Splines de regresión
Los splines de regresión ajustan funciones no lineales mediante polinomios a trozos que se unen suavemente en puntos llamados nodos. Son más estables que los polinomios globales de alto grado: evitan el comportamiento oscilatorio en los extremos (fenómeno de Runge) y permiten que la forma de la curva varíe localmente.
Polinomios a trozos y nodos
Dado un conjunto de \(K\) nodos \(\xi_1 < \xi_2 < \cdots < \xi_K\) en el dominio de \(x\), un spline de grado \(d\) ajusta un polinomio de grado \(d\) en cada intervalo \((-\infty, \xi_1), [\xi_1, \xi_2), \ldots, [\xi_K, \infty)\) con la restricción de que los polinomios sean continuos hasta la derivada \((d-1)\)-ésima en cada nodo.
Para el caso más habitual, \(d=3\) (splines cúbicos): son continuos hasta la segunda derivada, lo que significa que la curva parece visualmente suave sin oscilaciones bruscas.
Un spline cúbico con \(K\) nodos tiene \(4(K+1)\) parámetros libres menos \(3K\) restricciones de continuidad en los nodos, resultando en \(K + 4\) grados de libertad. Puede representarse mediante funciones de base truncadas:
\[1, x, x^2, x^3, (x-\xi_1)_+^3, \ldots, (x-\xi_K)_+^3\]
donde \((x-\xi_k)_+^3 = \max(0, x-\xi_k)^3\). Esta base permite ajustar el spline con lm() usando predictores estándar.
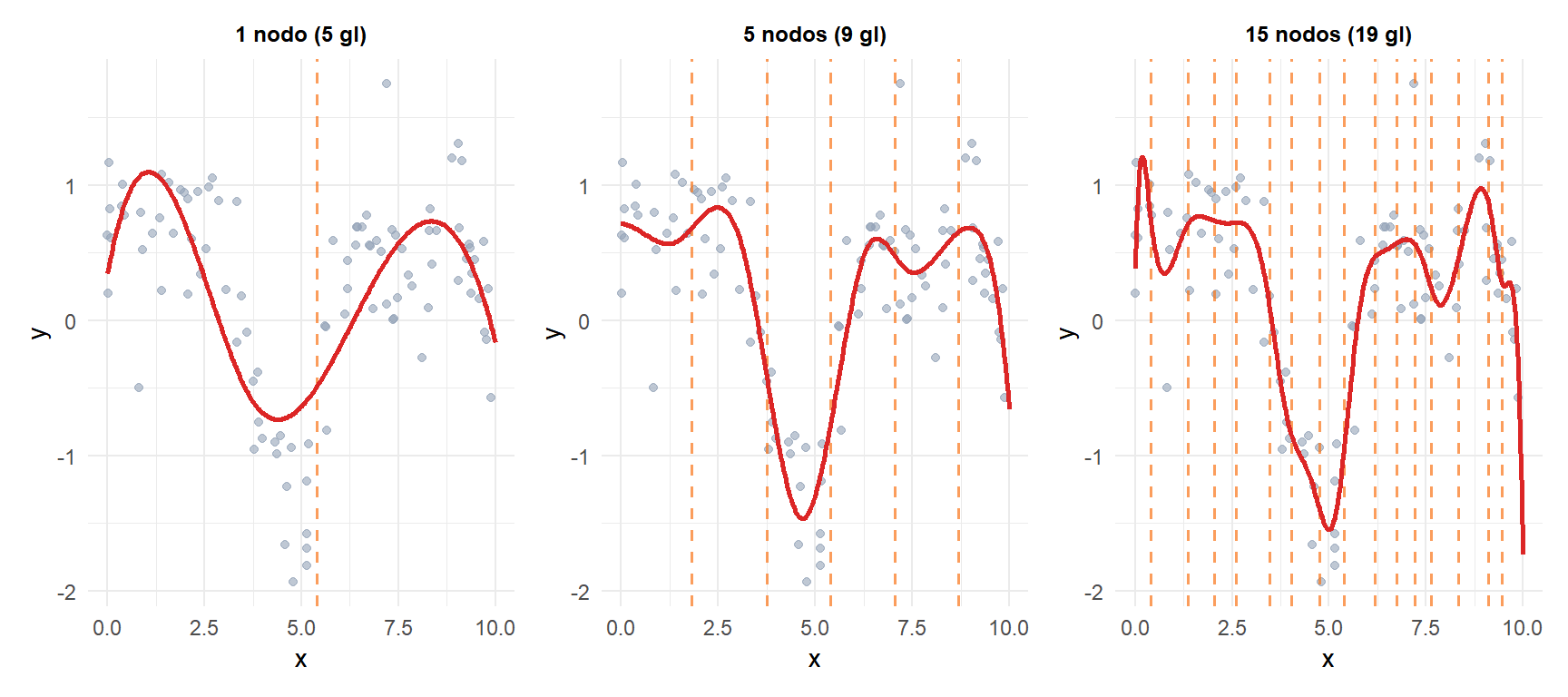
Con pocos nodos la curva es demasiado rígida. Con muchos, el ajuste oscila. La línea naranja vertical marca la posición de los nodos.
