Máquinas de soporte vectorial (SVM)
Las máquinas de soporte vectorial (SVM) encuentran el hiperplano que separa dos clases con el mayor margen posible. Solo los puntos más cercanos al hiperplano, los vectores de soporte, determinan su posición: el resto de los puntos de entrenamiento son irrelevantes. El truco del núcleo extiende las SVM a fronteras no lineales proyectando implícitamente los datos a un espacio de alta dimensión.
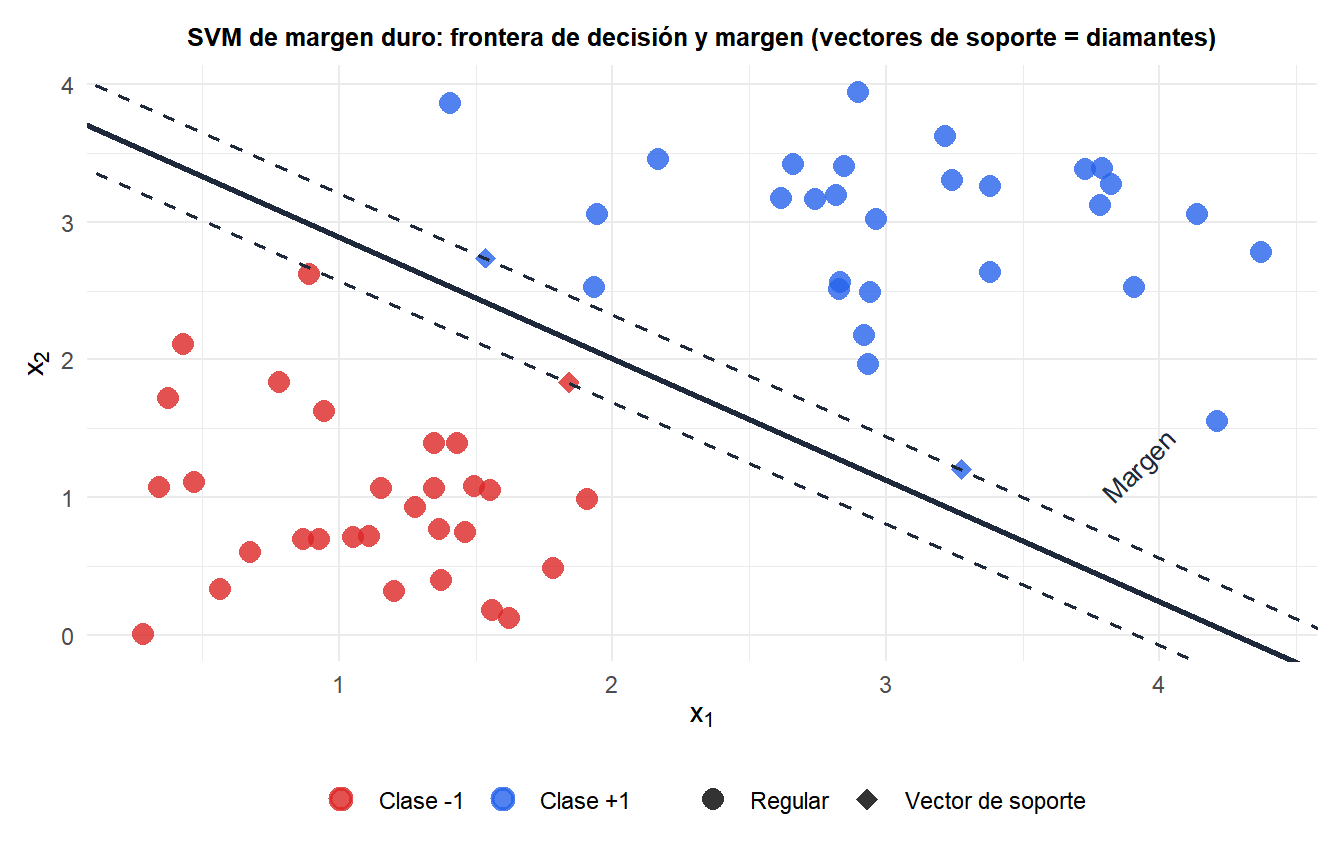
SVM de margen duro
Para datos linealmente separables con etiquetas \(y_i \in \{-1, +1\}\), la frontera de decisión es el hiperplano \(\mathbf{w}^T\mathbf{x} + b = 0\). Los puntos con \(y_i = +1\) deben satisfacer \(\mathbf{w}^T\mathbf{x}_i + b \geq +1\) y los con \(y_i = -1\) deben satisfacer \(\mathbf{w}^T\mathbf{x}_i + b \leq -1\). Combinando: \(y_i(\mathbf{w}^T\mathbf{x}_i + b) \geq 1\) para todo \(i\).
