Intervalo de confianza para la media
El intervalo de confianza para la media ofrece un rango de valores plausibles para la media poblacional \(\mu\), teniendo en cuenta la variabilidad inherente a cualquier muestra. La distribución \(t\) es casi siempre la herramienta adecuada, ya que \(\sigma\) rara vez se conoce en la práctica.
Fórmula
Dada una muestra aleatoria de tamaño \(n\) con media muestral \(\bar{x}\) y desviación típica muestral \(S\), un intervalo de confianza al \((1-\alpha)\) para \(\mu\) es:
\[\bar{x} \pm t_{\alpha/2,\, n-1} \cdot \frac{S}{\sqrt{n}}\]
donde \(t_{\alpha/2,\, n-1}\) es el valor crítico de la distribución \(t\) con \(n-1\) grados de libertad tal que \(P(T > t_{\alpha/2}) = \alpha/2\).
Cuando \(\sigma\) es conocida (raro en la práctica), sustituye \(t_{\alpha/2,\, n-1}\) por \(z_{\alpha/2}\) y \(S\) por \(\sigma\).
⚠️ Usa siempre t cuando σ es desconocida, que es casi siempre
Un error frecuente es usar \(z = 1{,}96\) para un IC al 95% independientemente del tamaño muestral. El valor \(z\) solo es correcto cuando \(\sigma\) es verdaderamente conocida. Cuando \(\sigma\) se estima a partir de los datos (que es la situación habitual), la distribución \(t\) es la correcta.
Para \(n\) grande la diferencia es despreciable: \(t_{0{,}025,\, 100} \approx 1{,}984\) frente a \(z_{0{,}025} = 1{,}960\). Pero para muestras pequeñas la diferencia es notable: \(t_{0{,}025,\, 9} = 2{,}262\), lo que significa que el IC es considerablemente más amplio. Usar \(z\) con muestras pequeñas subestima la incertidumbre.
Valores críticos habituales para un IC al 95% (\(t_{0{,}025,\, n-1}\)):