Splines cúbicos naturales
Los splines cúbicos ordinarios oscilan en los extremos del dominio. Los splines cúbicos naturales (SCN) añaden la restricción de que la segunda derivada sea cero más allá del primer y el último nodo, forzando linealidad en las colas. Esto reduce la varianza en los extremos donde los datos son más escasos.
Un SCN con \(K\) nodos tiene \(K\) grados de libertad (en lugar de \(K+4\)). Tiene mejor comportamiento en los extremos y es el tipo de spline más usado en la práctica. En R, ns() de la librería splines ajusta SCN.
Splines de suavizado
En lugar de fijar los nodos previamente, los splines de suavizado colocan un nodo en cada observación y controlan la flexibilidad mediante un parámetro de penalización \(\lambda\):
\[\hat{f} = \arg\min_f \left\{\sum_{i=1}^n (y_i - f(x_i))^2 + \lambda \int [f''(x)]^2 dx\right\}\]
La solución es un spline cúbico natural con nodos en cada \(x_i\). El parámetro \(\lambda\) controla el equilibrio entre ajuste y suavidad:
- \(\lambda = 0\): interpola los datos exactamente (sobreajuste).
- \(\lambda \to \infty\): la curva se vuelve una recta (infraajuste).
\(\lambda\) se selecciona por validación cruzada generalizada (GCV), un aproximación eficiente a la validación cruzada dejando uno fuera.
Selección de nodos en splines de regresión
Para splines de regresión con nodos prefijados, la posición y el número de nodos afectan al ajuste:
- Número de nodos: usa la validación cruzada o el AIC/BIC. Más nodos = más flexibilidad pero más varianza.
- Posición de los nodos: normalmente en los cuantiles de \(x\) para que cada intervalo tenga un número similar de observaciones. Otras opciones: distribución uniforme o nodos optimizados.
Una regla práctica: para \(n < 100\), usa 3-5 nodos; para \(n \in [100, 1000]\), usa 5-10 nodos; para \(n > 1000\), usa 10-20 nodos.
💡 Splines en R
library(splines)
# B-splines (splines de regresión estándar)
fit_bs <- lm(y ~ bs(x, df=8, degree=3), data=df)
# Splines cúbicos naturales
fit_ns <- lm(y ~ ns(x, df=6), data=df)
# Splines de suavizado (lambda por GCV)
fit_ss <- smooth.spline(df$x, df$y)
fit_ss$df # grados de libertad efectivos seleccionados
plot(fit_ss) # curva ajustada
# Splines con lambda fijo
fit_ss2 <- smooth.spline(df$x, df$y, lambda=0.001)
# Comparación de modelos por AIC
AIC(lm(y ~ ns(x, df=4), data=df),
lm(y ~ ns(x, df=8), data=df),
lm(y ~ ns(x, df=12), data=df))
