Validación cruzada
La validación cruzada estima cómo funcionará un modelo con datos nuevos y no vistos, particionando repetidamente los datos disponibles en conjuntos de entrenamiento y validación. Es la herramienta estándar para evaluación de modelos, selección de hiperparámetros y comparación de modelos en competencia. Usarla incorrectamente produce estimaciones optimistas que no generalizan.
Por qué una única división entrenamiento/prueba no es suficiente
Dividir los datos una sola vez en conjuntos de entrenamiento y prueba es sencillo pero ruidoso: el rendimiento estimado depende en gran medida de qué observaciones acaban en cada conjunto. Con \(n=200\) y una división 80/20, el conjunto de prueba tiene solo 40 observaciones: el error estimado tiene alta varianza entre diferentes divisiones aleatorias.
La validación cruzada aborda esto usando múltiples divisiones y promediando los resultados. La estimación es más estable, y obtenemos una medida de su incertidumbre (desviación típica entre pliegues).
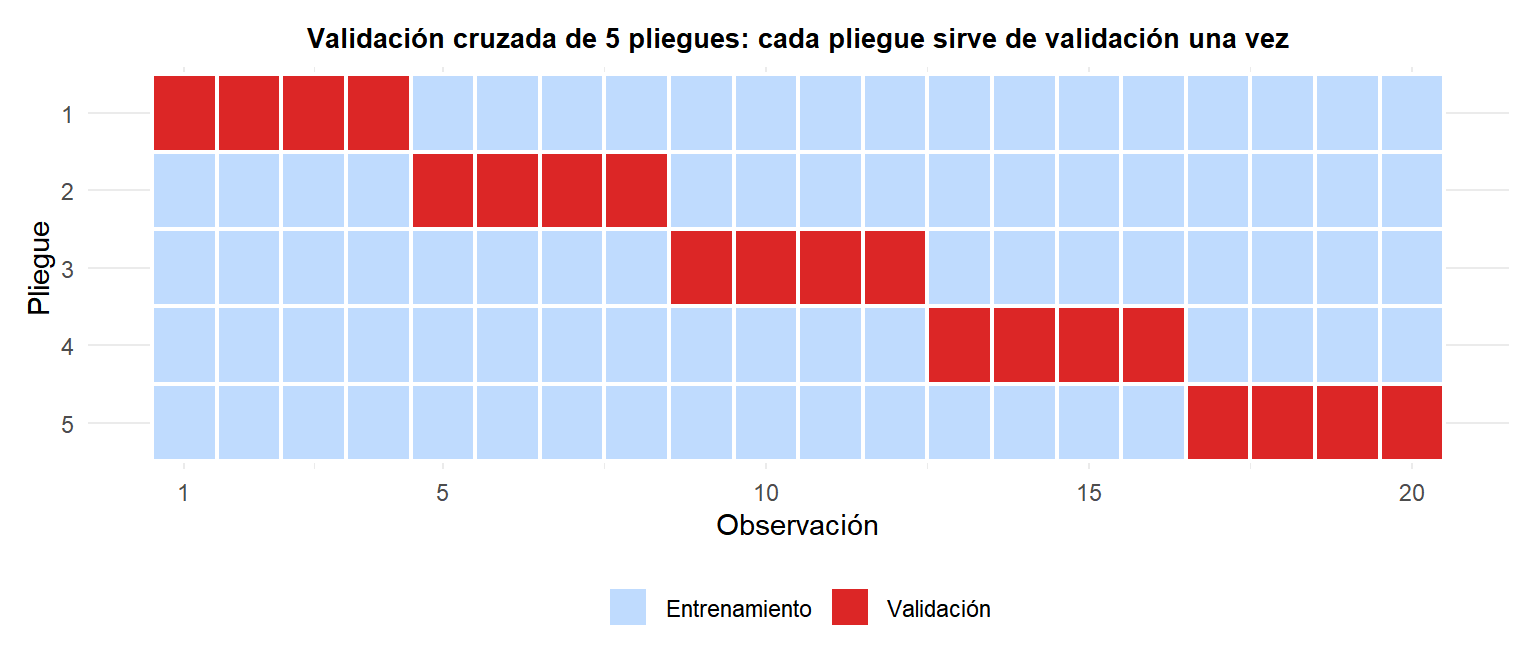
Validación cruzada k-fold
Particiona los datos aleatoriamente en \(k\) pliegues de tamaño aproximadamente igual. Para cada pliegue \(i = 1, \ldots, k\):
- Entrena el modelo en los otros \(k-1\) pliegues.
