Regresión lineal simple
La regresión lineal simple modela la relación lineal entre una variable respuesta \(y\) y un único predictor \(x\) ajustando una recta a los datos. Es la base del análisis de regresión: toda regresión múltiple, regresión logística y modelo regularizado construye sobre estos conceptos.
El modelo
\[y_i = \beta_0 + \beta_1 x_i + \varepsilon_i, \qquad \varepsilon_i \sim N(0, \sigma^2)\]
- \(\beta_0\): intercepto. El valor esperado de \(y\) cuando \(x = 0\).
- \(\beta_1\): pendiente. El cambio esperado en \(y\) por un incremento de una unidad en \(x\).
- \(\varepsilon_i\): término de error. Captura todo lo que afecta a \(y\) más allá de \(x\): error de medición, variables omitidas, aleatoriedad inherente.
El modelo establece cuatro supuestos (LINE): Linealidad, Independencia de los errores, Normalidad de los errores, Equal varianza (homocedasticidad). Estos se comprueban en el artículo de diagnósticos.
Estimación por MCO
Los Mínimos Cuadrados Ordinarios (MCO) encuentran \(\hat{\beta}_0\) y \(\hat{\beta}_1\) que minimizan la suma de cuadrados de los residuos:
\[\text{SCR} = \sum_{i=1}^n (y_i - \hat{\beta}_0 - \hat{\beta}_1 x_i)^2\]
Derivando e igualando a cero se obtienen los estimadores en forma cerrada:
\[\hat{\beta}_1 = \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^n (x_i - \bar{x})^2} = r_{xy} \cdot \frac{S_y}{S_x}\]
\[\hat{\beta}_0 = \bar{y} - \hat{\beta}_1 \bar{x}\]
donde \(r_{xy}\) es la correlación de Pearson, \(S_y\) y \(S_x\) son las desviaciones típicas muestrales. La recta de regresión siempre pasa por el punto de las medias \((\bar{x}, \bar{y})\).
La conexión con la correlación: \(\hat{\beta}_1 = 0\) si y solo si \(r_{xy} = 0\). Contrastar \(H_0: \beta_1 = 0\) equivale a contrastar \(H_0: \rho = 0\).
