Distribución geométrica
La distribución geométrica modela el tiempo de espera hasta el primer éxito en una secuencia de ensayos de Bernoulli independientes. Es la única distribución discreta con la propiedad de pérdida de memoria: los fracasos pasados no aportan ninguna información sobre los resultados futuros.
Definición
Existen dos versiones habituales de la distribución geométrica. Ambas describen el mismo proceso pero cuentan cosas distintas:
Versión 1: número de ensayos hasta el primer éxito (\(X \geq 1\)):
\[P(X = k) = (1-p)^{k-1} p, \quad k = 1, 2, 3, \ldots\]
Versión 2: número de fracasos antes del primer éxito (\(X \geq 0\)):
\[P(X = k) = (1-p)^{k} p, \quad k = 0, 1, 2, \ldots\]
Ambas reciben el nombre de “distribución geométrica”. La versión 2 es un caso particular de la binomial negativa con \(r = 1\).
⚠️ ¿Qué parametrización usa tu software?
La función dgeom(x, prob = p) de R usa la versión 2: \(x\) es el número de fracasos antes del primer éxito. Así, dgeom(0, p) da \(P(X=0) = p\), la probabilidad de éxito en el primer ensayo.
Si quieres la versión 1 (número de ensayos), usa dgeom(x - 1, prob = p) o, equivalentemente, observa que si \(Y\) es la versión 2, entonces \(X = Y + 1\) es la versión 1.
Esta diferencia de uno en uno es una fuente frecuente de errores en cálculos de exámenes y en código.
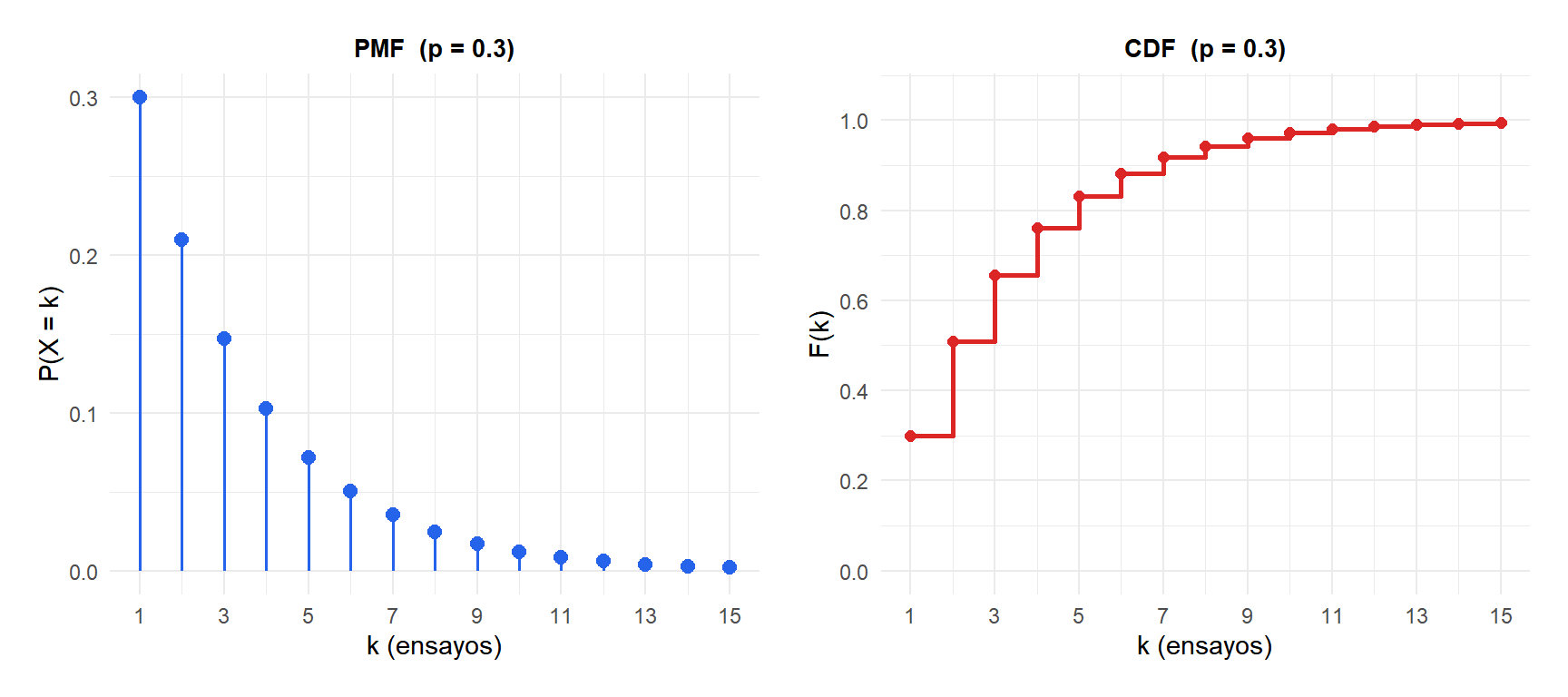
Función de masa de probabilidad y CDF
Usando la versión 1 (\(k\) = número de ensayos), la CDF tiene una forma cerrada sencilla:
\[F(k) = P(X \leq k) = 1 - (1-p)^k\]
Esto significa que la probabilidad de necesitar más de \(k\) ensayos es simplemente \((1-p)^k\).