- Evalúa en el pliegue \(i\), registrando la métrica (p.ej., MSE, precisión).
La estimación VC es la media de los \(k\) pliegues:
\[\widehat{\text{VC}}_k = \frac{1}{k}\sum_{i=1}^k \text{error}_i\]
\[\widehat{\text{EE}} = \sqrt{\frac{1}{k(k-1)}\sum_{i=1}^k(\text{error}_i - \widehat{\text{VC}}_k)^2}\]
El error estándar \(\widehat{\text{EE}}\) cuantifica la incertidumbre de la estimación VC. La regla de un error estándar: al comparar modelos, elige el modelo más simple cuyo error VC esté dentro de un EE del mínimo. Esto prefiere la parsimonia sin sacrificar mucha precisión.
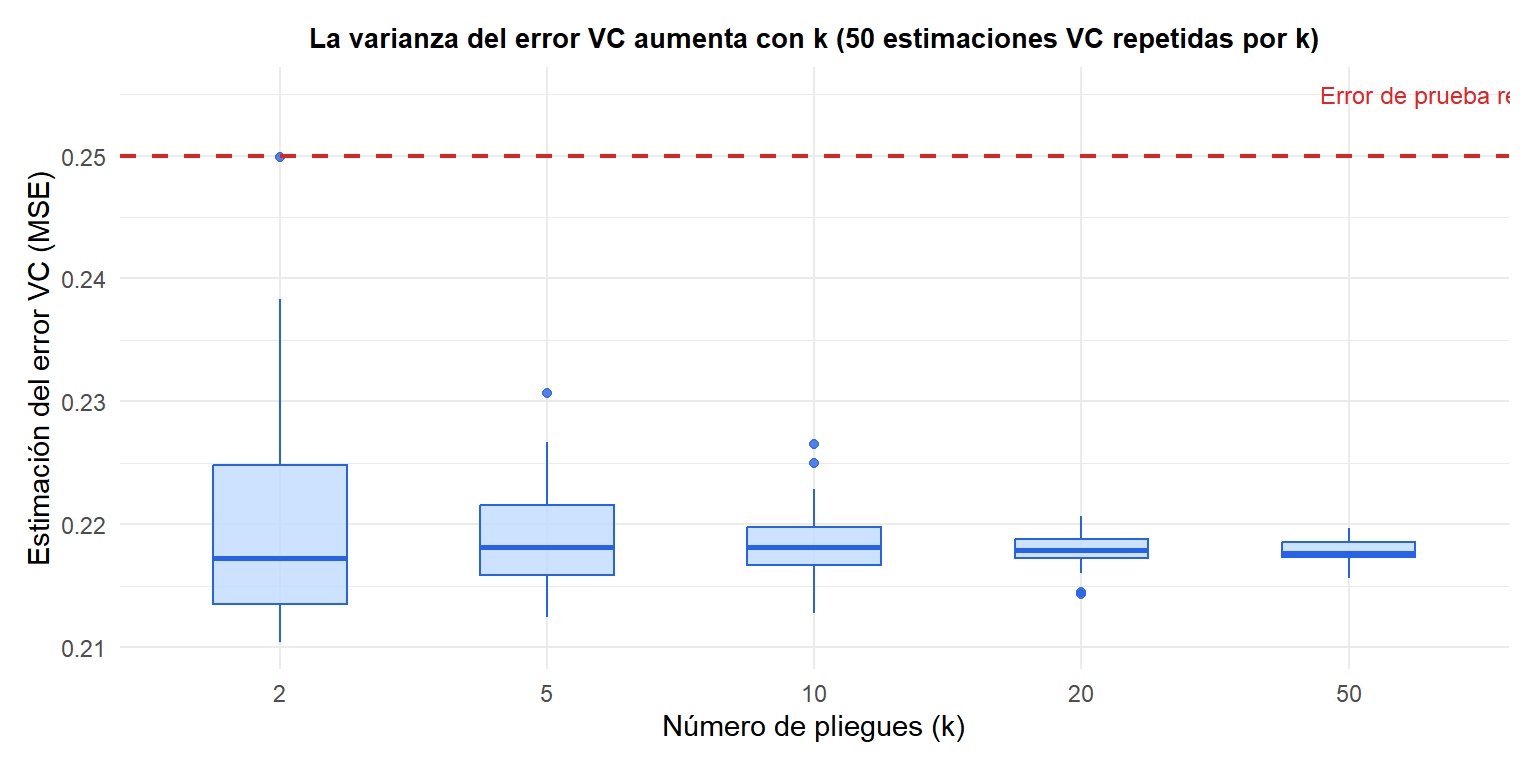
Elegir k: el compromiso sesgo-varianza
La elección de \(k\) controla un compromiso sesgo-varianza en la propia estimación VC:
- \(k\) grande (p.ej., LOOCV): los conjuntos de entrenamiento son cercanos al tamaño \(n\) (sesgo bajo). Pero los \(k\) conjuntos de validación son casi idénticos (los modelos entrenados en ellos están altamente correlacionados), por lo que la varianza de la estimación VC es alta.