El ancho del margen es \(2/\|\mathbf{w}\|\). Maximizar el margen equivale a minimizar \(\|\mathbf{w}\|^2\):
\[\min_{\mathbf{w},b} \frac{1}{2}\|\mathbf{w}\|^2 \quad \text{s.a.} \quad y_i(\mathbf{w}^T\mathbf{x}_i + b) \geq 1 \quad \forall i\]
Es un programa cuadrático convexo. Las condiciones KKT dan el problema dual, y solo los puntos de entrenamiento donde \(y_i(\mathbf{w}^T\mathbf{x}_i + b) = 1\) (sobre el límite del margen) tienen multiplicadores duales \(\alpha_i > 0\): son los vectores de soporte. Todos los demás puntos son irrelevantes para la solución. Esta dispersión es una propiedad clave: las predicciones usan solo los vectores de soporte.
SVM de margen blando
Los datos reales raramente son linealmente separables. La SVM de margen blando introduce variables de holgura \(\xi_i \geq 0\) que permiten a los puntos violar la restricción del margen:
\[\min_{\mathbf{w},b,\boldsymbol{\xi}} \frac{1}{2}\|\mathbf{w}\|^2 + C\sum_{i=1}^n \xi_i \quad \text{s.a.} \quad y_i(\mathbf{w}^T\mathbf{x}_i + b) \geq 1 - \xi_i,\quad \xi_i \geq 0\]
El parámetro \(C > 0\) controla el intercambio:
- \(C\) grande: penaliza fuertemente las violaciones del margen. Margen más estrecho pero menos clasificaciones erróneas en los datos de entrenamiento. Propenso al sobreajuste.
- \(C\) pequeño: tolera más violaciones. Margen más amplio, más regularizado. Propenso al infraajuste.
\(C\) es el hiperparámetro más importante y debe seleccionarse mediante validación cruzada. Los vectores de soporte son ahora los puntos que están en el límite del margen (\(\xi_i = 0\), \(\alpha_i > 0\)) o lo violan (\(\xi_i > 0\)): la fracción de vectores de soporte típicamente aumenta al disminuir \(C\).
El problema dual y los núcleos
El dual lagrangiano del problema de margen blando es:
\[\max_{\boldsymbol{\alpha}} \sum_i \alpha_i - \frac{1}{2}\sum_{i,j}\alpha_i\alpha_j y_i y_j \mathbf{x}_i^T\mathbf{x}_j \quad \text{s.a.} \quad 0 \leq \alpha_i \leq C,\quad \sum_i \alpha_i y_i = 0\]
La observación clave: el objetivo depende de los datos solo a través de los productos internos \(\mathbf{x}_i^T\mathbf{x}_j\). La predicción para un nuevo punto también usa solo productos internos:
\[\hat{y}(\mathbf{x}) = \text{signo}\!\left(\sum_{i \in VS} \alpha_i y_i \mathbf{x}_i^T\mathbf{x} + b\right)\]
El truco del núcleo: reemplaza cada producto interno \(\mathbf{x}_i^T\mathbf{x}_j\) con una función de núcleo \(K(\mathbf{x}_i, \mathbf{x}_j) = \phi(\mathbf{x}_i)^T\phi(\mathbf{x}_j)\) donde \(\phi\) es una proyección implícita. Esto permite que la SVM opere en un espacio de características muy alto (o infinito) sin calcular jamás \(\phi(\mathbf{x})\) explícitamente.