Propiedades
Para \(X \sim \text{Geométrica}(p)\) usando la versión 1 (número de ensayos):
- Valor esperado (media)
\[E(X) = \frac{1}{p}\]
Si la probabilidad de éxito es del 20%, se necesitan de media 5 ensayos para obtener el primer éxito.
- Varianza
\[\text{Var}(X) = \frac{1-p}{p^2}\]
- Asimetría
\[\text{Asimetría} = \frac{2-p}{\sqrt{1-p}}\]
Siempre positiva: la distribución tiene una cola derecha larga independientemente de \(p\).
- Curtosis
\[g_2 = 6 + \frac{p^2}{1-p}\]
- CDF (forma cerrada)
\[F(k) = 1 - (1-p)^k\]
- Función cuantil
\[Q(u) = \left\lceil \frac{\log(1-u)}{\log(1-p)} \right\rceil\]
donde \(\lceil \cdot \rceil\) es la función techo.
La propiedad de pérdida de memoria
La distribución geométrica es la única distribución discreta con la propiedad de pérdida de memoria:
\[P(X > m + n \mid X > m) = P(X > n)\]
Esto significa: si ya has fallado \(m\) veces, la probabilidad de necesitar más de \(n\) ensayos adicionales es exactamente la misma que si empezaras de cero. Los fracasos pasados no aportan ninguna información sobre los resultados futuros.
Un inspector de calidad prueba componentes uno a uno. Cada uno tiene una tasa de defectos del 10%. El inspector ya ha probado 20 componentes sin encontrar ningún defecto.
¿Cuál es la probabilidad de necesitar más de 5 pruebas adicionales?
Por la propiedad de pérdida de memoria: \(P(X > 5) = (1 - 0{,}1)^5 = 0{,}9^5 \approx 0{,}590\).
Las 20 pruebas anteriores son completamente irrelevantes. La distribución geométrica no tiene memoria de los fracasos pasados.
⚠️ La propiedad de pérdida de memoria puede ser contraintuitiva
Muchos estudiantes esperan que, después de muchos fracasos, el éxito esté “pendiente”. Esta intuición es incorrecta para los procesos geométricos. Una moneda equilibrada no tiene memoria: después de 10 caras seguidas, la probabilidad de cruz en el siguiente lanzamiento sigue siendo 0,5. La falacia del jugador es exactamente la creencia de que los procesos geométricos (sin memoria) sí tienen memoria.
Ejemplo paso a paso
Un centro de datos sufre fallos de servidor que requieren un reinicio. Cada intento de reinicio tiene éxito con probabilidad \(p = 0{,}4\). Sea \(X\) = número de intentos hasta el primer reinicio exitoso, \(X \sim \text{Geométrica}(0{,}4)\).
Probabilidad de éxito exactamente en el 3.er intento:
\[P(X = 3) = (1-0{,}4)^{3-1} \times 0{,}4 = 0{,}6^2 \times 0{,}4 = 0{,}36 \times 0{,}4 = 0{,}144\]
Número esperado de intentos:
\[E(X) = \frac{1}{0{,}4} = 2{,}5 \text{ intentos}\]
Probabilidad de necesitar más de 4 intentos:
\[P(X > 4) = (1-0{,}4)^4 = 0{,}6^4 = 0{,}1296\]
Aproximadamente el 13% de los fallos requerirán más de 4 intentos de reinicio.
Probabilidad de éxito en los primeros 3 intentos:
\[F(3) = 1 - (1-0{,}4)^3 = 1 - 0{,}216 = 0{,}784\]
Casi el 78% de los fallos se resuelven en 3 intentos.
- Test A/B: una nueva variante de anuncio tiene una tasa de clics del 5%. Número esperado de impresiones antes del primer clic: \(E(X) = 1/0{,}05 = 20\).
- Entrevistas de trabajo: un candidato supera cada fase con probabilidad 0,3. Probabilidad de pasar en el primer intento: \(P(X=1) = 0{,}3\). Número esperado de intentos: \(1/0{,}3 \approx 3{,}3\).
- Retransmisión en red: un paquete de datos se entrega con éxito con probabilidad 0,95 por intento. Probabilidad de necesitar más de 2 intentos: \((1-0{,}95)^2 = 0{,}0025\).
💡 Relación con otras distribuciones
- Binomial negativa: Geométrica\((p)\) = NegBin\((1, p)\). La geométrica es el caso especial con \(r = 1\).
- Exponencial: el análogo continuo de la distribución geométrica. Ambas son sin memoria: la geométrica para ensayos discretos, la exponencial para tiempo continuo.
- Binomial: si realizas \(n\) ensayos geométricos y cuentas los éxitos, obtienes una binomial. La geométrica pregunta “¿cuándo es el primer éxito?”; la binomial pregunta “¿cuántos éxitos en \(n\) ensayos?”.