- \(k\) pequeño (p.ej., \(k=2\)): los conjuntos de entrenamiento tienen solo \(n/2\) observaciones (sesgo alto: el modelo es más débil que con los datos completos). Varianza baja.
- \(k=5\) o \(k=10\): se ha demostrado empíricamente que dan un buen equilibrio sesgo-varianza. La elección estándar.
LOOCV (\(k=n\)) tiene una propiedad especial: para modelos lineales, existe una fórmula abreviada que calcula el LOOCV sin reajustar \(n\) veces:
\[\text{LOOCV} = \frac{1}{n}\sum_{i=1}^n \left(\frac{y_i - \hat{y}_i}{1 - h_{ii}}\right)^2\]
donde \(h_{ii}\) es el apalancamiento de la observación \(i\). Esto hace el LOOCV práctico para modelos lineales, pero sigue teniendo alta varianza como estimador.
Variantes de la validación cruzada
K-fold estratificada
Para clasificación con clases desequilibradas, asegura que cada pliegue tenga las mismas proporciones de clases que el conjunto completo. Sin estratificación, un pliegue puede contener muy pocos ejemplos de la clase minoritaria, haciendo la estimación del error ruidosa y no representativa. Usa siempre VC estratificada para clasificación.
K-fold repetida
Repite la VC \(k\)-fold \(r\) veces con diferentes particiones aleatorias. Promedia sobre los \(r \times k\) pliegues. Da estimaciones más estables al coste de \(r\) veces más computación. Útil cuando \(n\) es pequeño.
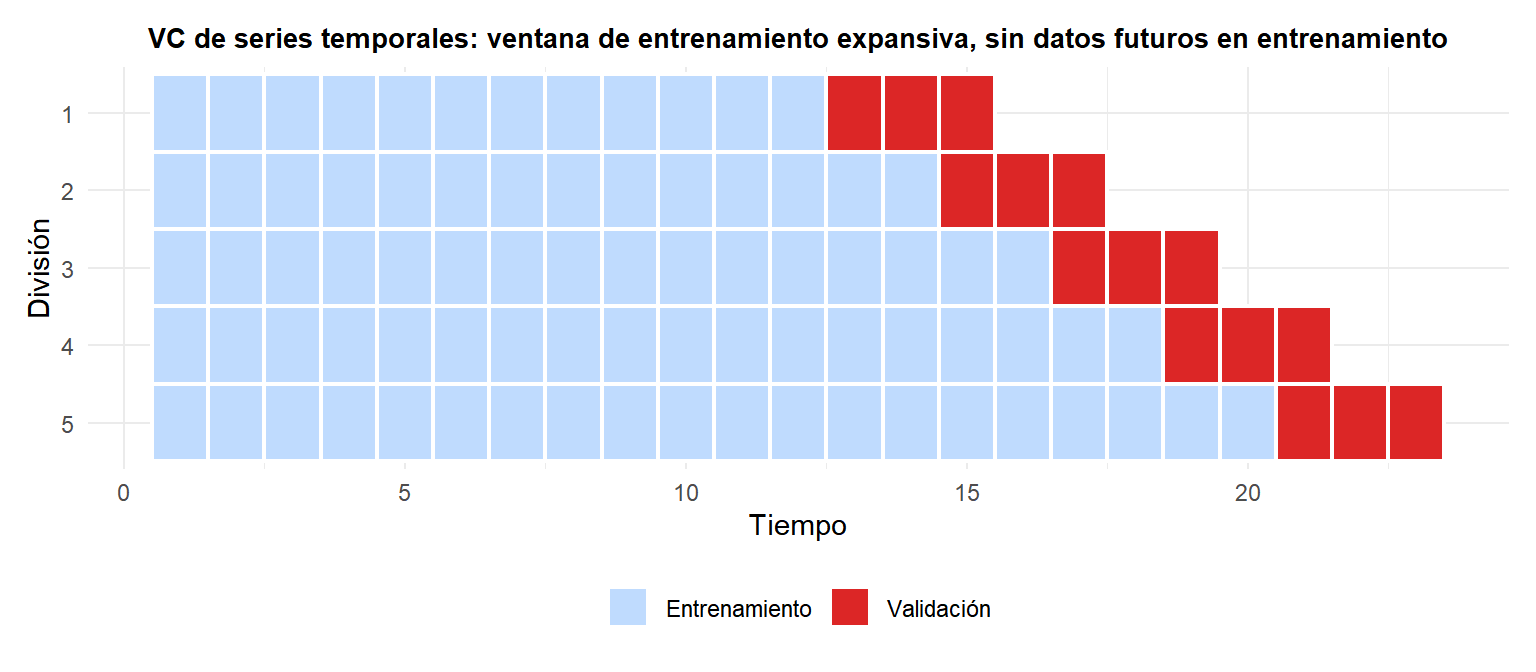
VC para series temporales (validación hacia adelante)
