La moda en estadística
La moda es el valor que aparece con mayor frecuencia en un conjunto de datos. A diferencia de la media y la mediana, funciona con cualquier tipo de variable, incluidas las categorías, y es la única medida de tendencia central que tiene sentido para datos nominales.
Definición
La moda es el valor o valores que aparecen con mayor frecuencia en un conjunto de datos. Se representa habitualmente como \(Mo\).
Un conjunto de datos puede tener más de una moda si varios valores comparten la frecuencia más alta. Según el número de modas, la distribución se denomina:
- Unimodal: una sola moda.
- Bimodal: dos modas.
- Multimodal: más de dos modas.
Un conjunto de datos sin valores repetidos no tiene moda.
ℹ️ La moda y los tipos de variables
La moda es la única medida de tendencia central que puede usarse con todos los tipos de variables:
- Nominal: la categoría más frecuente (por ejemplo, el grupo sanguíneo más común en una muestra).
- Ordinal: el rango más frecuente (por ejemplo, la puntuación de satisfacción más habitual).
- Cuantitativa discreta: el recuento más frecuente (por ejemplo, el número de transacciones diarias más común).
- Cuantitativa continua: requiere estimar una función de densidad y encontrar su máximo.
Propiedades
La moda tiene las siguientes propiedades:
- Transformación lineal: si \(Y = aX + b\), entonces \(Mo(Y) = a \cdot Mo(X) + b\).
- Robustez: la moda no se ve afectada por los outliers. Un valor extremo no cambia cuál es el valor más frecuente.
- No unicidad: un conjunto de datos puede tener cero, una o varias modas.
- Aplicable a todos los tipos de variables: es la única medida de tendencia central que funciona con datos nominales.
⚠️ La moda no siempre está definida
Si ningún valor se repite en un conjunto de datos, no hay moda. Esto es habitual en muestras pequeñas de datos continuos, donde cada observación es ligeramente distinta. En ese caso hay que agrupar los datos en intervalos o estimar la densidad para encontrar la clase modal.
Ejemplos
Datos unimodales
En el vector \(x = (1, 5, 1, 2, 1, 6, 7, 1)\), el valor 1 aparece cuatro veces, más que cualquier otro. La moda es \(Mo(x) = 1\).
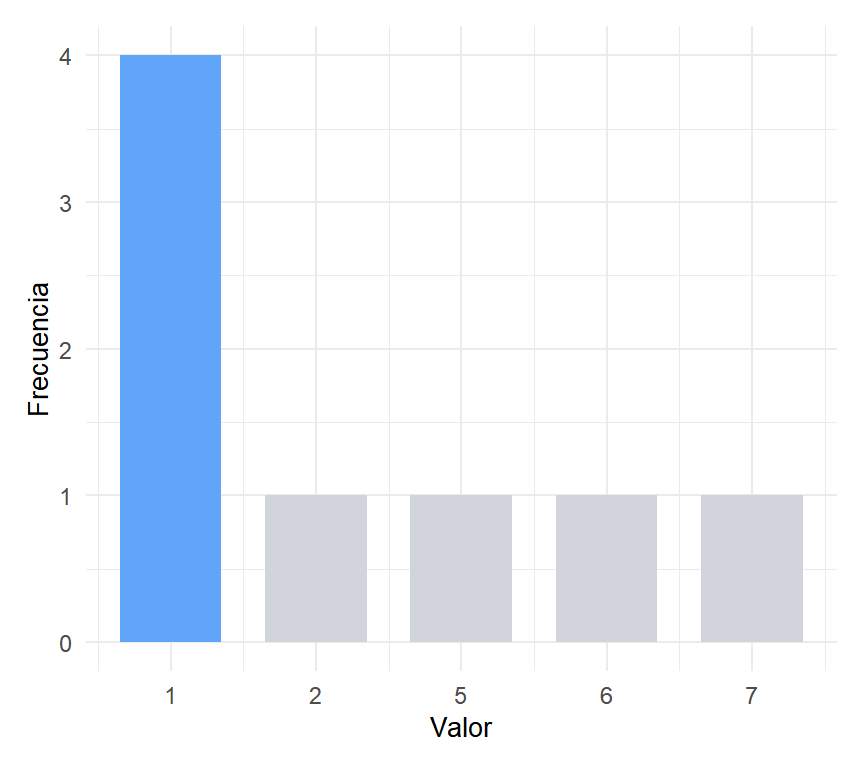
Figure 1: Distribución unimodal: el valor 1 es la moda (resaltado en azul)
Datos bimodales
En el vector \(x = (1, 5, 1, 5, 2, 1, 6, 7, 1, 5, 5)\), tanto el 1 como el 5 aparecen cuatro veces. El conjunto tiene dos modas: \(Mo(x) = \{1, 5\}\).
