Distribución de Pareto
La distribución de Pareto modela fenómenos donde una pequeña fracción de las observaciones explica la mayor parte del efecto total. Es el fundamento matemático de la regla 80/20 y describe la riqueza, el tamaño de las ciudades, las magnitudes de los terremotos y el tráfico de internet, es decir, todos los contextos donde los eventos extremos son mucho más frecuentes de lo que predice la distribución normal.
Definición
Una variable aleatoria \(X\) sigue una distribución de Pareto con parámetro de escala \(x_m > 0\) (valor mínimo posible) y parámetro de forma \(\alpha > 0\) (índice de cola), escrita \(X \sim \text{Pareto}(x_m, \alpha)\), si:
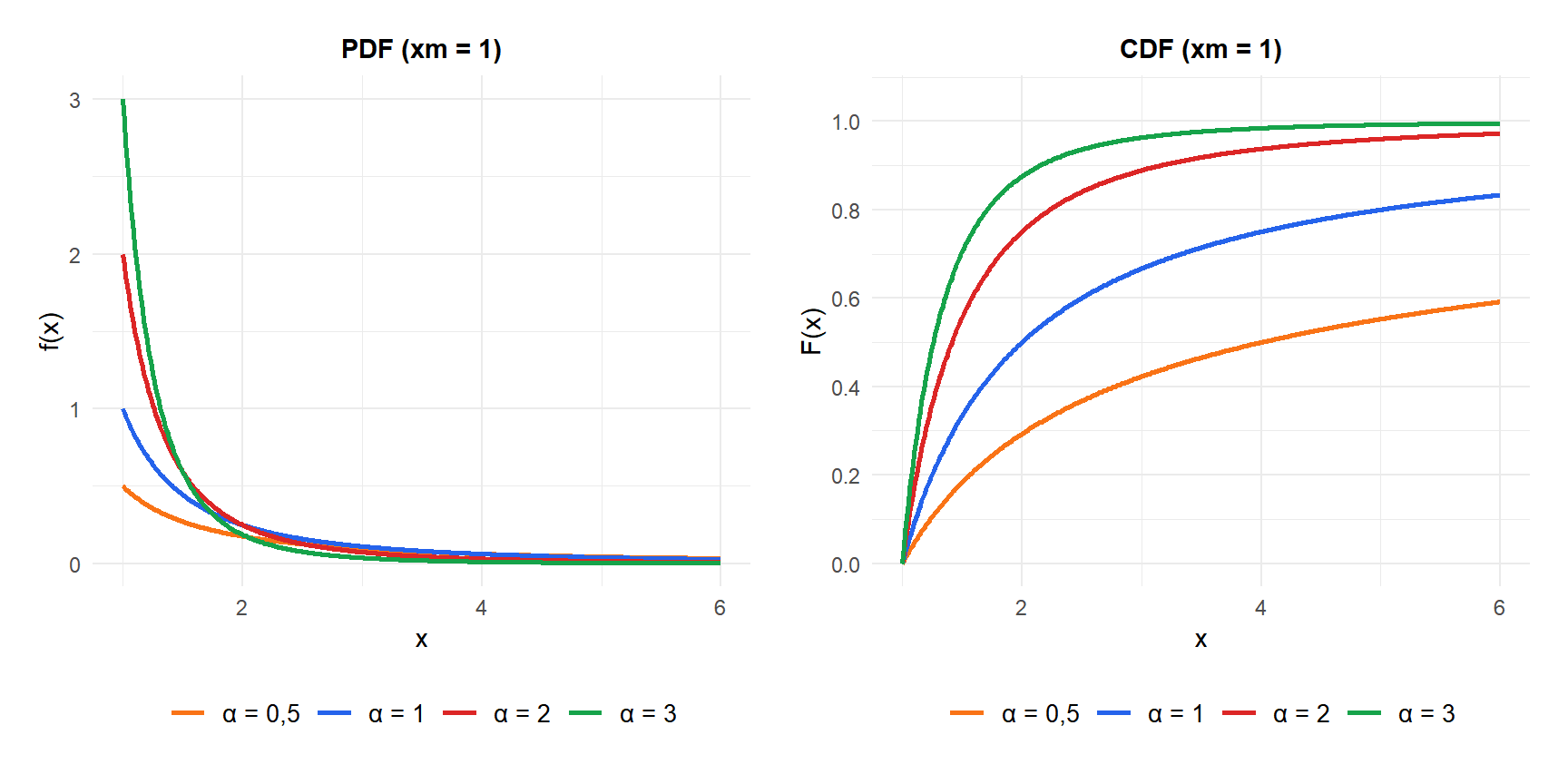
\[f(x) = \frac{\alpha\, x_m^\alpha}{x^{\alpha+1}}, \quad x \geq x_m\]
La CDF tiene una forma cerrada sencilla:
\[F(x) = 1 - \left(\frac{x_m}{x}\right)^\alpha, \quad x \geq x_m\]
La función de supervivencia \(P(X > x) = (x_m/x)^\alpha\) decrece siguiendo una ley potencial: dividir \(\alpha\) por dos eleva al cuadrado la probabilidad de superar cualquier umbral. Esto es lo que hace a la distribución de Pareto de “cola pesada”: la cola decrece mucho más lentamente que la exponencial \(e^{-\lambda x}\).
Propiedades
Para \(X \sim \text{Pareto}(x_m, \alpha)\):
- Valor esperado (media)
\[E(X) = \frac{\alpha\, x_m}{\alpha - 1}, \quad \text{solo definida para } \alpha > 1\]
Para \(\alpha \leq 1\), la media es infinita.
- Varianza
\[\text{Var}(X) = \frac{\alpha\, x_m^2}{(\alpha-1)^2(\alpha-2)}, \quad \text{solo definida para } \alpha > 2\]
Para \(1 < \alpha \leq 2\), la media existe pero la varianza es infinita.