La VC \(k\)-fold estándar mezcla aleatoriamente los datos, creando pliegues de entrenamiento que contienen observaciones futuras. Para series temporales esto es fuga de datos: el modelo “ve el futuro” durante el entrenamiento.
La VC para series temporales usa ventanas expansivas o deslizantes: entrena en las observaciones \(1, \ldots, t\) y evalúa en \(t+1, \ldots, t+h\) para valores crecientes de \(t\).
Validación cruzada anidada: evitar la fuga de datos
Un error habitual: usar VC para seleccionar hiperparámetros y luego reportar ese mismo error VC como estimación del rendimiento del modelo. Esto es optimista porque los pliegues de prueba influyeron en la selección de hiperparámetros.
La VC anidada usa dos bucles:
- Bucle externo: \(k_\text{externo}\) pliegues para estimación de rendimiento sin sesgo.
- Bucle interno: para cada conjunto de entrenamiento externo, ejecuta VC \(k_\text{interno}\)-fold para seleccionar hiperparámetros.
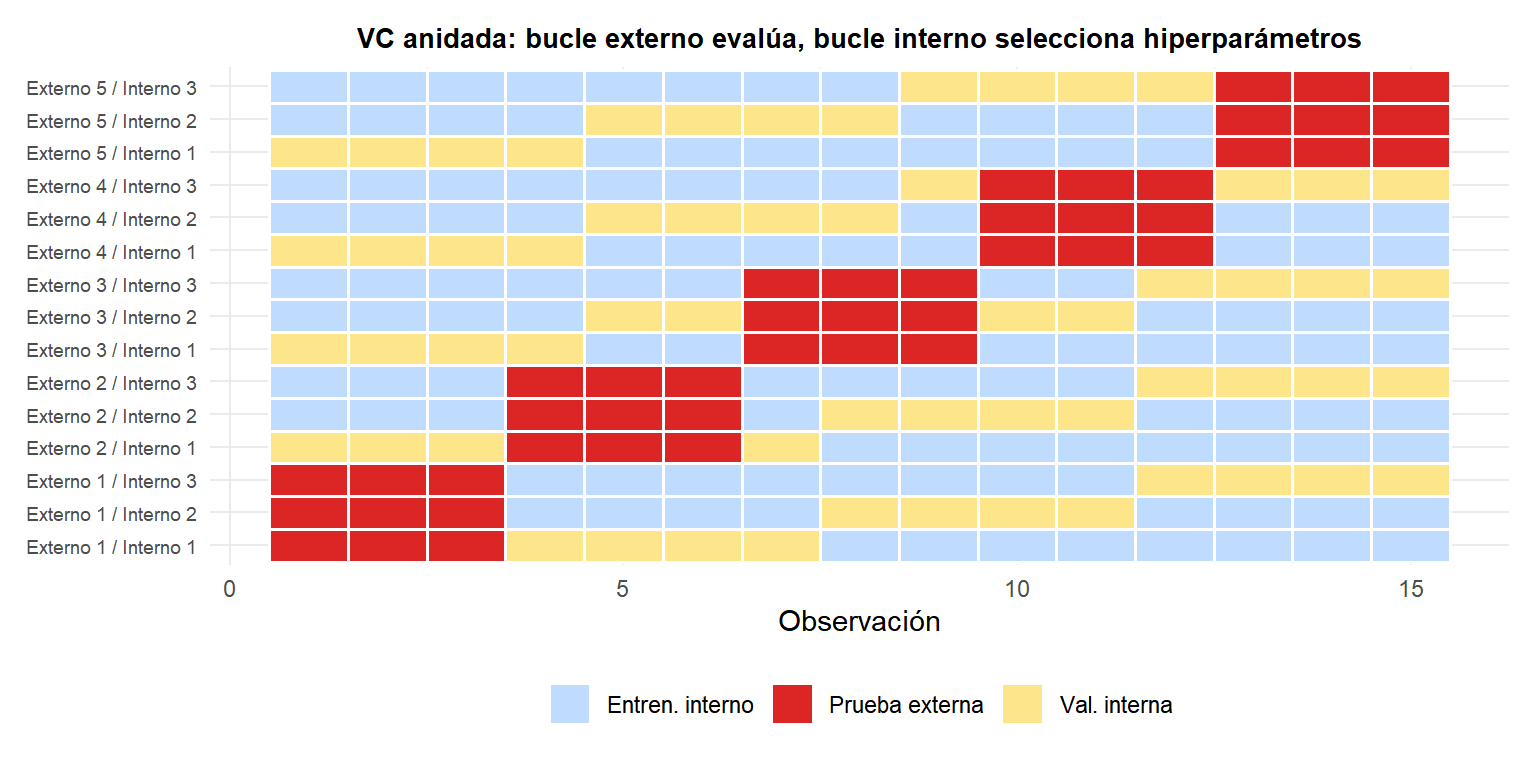
Los pliegues de prueba externos (rojo) nunca se ven durante la selección de hiperparámetros. Los pliegues de validación internos (amarillo) se usan para seleccionar los mejores hiperparámetros para cada conjunto de entrenamiento del pliegue externo. El error VC externo es una estimación sin sesgo del rendimiento del modelo final.
⚠️ Usar el error VC para selección de modelos y para reportar es usar los datos dos veces
