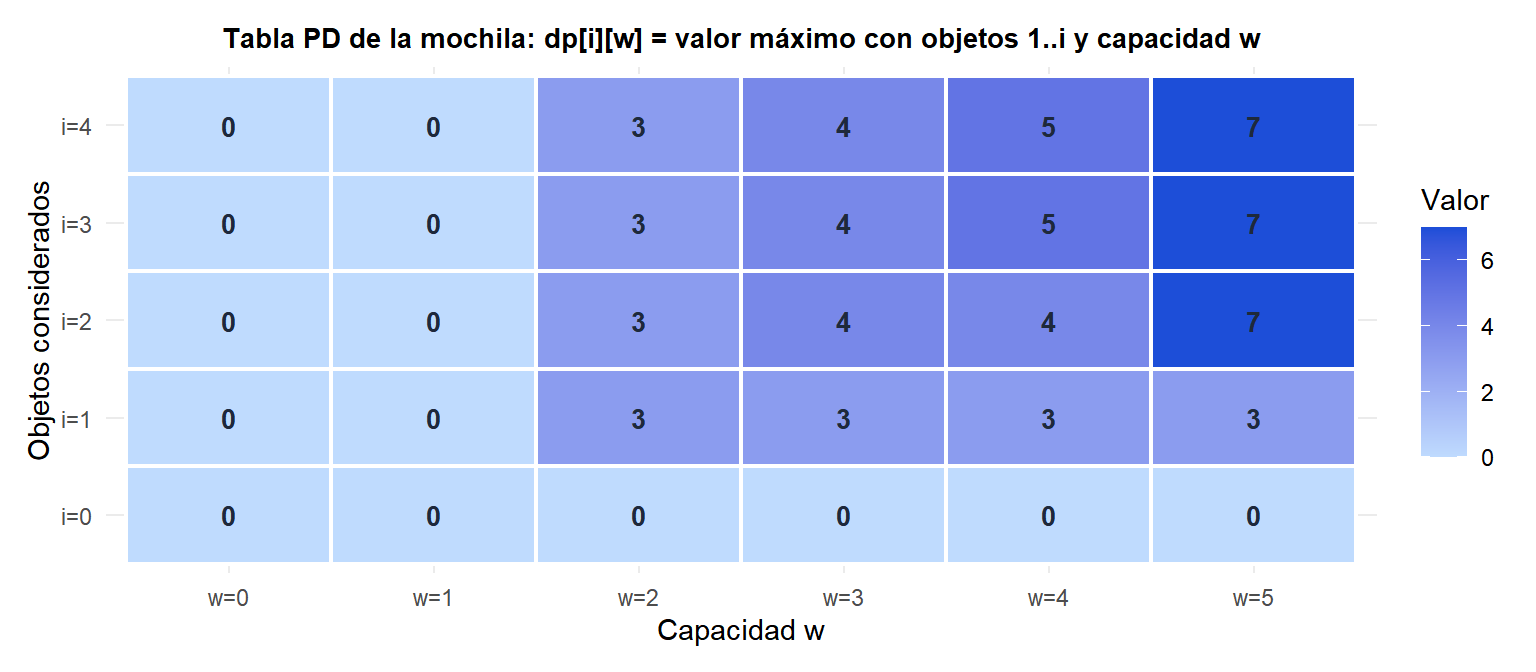
Tabla PD \(dp[i][w]\):
| w=0 | w=1 | w=2 | w=3 | w=4 | w=5 | |
|---|---|---|---|---|---|---|
| i=0 | 0 | 0 | 0 | 0 | 0 | 0 |
| i=1 | 0 | 0 | 3 | 3 | 3 | 3 |
| i=2 | 0 | 0 | 3 | 4 | 4 | 7 |
| i=3 | 0 | 0 | 3 | 4 | 5 | 7 |
| i=4 | 0 | 0 | 3 | 4 | 5 | 7 |
Valor óptimo: \(dp[4][5] = 7\) (tomar objetos 1 y 2: \(3+4=7\), \(2+3=5 \leq W\)).
Ejemplo 2: Subsecuencia Común más Larga (LCS)
Dadas dos cadenas \(X = x_1\ldots x_m\) e \(Y = y_1\ldots y_n\), encontrar la subsecuencia común más larga (no necesariamente contigua).
Subestructura: definir \(dp[i][j]\) = longitud de la LCS de \(X[1..i]\) e \(Y[1..j]\).
