Regresión no lineal
La regresión no lineal modela relaciones donde los parámetros aparecen de forma no lineal en la función de media, por ejemplo \(f(x, \boldsymbol{\theta}) = \theta_1 e^{-\theta_2 x}\) o \(f(x, \boldsymbol{\theta}) = \theta_1 / (1 + e^{-\theta_2(x-\theta_3)})\). A diferencia de la regresión lineal, no existe solución en forma cerrada: los parámetros se estiman minimizando la suma de cuadrados de los residuos mediante algoritmos iterativos.
El modelo general
\[y_i = f(x_i, \boldsymbol{\theta}) + \varepsilon_i, \qquad \varepsilon_i \sim N(0, \sigma^2)\]
donde \(f\) es una función no lineal conocida de los predictores \(x_i\) y los parámetros desconocidos \(\boldsymbol{\theta} = (\theta_1, \ldots, \theta_p)\). El objetivo es minimizar la suma de cuadrados de los residuos (SCR):
\[\text{SCR}(\boldsymbol{\theta}) = \sum_{i=1}^n \bigl[y_i - f(x_i, \boldsymbol{\theta})\bigr]^2\]
Esta función no tiene solución analítica cuando \(f\) es no lineal en \(\boldsymbol{\theta}\): la optimización es iterativa y los valores iniciales importan.
Algoritmo de Gauss-Newton
Gauss-Newton linealiza \(f\) alrededor de la estimación actual \(\boldsymbol{\theta}^{(t)}\) usando la matriz jacobiana \(\mathbf{J}\) con \(J_{ij} = \partial f(x_i, \boldsymbol{\theta}^{(t)}) / \partial \theta_j\):
\[f(x_i, \boldsymbol{\theta}) \approx f(x_i, \boldsymbol{\theta}^{(t)}) + \mathbf{J}_i (\boldsymbol{\theta} - \boldsymbol{\theta}^{(t)})\]
Sustituyendo en la SCR y minimizando con respecto a la actualización \(\Delta\boldsymbol{\theta} = \boldsymbol{\theta} - \boldsymbol{\theta}^{(t)}\):
\[\boldsymbol{\theta}^{(t+1)} = \boldsymbol{\theta}^{(t)} + (\mathbf{J}^T\mathbf{J})^{-1}\mathbf{J}^T\mathbf{r}\]
donde \(\mathbf{r} = \mathbf{y} - f(\mathbf{x}, \boldsymbol{\theta}^{(t)})\) es el vector de residuos. Cada iteración resuelve un problema de mínimos cuadrados ponderados. Converge rápidamente cerca del mínimo, pero puede fallar si los valores iniciales son malos o si \(\mathbf{J}^T\mathbf{J}\) es casi singular.
Algoritmo de Levenberg-Marquardt
Levenberg-Marquardt añade un término de amortiguación \(\lambda\) a la actualización de Gauss-Newton:
\[\boldsymbol{\theta}^{(t+1)} = \boldsymbol{\theta}^{(t)} + (\mathbf{J}^T\mathbf{J} + \lambda\mathbf{I})^{-1}\mathbf{J}^T\mathbf{r}\]
- \(\lambda\) grande: se aproxima al descenso por gradiente (pasos pequeños, más robusto).
- \(\lambda\) pequeño: se aproxima a Gauss-Newton (pasos más grandes, más rápido cerca de la solución).
\(\lambda\) se actualiza en cada iteración: se reduce si la SCR disminuye (buena dirección), se aumenta si la SCR sube (paso demasiado grande). Esta estrategia adaptativa lo hace más robusto que Gauss-Newton para valores iniciales alejados del mínimo. Es el método estándar implementado en nls() de R.
Modelos habituales
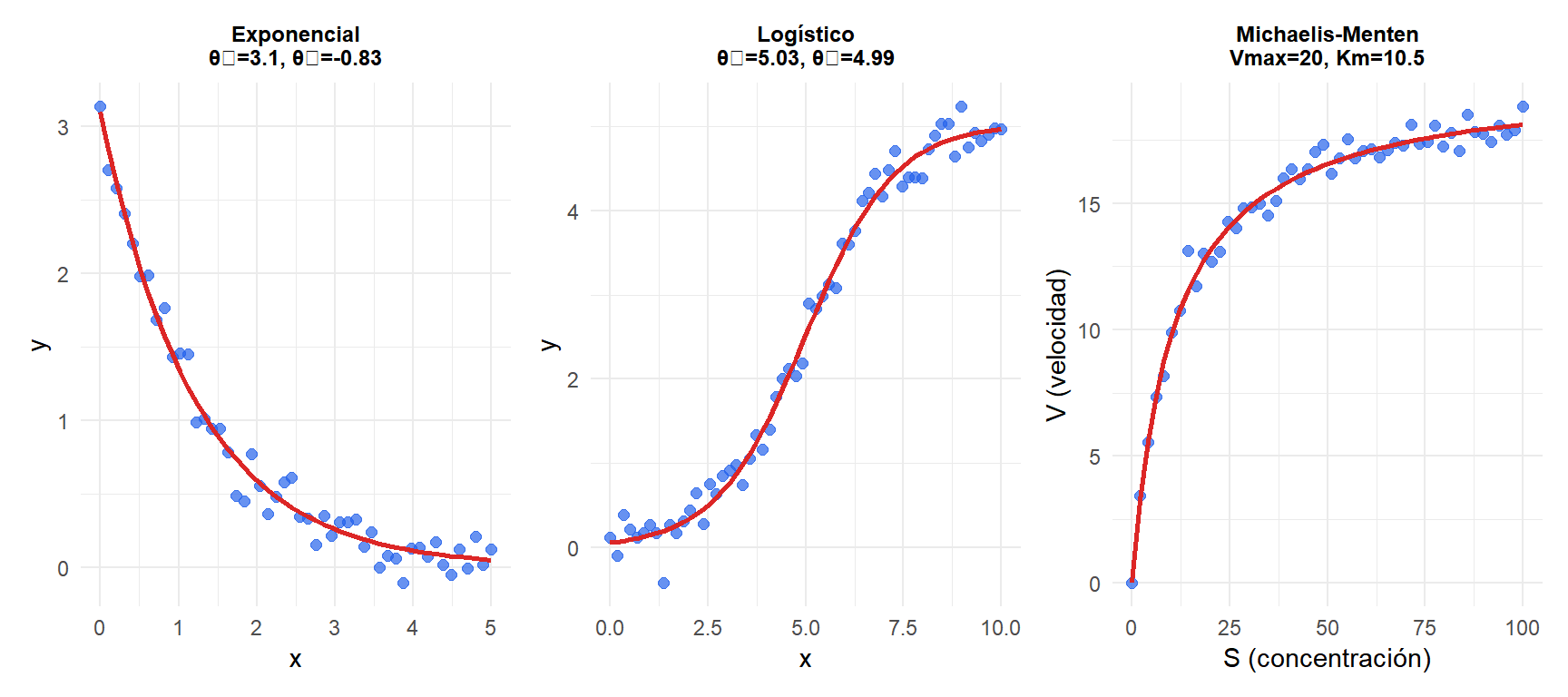
Modelo de crecimiento y decaimiento exponencial