Si usas VC para seleccionar entre 50 modelos y reportas el error VC del ganador, el error reportado es optimista: buscaste entre 50 modelos y elegiste el más afortunado. Cuantos más modelos compares, mayor es el optimismo.
Procedimiento correcto: usa VC anidada, o reserva un conjunto de prueba final que nunca se usa para ninguna decisión de selección de modelos (sin ajuste de hiperparámetros, sin selección de variables, sin comparación de modelos). El conjunto de prueba final se usa exactamente una vez, al final, para reportar el rendimiento definitivo.
💡 Validación cruzada en R
library(caret)
# VC de 10 pliegues
ctrl <- trainControl(method="cv", number=10)
fit <- train(y ~ ., data=df, method="glm", trControl=ctrl)
fit$results # métricas VC por pliegue
fit$resample # resultados individuales por pliegue
# K-fold estratificada para clasificación
ctrl_strat <- trainControl(method="cv", number=10,
classProbs=TRUE, summaryFunction=twoClassSummary)
# 10-fold repetida
ctrl_rep <- trainControl(method="repeatedcv", number=10, repeats=5)
# VC anidada
library(mlr3)
library(mlr3tuning)
task <- as_task_classif(df, target="y")
learner <- lrn("classif.ranger", predict_type="prob")
resampling_outer <- rsmp("cv", folds=5)
resampling_inner <- rsmp("cv", folds=3)
measure <- msr("classif.auc")
tuner <- tnr("grid_search")
at <- AutoTuner$new(learner, resampling_inner, measure, tuner=tuner,
terminator=trm("evals", n_evals=20))
rr <- resample(task, at, resampling_outer)
rr$aggregate(measure) # estimación de rendimiento sin sesgo