Núcleos habituales
| Núcleo | Fórmula | Cuándo usarlo |
|---|---|---|
| Lineal | \(K(\mathbf{x},\mathbf{x}') = \mathbf{x}^T\mathbf{x}'\) | Separable linealmente, \(p\) alto |
| Polinomial | \(K(\mathbf{x},\mathbf{x}') = (\mathbf{x}^T\mathbf{x}' + c)^d\) | Interacciones polinomiales |
| RBF/Gaussiano | \(K(\mathbf{x},\mathbf{x}') = e^{-\gamma\|\mathbf{x}-\mathbf{x}'\|^2}\) | General no lineal, el más común |
| Sigmoidal | \(K(\mathbf{x},\mathbf{x}') = \tanh(\kappa\mathbf{x}^T\mathbf{x}' + c)\) | Similar a red neuronal |
El núcleo RBF con ancho de banda \(\gamma\) es el más usado. \(\gamma\) menor: frontera más suave (los puntos lejanos se influyen entre sí). \(\gamma\) mayor: cada punto de entrenamiento influye solo en su vecindario inmediato, llevando al sobreajuste.
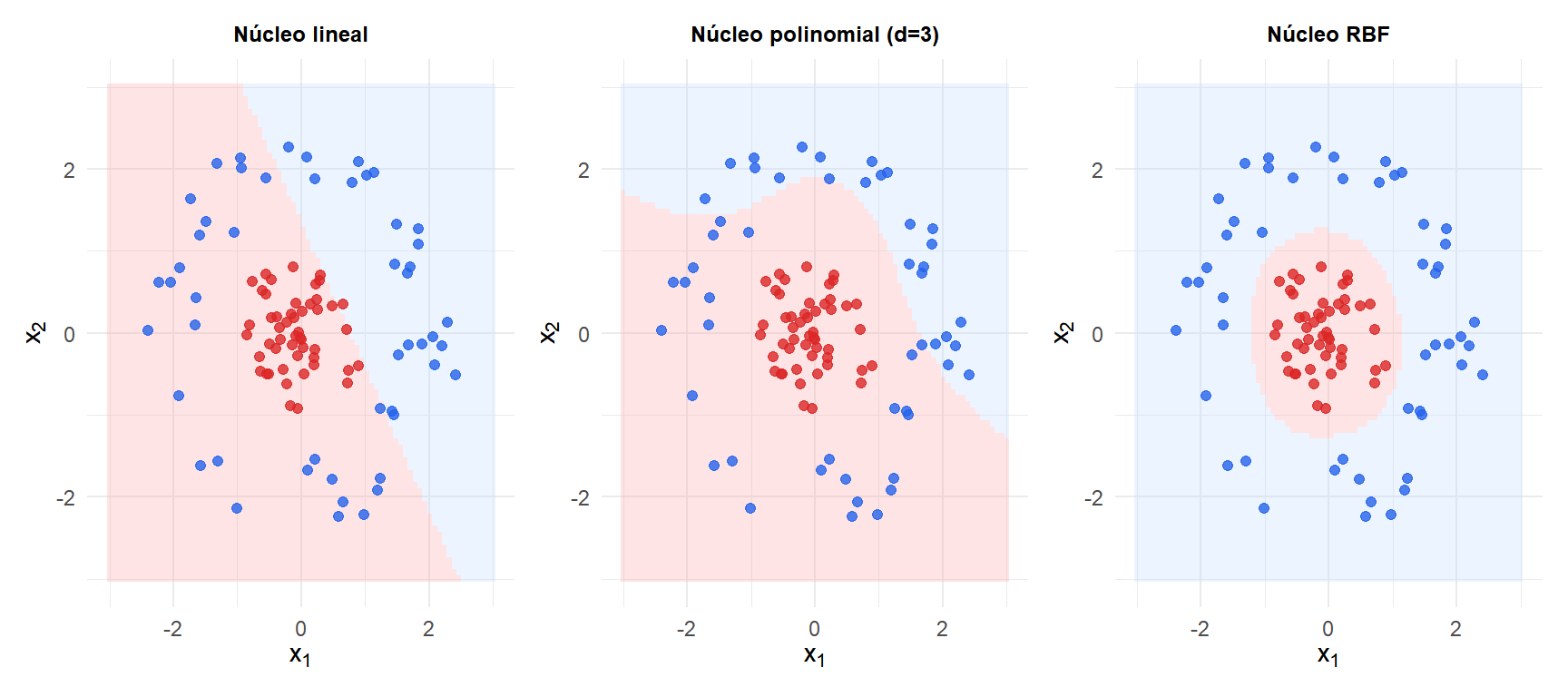
En datos circulares (no separables linealmente), el núcleo lineal falla completamente. El núcleo polinomial captura algo de no linealidad. El núcleo RBF aprende correctamente la frontera circular.
Ajuste de hiperparámetros
Dos hiperparámetros clave para SVM-RBF: \(C\) y \(\gamma\). Interactúan: \(\gamma\) grande con \(C\) grande sobreajusta; \(\gamma\) pequeño con \(C\) pequeño infraajusta. El enfoque estándar es una búsqueda en rejilla 2D con validación cruzada:
- Rejilla de \(C\): \(\{0,01;\, 0,1;\, 1;\, 10;\, 100;\, 1000\}\)
- Rejilla de \(\gamma\): \(\{0,001;\, 0,01;\, 0,1;\, 1;\, 10\}\)