Ejemplo: gasto en publicidad y ventas
Una empresa registra el gasto semanal en publicidad televisiva (miles de €) y las ventas semanales (miles de unidades) durante 50 semanas.
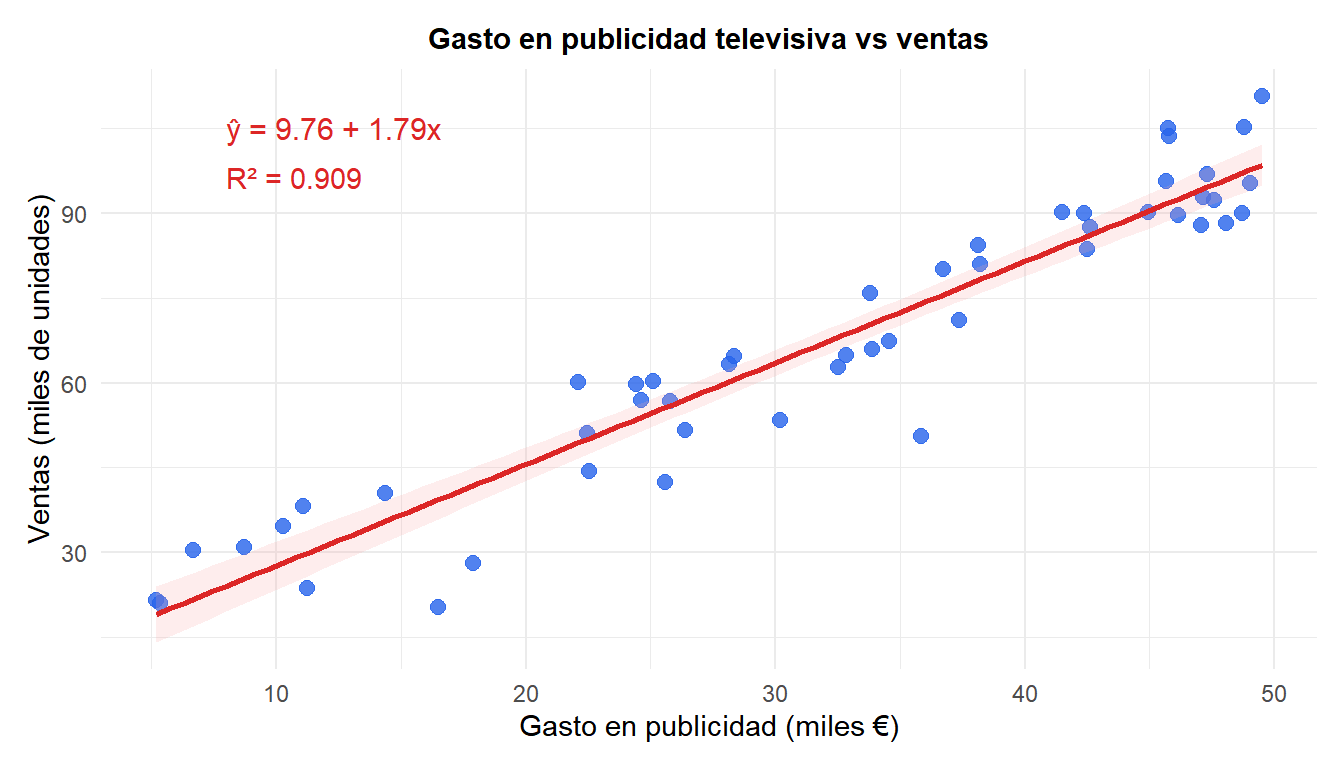
Cada €1.000 adicionales de publicidad televisiva se asocian con aproximadamente 1.79 miles de unidades vendidas extra. El intercepto (9.76) representa las ventas base con cero publicidad. $R^2 = $ 0.909 significa que el 90.9% de la variación en ventas queda explicada por el gasto en publicidad.
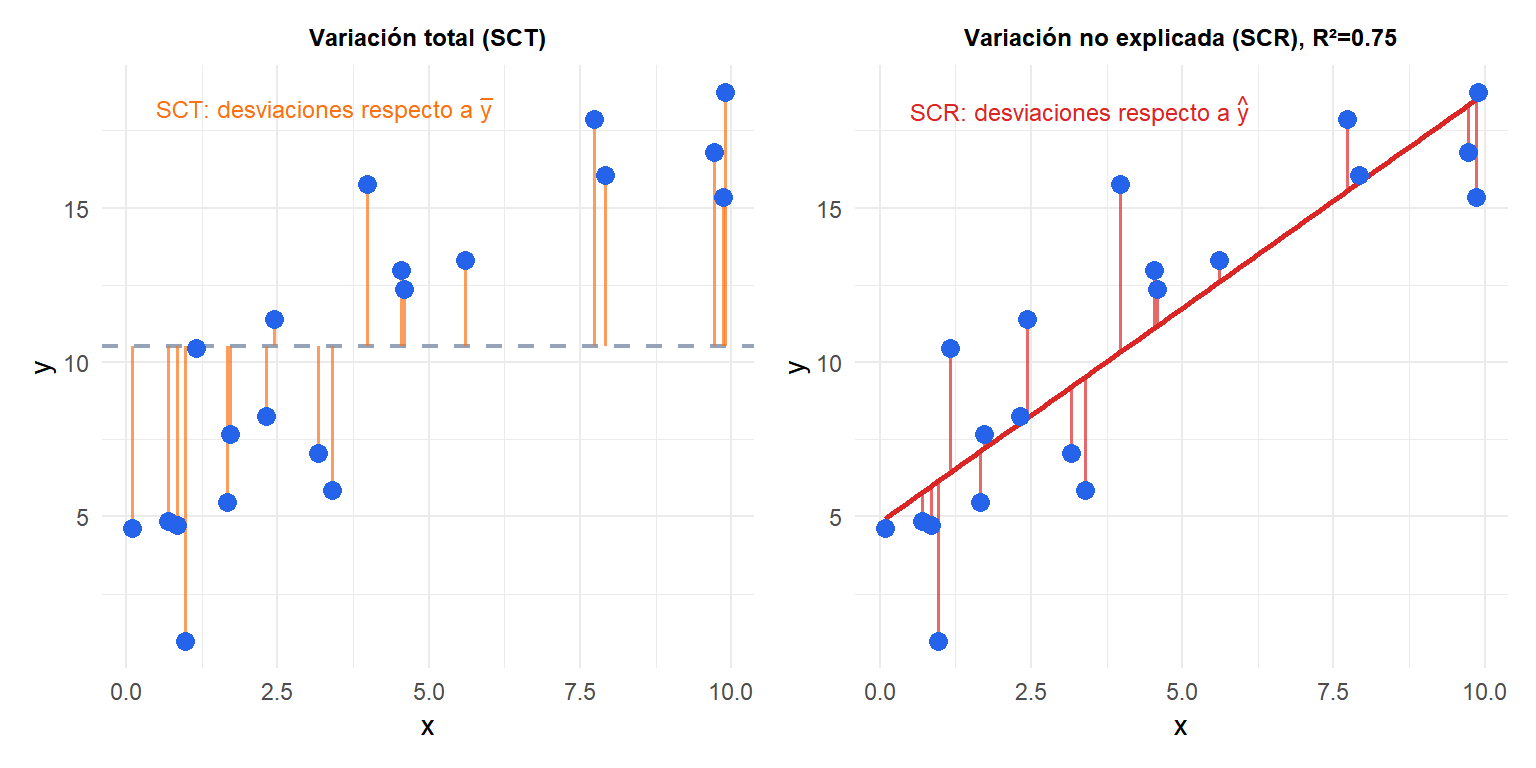
Bondad de ajuste: R²
El \(R^2\) mide la proporción de varianza en \(y\) explicada por el modelo:
\[R^2 = 1 - \frac{\text{SCR}}{\text{SCT}} = 1 - \frac{\sum(y_i - \hat{y}_i)^2}{\sum(y_i - \bar{y})^2}\]
\(R^2 \in [0,1]\). Un \(R^2\) de 0,70 significa que el 70 % de la varianza en \(y\) queda explicada por \(x\); el 30 % restante es variación no explicada. En regresión lineal simple, \(R^2 = r_{xy}^2\).
Inferencia sobre la pendiente
Bajo los supuestos del modelo, \(\hat{\beta}_1\) sigue una distribución normal:
\[\hat{\beta}_1 \sim N\!\left(\beta_1,\; \frac{\sigma^2}{\sum(x_i-\bar{x})^2}\right)\]
Como \(\sigma^2\) es desconocida, se estima con \(\hat{\sigma}^2 = \text{SCR}/(n-2)\) y se usa la distribución \(t\):
\[t = \frac{\hat{\beta}_1 - 0}{\widehat{\text{ET}}(\hat{\beta}_1)} \sim t(n-2) \quad \text{bajo } H_0: \beta_1 = 0\]
Un intervalo de confianza al \((1-\alpha)\) para \(\beta_1\):
\[\hat{\beta}_1 \pm t_{\alpha/2, n-2} \cdot \widehat{\text{ET}}(\hat{\beta}_1)\]