Recurrencia:
\[dp[i][j] = \begin{cases} 0 & i=0 \text{ o } j=0 \\ dp[i-1][j-1] + 1 & x_i = y_j \\ \max(dp[i-1][j],\; dp[i][j-1]) & x_i \neq y_j \end{cases}\]
Tiempo y espacio: \(O(mn)\) para ambos. La LCS en sí se recupera retrocediendo por la tabla.
Longitud de la LCS = 4 (por ejemplo, BCAB o BDAB). La tabla PD rellena \(O(7 \times 5) = 35\) celdas en lugar de comprobar todas las \(2^7 = 128\) subsecuencias de \(X\).
Conexión con Dijkstra
El algoritmo de Dijkstra es un caso especial de programación dinámica. El camino más corto de \(s\) a \(v\) satisface:
\[d[v] = \min_{u: (u,v) \in E} \{d[u] + w(u,v)\}\]
Esta es una recurrencia de PD: el camino más corto hasta \(v\) se construye a partir del camino más corto hasta su predecesor \(u\). La propiedad de subestructura óptima se cumple porque cualquier subcamino de un camino más corto es también un camino más corto.
La diferencia con la PD genérica: Dijkstra aprovecha la no negatividad de los pesos para procesar los subproblemas en orden de distancia creciente, evitando la necesidad de rellenar una tabla completa \(|V| \times |V|\).
Más en general, los caminos más cortos en DAGs pueden resolverse con una simple PD en orden topológico: \(O(V+E)\), más rápido que \(O((V+E)\log V)\) de Dijkstra.
Cuándo no se aplica la PD
⚠️ La PD requiere subestructura óptima: no todos los problemas la tienen
El contraejemplo clásico: el camino simple más largo en un grafo general. A diferencia de los caminos más cortos, los caminos más largos no tienen subestructura óptima. Conocer el camino más largo desde \(s\) hasta un vértice intermedio \(u\) no ayuda a encontrar el camino más largo desde \(s\) hasta \(v\) pasando por \(u\): combinar dos caminos largos puede crear un ciclo (visitando un vértice dos veces), violando el requisito de camino simple.
El camino simple más largo es NP-duro en grafos generales, mientras que el camino más corto es resoluble en tiempo polinomial precisamente gracias a la subestructura óptima.
Antes de aplicar PD, verificar que la solución óptima del problema completo depende realmente solo de soluciones óptimas de subproblemas, sin interferencia entre las soluciones de los subproblemas.
Complejidad y la maldición de la dimensionalidad
La PD intercambia tiempo por espacio: almacena las soluciones de todos los subproblemas. El espacio de estados determina tanto la complejidad temporal como la espacial. Para una PD con \(k\) variables de estado que toman \(O(n)\) valores cada una, la tabla tiene \(O(n^k)\) entradas: exponencial en el número de variables de estado.
Esta es la maldición de la dimensionalidad en PD: añadir una variable de estado multiplica el tamaño de la tabla por \(n\). Para espacios de estado continuos (control estocástico, reinforcement learning), la tabla es infinita y se requieren aproximaciones.
Estrategias prácticas para gestionar el espacio de estados: arrays rodantes (conservar solo la última fila de la tabla PD), compromiso espacio-tiempo, compresión de estados para PD con máscara de bits.
💡 Programación dinámica en R
# Mochila 0/1
knapsack_dp <- function(values, weights, W) {
n <- length(values)
dp <- matrix(0, nrow=n+1, ncol=W+1)
for (i in 1:n) {
for (w in 1:W) {
dp[i+1, w+1] <- dp[i, w+1]
if (weights[i] <= w)
dp[i+1, w+1] <- max(dp[i+1, w+1],
values[i] + dp[i, w-weights[i]+1])
}
}
list(value=dp[n+1, W+1], table=dp)
}
knapsack_dp(c(3,4,5,6), c(2,3,4,5), W=5)$value # 7
# Longitud de la LCS
lcs_length <- function(X, Y) {
m <- nchar(X); n <- nchar(Y)
X <- strsplit(X,"")[[1]]; Y <- strsplit(Y,"")[[1]]
dp <- matrix(0, m+1, n+1)
for (i in 1:m) for (j in 1:n)
dp[i+1,j+1] <- if(X[i]==Y[j]) dp[i,j]+1 else max(dp[i,j+1],dp[i+1,j])
dp[m+1,n+1]
}
lcs_length("ABCBDAB", "BDCAB") # 4