- Asimetría
\[\text{Asimetría} = \frac{2(1+\alpha)}{\alpha - 3}\sqrt{\frac{\alpha-2}{\alpha}}, \quad \text{para } \alpha > 3\]
No definida para \(\alpha \leq 3\). Siempre positiva (asimetría a la derecha).
- Curtosis
\[g_2 = \frac{6(\alpha^3 + \alpha^2 - 6\alpha - 2)}{\alpha(\alpha-3)(\alpha-4)}, \quad \text{para } \alpha > 4\]
- Mediana
\[\text{Mediana} = x_m \cdot 2^{1/\alpha}\]
- Moda
\[\text{Moda} = x_m\]
La distribución es siempre decreciente: el valor más probable es el mínimo \(x_m\).
- Función cuantil
\[Q(p) = \frac{x_m}{(1-p)^{1/\alpha}}\]
⚠️ La media y la varianza pueden no existir
La distribución de Pareto es peculiar porque sus momentos pueden no existir:
- \(\alpha \leq 1\): la media es infinita. Las medias calculadas sobre muestras crecerán sin límite a medida que \(n\) aumenta.
- \(1 < \alpha \leq 2\): la media existe pero la varianza es infinita. La varianza muestral seguirá creciendo con el tamaño de la muestra.
- \(\alpha > 2\): tanto la media como la varianza existen.
En la práctica, el \(\alpha\) para distribuciones de riqueza se estima habitualmente en torno a 1,5, lo que significa que la riqueza tiene una media finita pero varianza infinita. Por eso “la riqueza media” puede ser un estadístico engañoso.
La regla 80/20
El principio de Pareto establece que aproximadamente el 80% de los efectos proviene del 20% de las causas. No es una ley de la naturaleza, sino una consecuencia de la distribución de Pareto cuando \(\alpha = \log(5)/\log(4) \approx 1{,}161\).
En general, la fracción de la población \(p\) que representa la fracción \(F\) del total (para una cantidad distribuida según Pareto con \(\alpha > 1\)) es:
\[F = 1 - \left(\frac{x_m}{Q(1-p)}\right)^{\alpha-1} = 1 - (1-p)^{(\alpha-1)/\alpha}\]
Para \(\alpha = 1{,}161\) (el exponente de Pareto exacto de la regla 80/20):
- El 20% más rico posee el 80% de los ingresos totales.
- El 4% más rico posee el 64% (\(0{,}2^2 = 0{,}04\), \(0{,}8^2 = 0{,}64\)).
- El 1% más rico posee aproximadamente el 55% de los ingresos totales.
Estas cifras no son coincidencias: se derivan directamente de la estructura de ley potencial de la distribución de Pareto.
Ejemplo paso a paso
Las reclamaciones de seguros por encima de un umbral mínimo de 10.000 USD siguen una distribución de Pareto con \(x_m = 10{.}000\) y \(\alpha = 2{,}5\).
Importe esperado de la reclamación:
\[E(X) = \frac{2{,}5 \times 10{.}000}{2{,}5 - 1} = \frac{25{.}000}{1{,}5} \approx 16{.}667 \text{ USD}\]
Probabilidad de que una reclamación supere los 50.000 USD:
\[P(X > 50{.}000) = \left(\frac{10{.}000}{50{.}000}\right)^{2{,}5} = (0{,}2)^{2{,}5} \approx 0{,}0179\]
Aproximadamente el 1,8% de las reclamaciones superan los 50.000 USD.
Percentil 90 (reclamaciones que solo supera el 10% de las pólizas):
\[Q(0{,}90) = \frac{10{.}000}{(1-0{,}90)^{1/2{,}5}} = \frac{10{.}000}{0{,}1^{0{,}4}} \approx \frac{10{.}000}{0{,}251} \approx 39{.}800 \text{ USD}\]
Varianza:
\[\text{Var}(X) = \frac{2{,}5 \times 10{.}000^2}{(1{,}5)^2 \times (0{,}5)} = \frac{250{.}000{.}000}{1{,}125} \approx 222{.}222{.}222 \text{ USD}^2\]
Desviación típica \(\approx 14{.}907\) USD, casi tan grande como la media.
⚠️ Colas de ley potencial vs colas exponenciales
La diferencia clave entre la distribución de Pareto y distribuciones como la exponencial o la normal es la velocidad a la que decrece la cola:
- Cola exponencial: \(P(X > x) = e^{-\lambda x}\). Decrece extremadamente rápido. Duplicar \(x\) reduce la probabilidad de la cola de forma drástica.
- Cola de ley potencial: \(P(X > x) = (x_m/x)^\alpha\). Decrece lentamente. Un terremoto 10 veces mayor es solo \(10^\alpha\) veces más raro, no exponencialmente más raro.
Por eso existen las inundaciones centenarias, las pérdidas de seguros de miles de millones y las publicaciones virales en redes sociales: los modelos de cola exponencial los predecirían como esencialmente imposibles, pero los modelos de ley potencial les asignan una probabilidad no despreciable.
💡 Relación con otras distribuciones
- Exponencial: la Pareto tiene cola de ley potencial en lugar de cola exponencial, lo que la hace mucho más pesada.
- Lomax (Pareto tipo II): \(Y = X - x_m\) donde \(X \sim \text{Pareto}(x_m, \alpha)\) da una distribución Lomax que comienza en 0.
- Log-uniforme: si \(\ln(X)\) es uniforme en \((\ln x_m, \infty)\), \(X\) es Pareto.
- Pareto generalizada: usada en la teoría de valores extremos para modelar los excesos por encima de un umbral, generalizando la Pareto estándar.