\[f(x, \theta_1, \theta_2) = \theta_1 e^{\theta_2 x}\]
Útil para crecimiento poblacional (\(\theta_2 > 0\)) o decaimiento radiactivo (\(\theta_2 < 0\)). El modelo de crecimiento asintótico \(\theta_1(1 - e^{-\theta_2 x})\) añade una asíntota en \(\theta_1\).
Modelo logístico de crecimiento
\[f(x, \theta_1, \theta_2, \theta_3) = \frac{\theta_1}{1 + e^{-\theta_2(x - \theta_3)}}\]
- \(\theta_1\): asíntota superior (capacidad de carga).
- \(\theta_2\): tasa de crecimiento.
- \(\theta_3\): punto de inflexión.
Modela el crecimiento poblacional con límite de recursos, adopción de tecnologías o curvas de dosis-respuesta.
Modelo de Michaelis-Menten
\[f(S, V_{\max}, K_m) = \frac{V_{\max} S}{K_m + S}\]
- \(V_{\max}\): tasa de reacción máxima.
- \(K_m\): constante de Michaelis (concentración para la mitad de la velocidad máxima).
Estándar en enzimología, farmacología (cinética de Michaelis-Menten) y ecología. Tiene valores iniciales intuitivos: \(V_{\max}\) es aproximadamente la meseta observada; \(K_m\) es la concentración en la mitad de dicha meseta.
Valores iniciales
Los algoritmos iterativos necesitan valores iniciales. Puntos de partida deficientes pueden hacer que el algoritmo no converja o converja a un mínimo local.
Estrategias para elegir buenos valores iniciales:
- Conocimiento del dominio: en el modelo Michaelis-Menten, \(V_{\max} \approx\) meseta del gráfico, \(K_m \approx\) concentración en la mitad de la meseta.
- Linealizar el modelo: algunos modelos no lineales pueden transformarse en lineales (p. ej., \(\log y = \log \theta_1 + \theta_2 x\) para el exponencial). Ajusta el modelo linealizado y usa los coeficientes como punto de partida.
- Autoarranque: R incluye funciones de arranque automático para modelos habituales (
SSlogis,SSasymp,SSmicmen) que calculan los valores iniciales a partir de los datos.
⚠️ Los errores estándar en regresión no lineal son aproximados
A diferencia de la regresión lineal, los errores estándar de los parámetros en regresión no lineal son aproximaciones de primer orden basadas en la linealización. Son exactos solo asintóticamente (\(n \to \infty\)).
En muestras pequeñas o parámetros con correlaciones elevadas, los intervalos de confianza basados en perfiles de verosimilitud son más fiables que los basados en errores estándar asintóticos. Usa confint(fit_nls, method="profile") en R.
💡 Regresión no lineal en R
# Modelo logístico con autoarranque
fit <- nls(y ~ SSlogis(x, Asym, xmid, scal), data = df)
summary(fit)
confint(fit, method = "profile") # IC basados en perfil de verosimilitud
# Sin autoarranque
fit2 <- nls(y ~ theta1 * exp(theta2 * x),
data = df,
start = list(theta1 = 3, theta2 = -0.5),
algorithm = "port",
lower = c(0, -Inf), upper = c(Inf, 0))
# Modelo de Michaelis-Menten con autoarranque
fit_mm <- nls(V ~ SSmicmen(S, Vmax, Km), data = df)
# Comparación de modelos anidados con anova
anova(fit_reducido, fit_completo)