Un punto de partida heurístico para \(\gamma\): \(1/(p \cdot \text{Var}(\mathbf{X}))\) donde \(p\) es el número de características.
⚠️ Las SVM escalan mal con n grande
Entrenar una SVM requiere resolver un programa cuadrático con \(n\) variables. Los solucionadores cuadráticos ingenuos tienen complejidad \(O(n^3)\). La Optimización Mínima Secuencial (SMO), el algoritmo estándar en libsvm, la reduce a aproximadamente \(O(n^2)\) pero puede seguir siendo lenta para \(n > 100{,}000\).
Para conjuntos de datos grandes: usa una SVM lineal (mucho más rápida, \(O(n)\) con métodos de gradiente estocástico) o cambia a gradient boosting o redes neuronales, que escalan mejor. El truco del núcleo es potente pero también costoso computacionalmente en tiempo de predicción: las predicciones requieren evaluar \(K(\mathbf{x}, \mathbf{x}_i)\) para todos los vectores de soporte.
💡 SVM en R
library(e1071)
# SVM lineal
fit_lin <- svm(y ~ ., data=df_train, kernel="linear", cost=1)
# SVM RBF
fit_rbf <- svm(y ~ ., data=df_train, kernel="radial",
cost=10, gamma=0.1)
# Búsqueda en rejilla de C y gamma
tune_result <- tune(svm, y ~ ., data=df_train,
kernel="radial",
ranges=list(cost=10^(-1:3), gamma=10^(-3:1)))
best_model <- tune_result$best.model
summary(tune_result)
# Predicciones y probabilidades
predict(fit_rbf, newdata=df_test)
predict(fit_rbf, newdata=df_test, decision.values=TRUE)
# Regresión con vectores de soporte (SVR)
fit_svr <- svm(y ~ ., data=df_train, type="eps-regression",
kernel="radial", epsilon=0.1)