| \(n\) | \(t_{0{,}025,\, n-1}\) |
|---|---|
| 5 | 2,776 |
| 10 | 2,228 |
| 20 | 2,093 |
| 30 | 2,045 |
| 60 | 2,000 |
| 120 | 1,980 |
| \(\infty\) | 1,960 |
Supuestos
La fórmula es exacta cuando la población es normal. Por el Teorema Central del Límite, es aproximadamente válida para poblaciones no normales cuando \(n\) es suficientemente grande (habitualmente \(n \geq 30\) como regla práctica, aunque las poblaciones con colas más pesadas necesitan \(n\) mayor).
Para muestras pequeñas de poblaciones no normales, considera alternativas no paramétricas como el intervalo de confianza bootstrap.
Distribución muestral y el IC
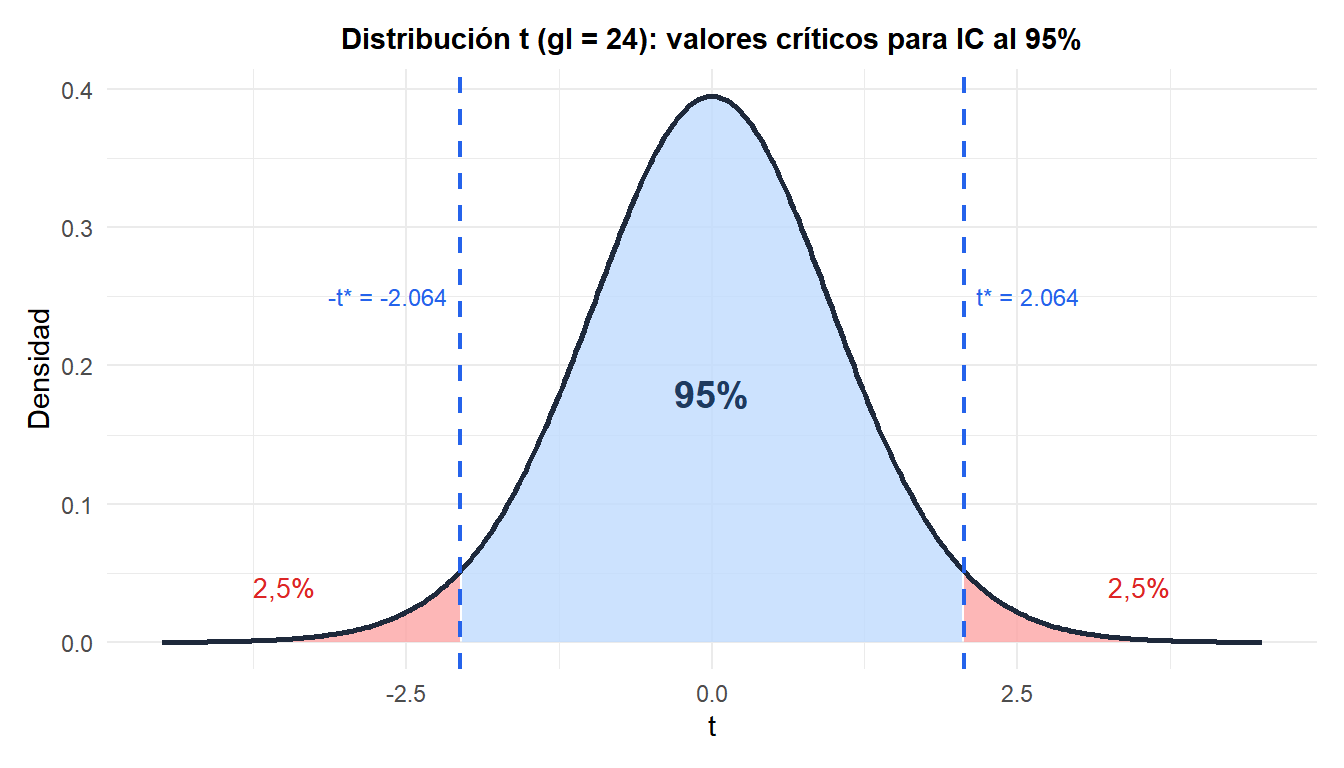
Ejemplos paso a paso
Ejemplo 1: estancia hospitalaria
Un hospital registra la estancia (días) de una muestra aleatoria de 25 pacientes: \(\bar{x} = 6{,}4\) días, \(S = 3{,}1\) días. Construye un IC al 95% para la media poblacional.
Paso 1: identifica los ingredientes.
\[n = 25, \quad \bar{x} = 6{,}4, \quad S = 3{,}1, \quad \alpha = 0{,}05\]
Paso 2: encuentra el valor crítico.
\[t_{0{,}025,\; 24} = 2{,}064\]
Paso 3: calcula el error estándar y el margen de error.
\[\text{EE} = \frac{3{,}1}{\sqrt{25}} = \frac{3{,}1}{5} = 0{,}62, \qquad \text{ME} = 2{,}064 \times 0{,}62 = 1{,}28\]
Paso 4: construye el intervalo.
\[\text{IC} = 6{,}4 \pm 1{,}28 = [5{,}12;\; 7{,}68] \text{ días}\]
Tenemos un 95% de confianza en que la estancia media real se sitúa entre 5,1 y 7,7 días.
Ejemplo 2: proceso de fabricación
Una fábrica muestrea 60 componentes y mide su resistencia a tracción. Resultados: \(\bar{x} = 248{,}3\) MPa, \(S = 12{,}7\) MPa. Construye un IC al 99%.