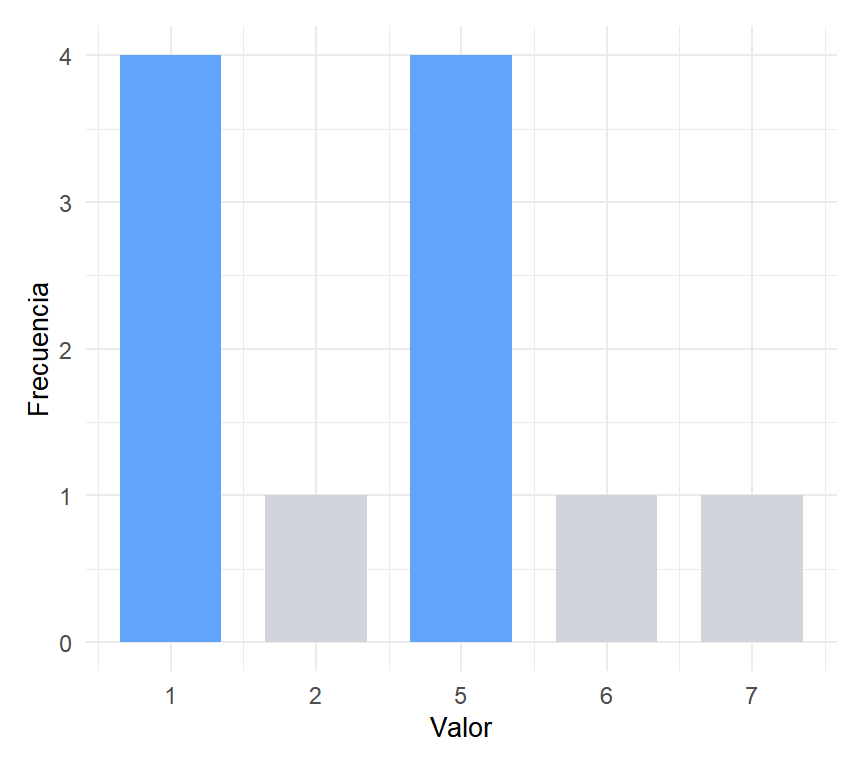
Figure 2: Distribución bimodal: los valores 1 y 5 comparten la frecuencia más alta
Modas con frecuencias distintas
En el vector \(x = (1, 5, 1, 5, 2, 1, 6, 7, 1, 5)\), el valor 1 aparece 4 veces y el 5 aparece 3 veces. En sentido estricto, la única moda es 1. Si reportar una o dos modas en casos límite depende del contexto y del objetivo del análisis.
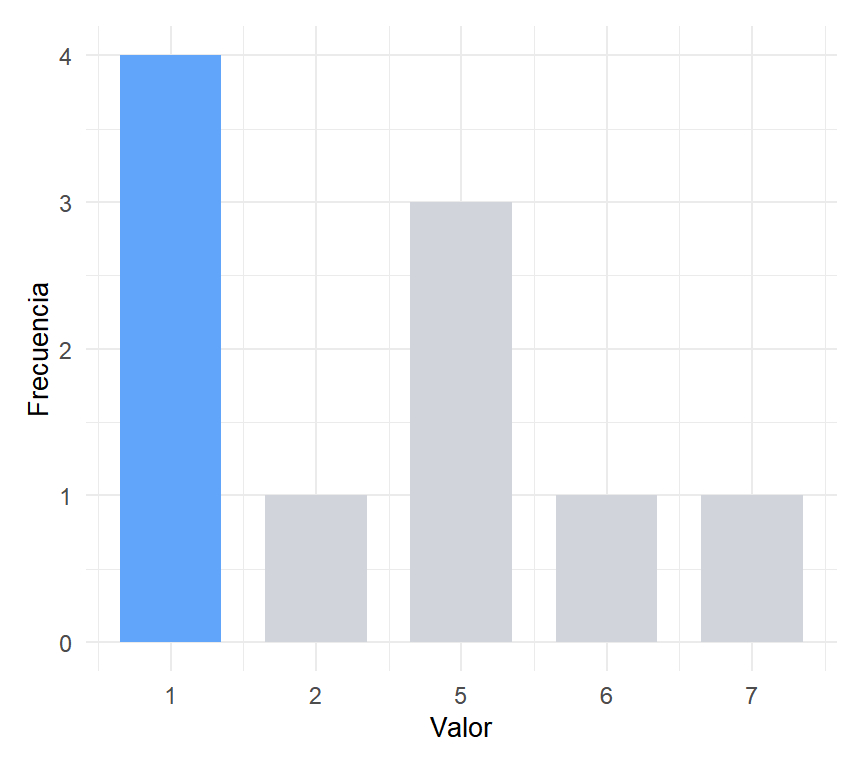
Figure 3: El valor 1 tiene una frecuencia mayor que el 5, por lo que en sentido estricto hay una sola moda
Un ejemplo real
La moda es especialmente útil cuando el “valor más común” importa más que el promedio. A un zapatero no le interesa la talla media de sus clientes, sino la moda: qué talla tiene que tener más en stock.
