Análisis de componentes principales (PCA)
El Análisis de Componentes Principales (PCA) encuentra una representación de menor dimensión de los datos que captura la máxima varianza posible. Lo hace rotando el sistema de coordenadas para alinearlo con las direcciones de máxima varianza en los datos. El resultado es un conjunto de componentes no correlacionadas, ordenadas por la cantidad de varianza que explican.
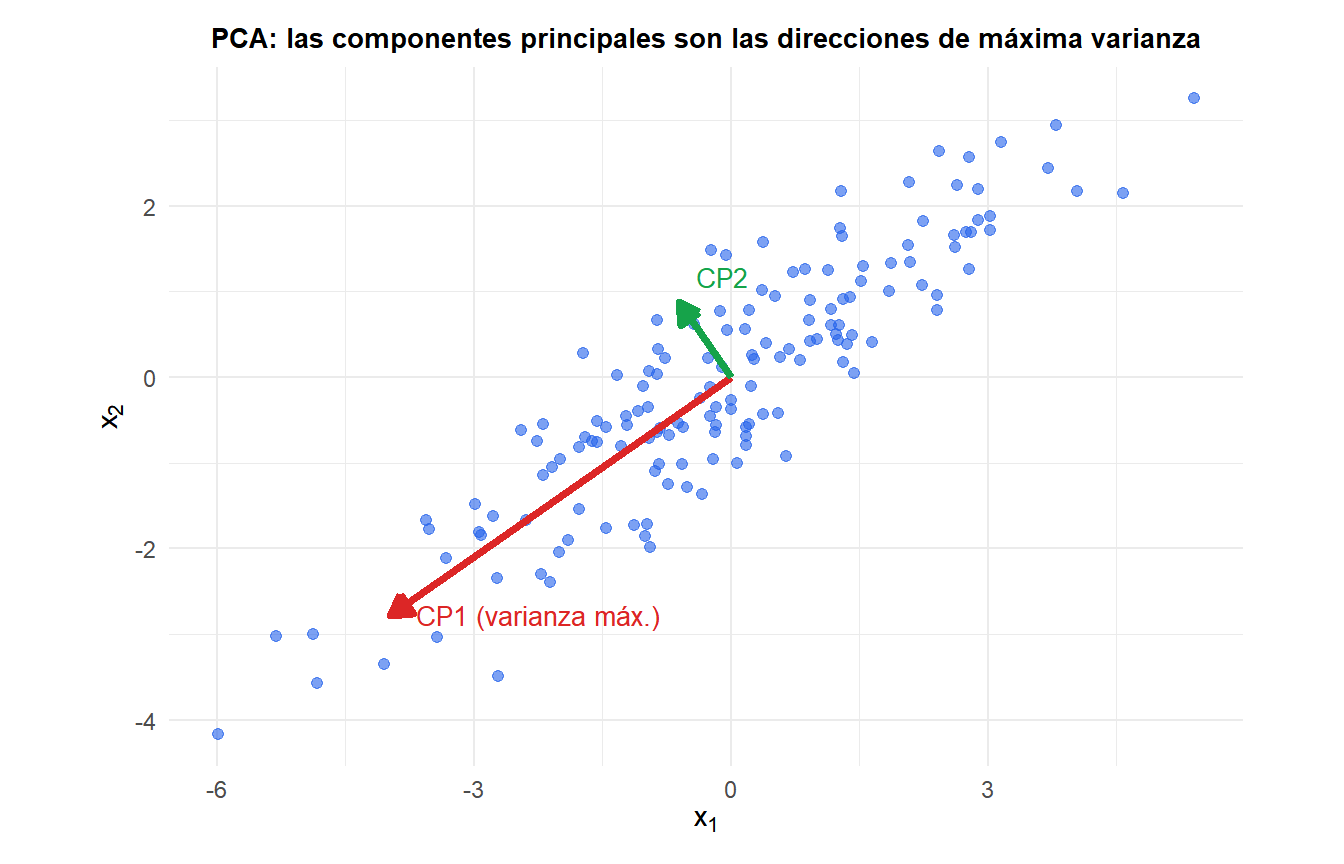
Lo que hace el PCA geométricamente
Dadas \(n\) observaciones de \(p\) variables, el PCA encuentra una secuencia de direcciones ortogonales \(\mathbf{v}_1, \mathbf{v}_2, \ldots, \mathbf{v}_p\) (las componentes principales) tales que:
- \(\mathbf{v}_1\) es la dirección de máxima varianza en los datos.