\[t_{0{,}005,\; 59} \approx 2{,}662\]
\[\text{ME} = 2{,}662 \times \frac{12{,}7}{\sqrt{60}} = 2{,}662 \times 1{,}640 = 4{,}37 \text{ MPa}\]
\[\text{IC} = 248{,}3 \pm 4{,}37 = [243{,}9;\; 252{,}7] \text{ MPa}\]
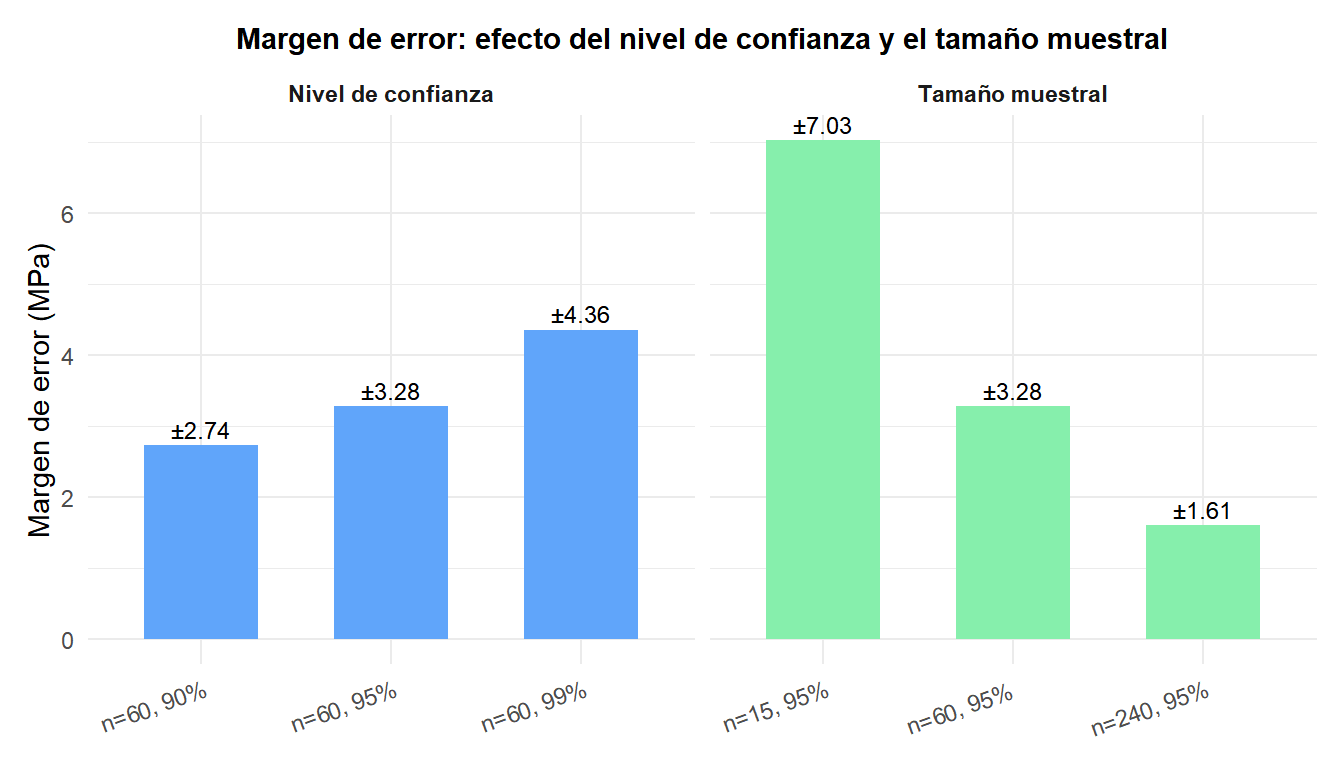
Con los mismos datos (\(S = 12{,}7\) MPa):
| Configuración | \(t^*\) | EE | Margen de error |
|---|---|---|---|
| \(n=60\), 90% | 1,671 | 1,64 | ±2,74 MPa |
| \(n=60\), 95% | 2,001 | 1,64 | ±3,28 MPa |
| \(n=60\), 99% | 2,662 | 1,64 | ±4,37 MPa |
| \(n=15\), 95% | 2,145 | 3,28 | ±7,04 MPa |
| \(n=60\), 95% | 2,001 | 1,64 | ±3,28 MPa |
| \(n=240\), 95% | 1,970 | 0,82 | ±1,62 MPa |
Cuadruplicar \(n\) de 15 a 60 reduce el margen de error a la mitad. Pasar del 95% al 99% de confianza añade aproximadamente 1 MPa.
💡 Guía práctica
- Informa el IC junto con la estimación puntual: “\(\bar{x} = 248{,}3\) MPa (IC al 95%: 243,9 a 252,7 MPa)”.
- Para planificar el tamaño muestral: decide el margen de error máximo aceptable \(d\) y luego resuelve \(n \approx (t^* S / d)^2\).
- Si los datos están muy sesgados y \(n\) es pequeño, el IC \(t\) puede no ser fiable. Considera una transformación logarítmica o un IC bootstrap.
- Los IC unilaterales (solo límite inferior o solo límite superior) usan \(t_{\alpha,\, n-1}\) en lugar de \(t_{\alpha/2,\, n-1}\).