Una tienda de deporte registra las tallas vendidas en una semana:
\[x = (38, 40, 42, 40, 41, 42, 40, 43, 42, 40, 41, 42)\]
Contando frecuencias: la talla 40 aparece 4 veces, la talla 42 aparece 4 veces, el resto una o dos veces. El conjunto es bimodal: \(Mo(x) = \{40, 42\}\).
La talla media sería aproximadamente 41,1, que ni siquiera es una talla estándar. La moda es lo que la tienda necesita realmente para planificar el inventario.
Moda en datos continuos
Para variables continuas, los valores exactos rara vez se repiten, por lo que la moda se estima a partir de una curva de densidad. La moda es el valor en el que la densidad es máxima, que corresponde al pico de la distribución.
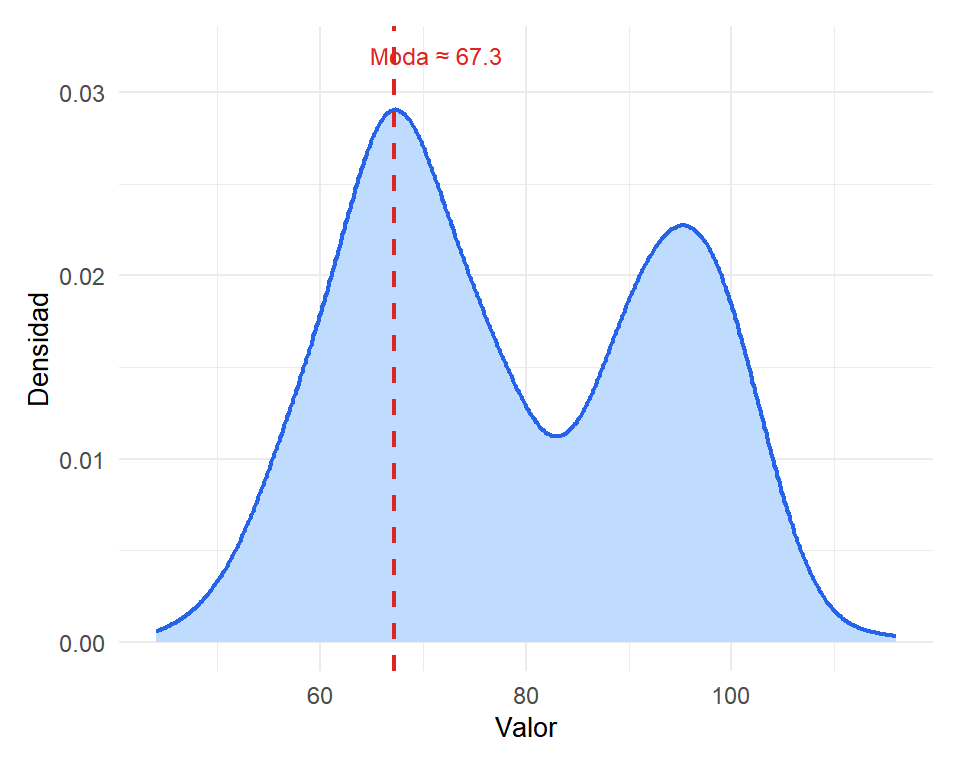
Figure 4: En datos continuos, la moda es el pico de la curva de densidad
💡 Las distribuciones bimodales suelen revelar subgrupos ocultos
Limitaciones de la moda
- No siempre está definida: si ningún valor se repite, no hay moda.
- No siempre es única: varias modas pueden dificultar la interpretación.
- Inestable en muestras pequeñas: añadir o eliminar una sola observación puede cambiar la moda por completo. Con pocos datos, la moda no es fiable.
- Poco informativa para datos continuos: sin agrupar los datos o estimar la densidad, cada valor puede ser único.
⚠️ No confundas la moda con la respuesta más común en una encuesta
En una encuesta con escala Likert (1 a 5), la moda es la respuesta más frecuente. Pero si el 40% responde 4 y el 35% responde 5, reportar solo la moda (4) oculta que la mayoría de los encuestados se sitúan en las dos categorías más altas. Observa siempre la distribución de frecuencias completa, no solo la moda.