- \(\mathbf{v}_2\) es la dirección de máxima varianza en el subespacio ortogonal a \(\mathbf{v}_1\).
- Y así sucesivamente.
La proyección de los datos sobre \(\mathbf{v}_k\) da las puntuaciones \(\mathbf{z}_k = \mathbf{X}\mathbf{v}_k\): las coordenadas de cada observación en el nuevo sistema de coordenadas. Las direcciones \(\mathbf{v}_k\) se denominan cargas: indican cuánto contribuye cada variable original a cada componente.
Derivación matemática
Centrar los datos: \(\tilde{\mathbf{X}} = \mathbf{X} - \bar{\mathbf{X}}\). La matriz de covarianza muestral es:
\[\mathbf{S} = \frac{1}{n-1}\tilde{\mathbf{X}}^T\tilde{\mathbf{X}}\]
Las componentes principales son los vectores propios de \(\mathbf{S}\):
\[\mathbf{S}\mathbf{v}_k = \lambda_k \mathbf{v}_k\]
donde \(\lambda_k\) es la varianza explicada por la \(k\)-ésima componente. Los vectores propios son ortonormales (\(\mathbf{v}_j^T\mathbf{v}_k = 0\) para \(j \neq k\), \(\|\mathbf{v}_k\|=1\)) y están ordenados por valor propio decreciente \(\lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_p \geq 0\).
Conexión con la SVD: la descomposición en valores singulares de \(\tilde{\mathbf{X}} = \mathbf{U}\mathbf{D}\mathbf{V}^T\) da inmediatamente:
\[\tilde{\mathbf{X}}^T\tilde{\mathbf{X}} = \mathbf{V}\mathbf{D}^2\mathbf{V}^T\]
Los vectores singulares derechos \(\mathbf{V}\) son las cargas de las componentes principales, y los valores singulares \(d_k\) se relacionan con los valores propios mediante \(\lambda_k = d_k^2/(n-1)\). Calcular el PCA mediante SVD es numéricamente más estable que la descomposición espectral de \(\mathbf{S}\) cuando \(p\) es grande o algunas variables son casi colineales.
PCA de covarianza vs. correlación
El PCA sobre la matriz de covarianza preserva la escala original: las variables con gran varianza dominan las componentes. El PCA sobre la matriz de correlación (equivalente a estandarizar primero cada variable a varianza unitaria) da el mismo peso a todas las variables independientemente de su escala.
Estandariza siempre cuando las variables se miden en unidades distintas (p.ej., altura en cm y peso en kg). Cuando todas las variables están en la misma escala (p.ej., recuentos de expresión génica), el PCA de covarianza es apropiado y preserva diferencias significativas en varianza.