Un contraste \(t\) significativo (\(p < 0{,}05\)) significa que \(x\) es un predictor estadísticamente significativo de \(y\): la pendiente observada difícilmente surge por azar si \(\beta_1 = 0\).
⚠️ La significación estadística no implica importancia práctica
Una muestra muy grande puede producir una pendiente estadísticamente significativa pero prácticamente despreciable. Un incremento de \(\hat{\beta}_1 = 0{,}001\) unidades por cada €1.000 de publicidad puede ser significativo con \(p < 0{,}001\) para \(n = 10.000\) observaciones, pero es irrelevante comercialmente.
Comunica siempre el tamaño del efecto (la propia pendiente y su intervalo de confianza) junto al valor p. El intervalo de confianza transmite tanto la dirección como la magnitud plausible del efecto.
Predicción
Para una nueva observación en \(x_\text{nuevo}\), el modelo produce dos tipos de intervalos:
Intervalo de confianza para la respuesta media: incertidumbre sobre el \(y\) promedio en \(x_\text{nuevo}\) en la población.
Intervalo de predicción para una nueva observación: más amplio, porque añade el error individual \(\varepsilon\) a la incertidumbre sobre la media.
\[\hat{y}_\text{nuevo} \pm t_{\alpha/2, n-2} \cdot \hat{\sigma}\sqrt{1 + \frac{1}{n} + \frac{(x_\text{nuevo}-\bar{x})^2}{\sum(x_i-\bar{x})^2}}\]
Ambos intervalos se ensanchan a medida que \(x_\text{nuevo}\) se aleja de \(\bar{x}\): la extrapolación es cada vez menos fiable.
💡 Regresión lineal simple en R
fit <- lm(sales ~ spend, data = df)
summary(fit) # coeficientes, contrastes t, R²
confint(fit) # IC al 95% para beta0 y beta1
predict(fit, newdata = data.frame(spend = 30),
interval = "confidence") # IC para la respuesta media
predict(fit, newdata = data.frame(spend = 30),
interval = "prediction") # IP para nueva observación
