K vecinos más cercanos (KNN)
El algoritmo K vecinos más cercanos (KNN) predice la clase o valor de una nueva observación usando las \(K\) observaciones de entrenamiento más similares. Es no paramétrico (no asume ninguna forma funcional), perezoso (no hay entrenamiento: toda la computación ocurre en la predicción) y conceptualmente simple. Su mayor limitación es la maldición de la dimensionalidad: en dimensiones altas, los vecinos más cercanos dejan de estar cerca.
El algoritmo
Para clasificación, dado un nuevo punto \(\mathbf{x}\):
- Calcular la distancia de \(\mathbf{x}\) a todos los puntos de entrenamiento.
- Seleccionar los \(K\) puntos más cercanos.
- Predecir la clase más frecuente entre esos \(K\) vecinos (voto por mayoría).
Para regresión: predecir la media de los \(K\) vecinos más cercanos.
\[\hat{y}(\mathbf{x}) = \frac{1}{K} \sum_{i \in N_K(\mathbf{x})} y_i \quad \text{(regresión)}\]
\[\hat{c}(\mathbf{x}) = \arg\max_c \sum_{i \in N_K(\mathbf{x})} \mathbf{1}[y_i = c] \quad \text{(clasificación)}\]
donde \(N_K(\mathbf{x})\) es el conjunto de los \(K\) vecinos más cercanos a \(\mathbf{x}\).
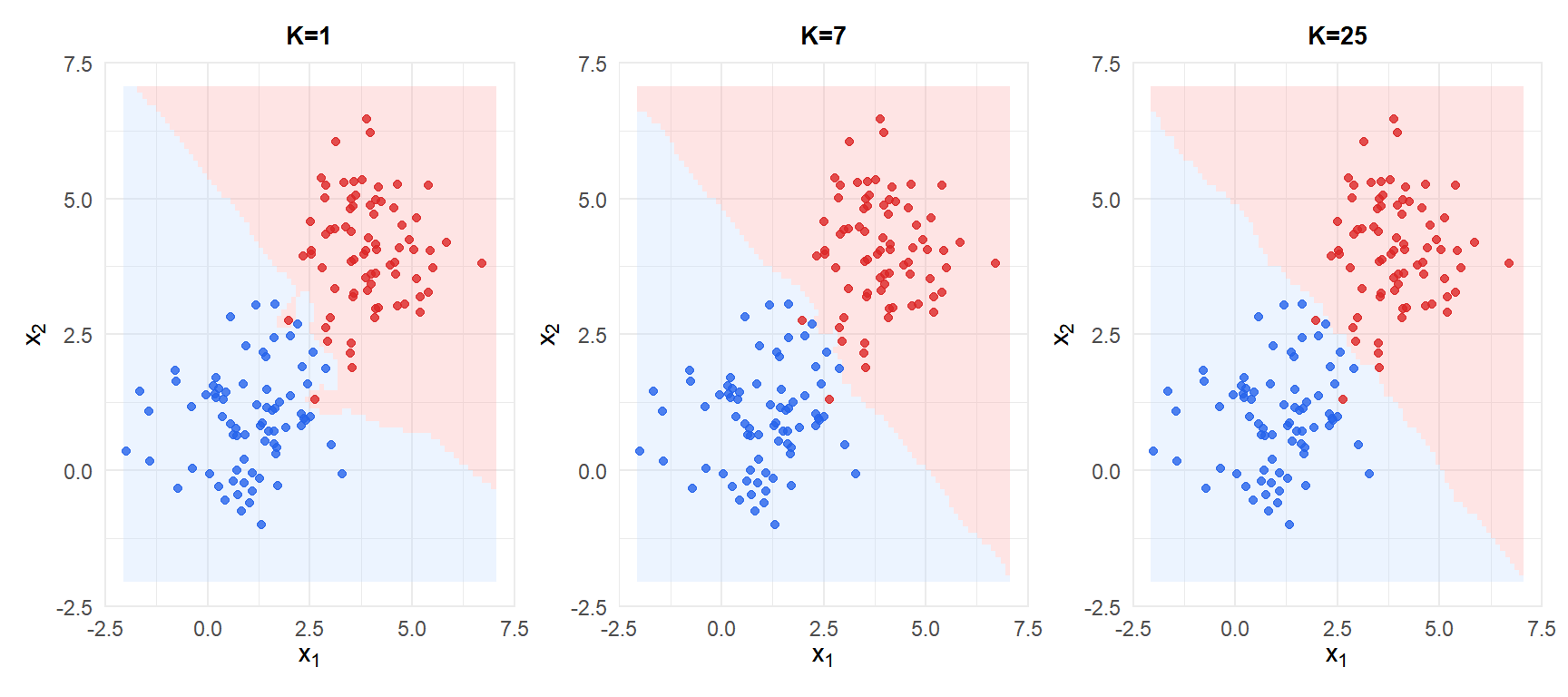
Con \(K=1\) la frontera se sobreajusta al ruido. Con \(K=25\) la frontera es suave. El valor óptimo de \(K\) se selecciona por validación cruzada.
Métricas de distancia
La elección de la métrica de distancia define la noción de “cercanía”:
| Métrica | Fórmula | Cuándo usarla |
|---|---|---|
| Euclidiana | \(\sqrt{\sum_j(x_j-x_j')^2}\) | Variables continuas, escala similar |
| Manhattan | \(\sum_j \|x_j-x_j'\|\) | Más robusta a valores atípicos |
| Minkowski | \((\sum_j \|x_j-x_j'\|^p)^{1/p}\) | Generaliza euclidiana (\(p=2\)) y Manhattan (\(p=1\)) |
| Mahalanobis | \(\sqrt{(\mathbf{x}-\mathbf{x}')^T\mathbf{S}^{-1}(\mathbf{x}-\mathbf{x}')}\) | Corrige escala y correlación |
| Hamming | Fracción de posiciones distintas | Variables categóricas o binarias |
La distancia euclidiana es la más usada pero asume que todas las variables están en la misma escala. Siempre normaliza antes de usar KNN: si \(x_1\) varía entre 0 y 1 y \(x_2\) entre 0 y 1000, \(x_2\) dominará completamente las distancias.
La maldición de la dimensionalidad
En dimensiones altas, todos los puntos tienden a estar a distancias similares entre sí. Intuitivamente: si tenemos \(n\) puntos en un hipercubo unitario de dimensión \(p\), el radio esperado de la esfera que contiene los \(K\) vecinos más cercanos crece rápidamente con \(p\).
Para capturar el 10 % de los puntos en un hipercubo de dimensión \(p\) se necesita abarcar una fracción \(r = 0{,}1^{1/p}\) de cada dimensión:
- \(p=1\): \(r = 0{,}1\) (el 10 % del rango).
- \(p=10\): \(r = 0{,}1^{1/10} \approx 0{,}79\) (el 79 % del rango: casi todo).
- \(p=100\): \(r \approx 0{,}977\) (prácticamente todo el espacio).
Cuando los vecinos más cercanos no están cerca (ocupan casi todo el espacio), el KNN pierde su sentido: el promedio de los vecinos no es una estimación local de \(f(\mathbf{x})\).
⚠️ KNN no escala bien a alta dimensión ni a n grande
Dos problemas de escalabilidad del KNN: (1) en dimensiones altas (maldición), los resultados se degradan y se necesita \(n\) exponencialmente mayor para mantener la precisión; (2) la complejidad de predicción es \(O(np)\) por consulta sin indexación: con \(n=10^6\) observaciones, cada predicción requiere un millón de evaluaciones de distancia.
Soluciones: usar un árbol kd o una estructura de bola-árbol para \(O(\log n)\) con dimensión baja; aplicar reducción de dimensionalidad (PCA, UMAP) antes de KNN; o cambiar a modelos paramétricos cuando \(p\) sea grande.
💡 KNN en R
library(class)
library(caret)
# Normalizar predictores
X_norm <- scale(X_train)
X_test_norm <- scale(X_test,
center=attr(X_norm,"scaled:center"),
scale=attr(X_norm,"scaled:scale"))
# KNN para clasificación
pred <- knn(train=X_norm, test=X_test_norm, cl=y_train, k=7)
# Selección de K con validación cruzada (caret)
ctrl <- trainControl(method="cv", number=10)
fit <- train(y ~ ., data=df_train, method="knn",
trControl=ctrl,
tuneGrid=data.frame(k=seq(1,30,by=2)),
preProcess=c("center","scale"))
fit$bestTune
plot(fit)
# KNN ponderado (por 1/distancia)
library(kknn)
fit_w <- kknn(y ~ ., train=df_train, test=df_test,
k=7, kernel="inv") # kernel="inv" = ponderado por 1/d