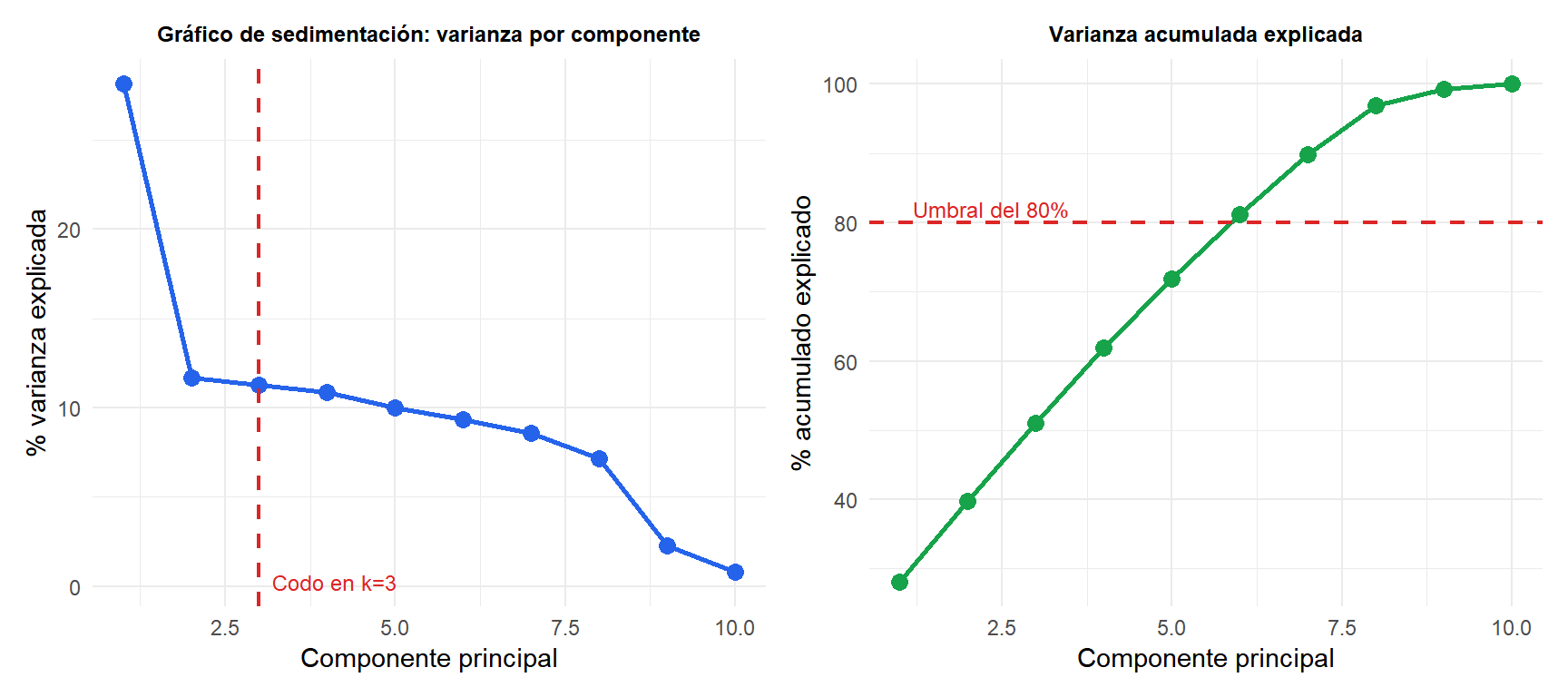
Elegir el número de componentes
La proporción de varianza explicada por la componente \(k\):
\[\text{PVE}_k = \frac{\lambda_k}{\sum_{j=1}^p \lambda_j}\]
Gráfico de sedimentación: representa \(\lambda_k\) (o \(\text{PVE}_k\)) frente a \(k\). Busca el “codo” donde la curva se aplana. Las componentes a la izquierda del codo capturan la mayor parte de la estructura; las de la derecha capturan ruido.
Criterio de Kaiser: retener las componentes con \(\lambda_k > 1\) (para PCA de correlación: componentes que explican más que una única variable original).
Umbral de varianza acumulada: retener suficientes componentes para explicar el 80-90% de la varianza total.
El biplot
Un biplot superpone las puntuaciones (observaciones en el espacio de componentes) y las cargas (variables originales como flechas) en el mismo gráfico. Permite la interpretación simultánea de ambas:
- Las observaciones cercanas entre sí tienen perfiles similares.
- Las variables (flechas) que apuntan en la misma dirección están positivamente correlacionadas; en dirección opuesta, negativamente correlacionadas; las flechas perpendiculares no están correlacionadas.
- La longitud de la flecha indica cuánta varianza de la variable es capturada por las dos componentes mostradas.
- Una observación cercana a una flecha puntúa alto en esa variable.
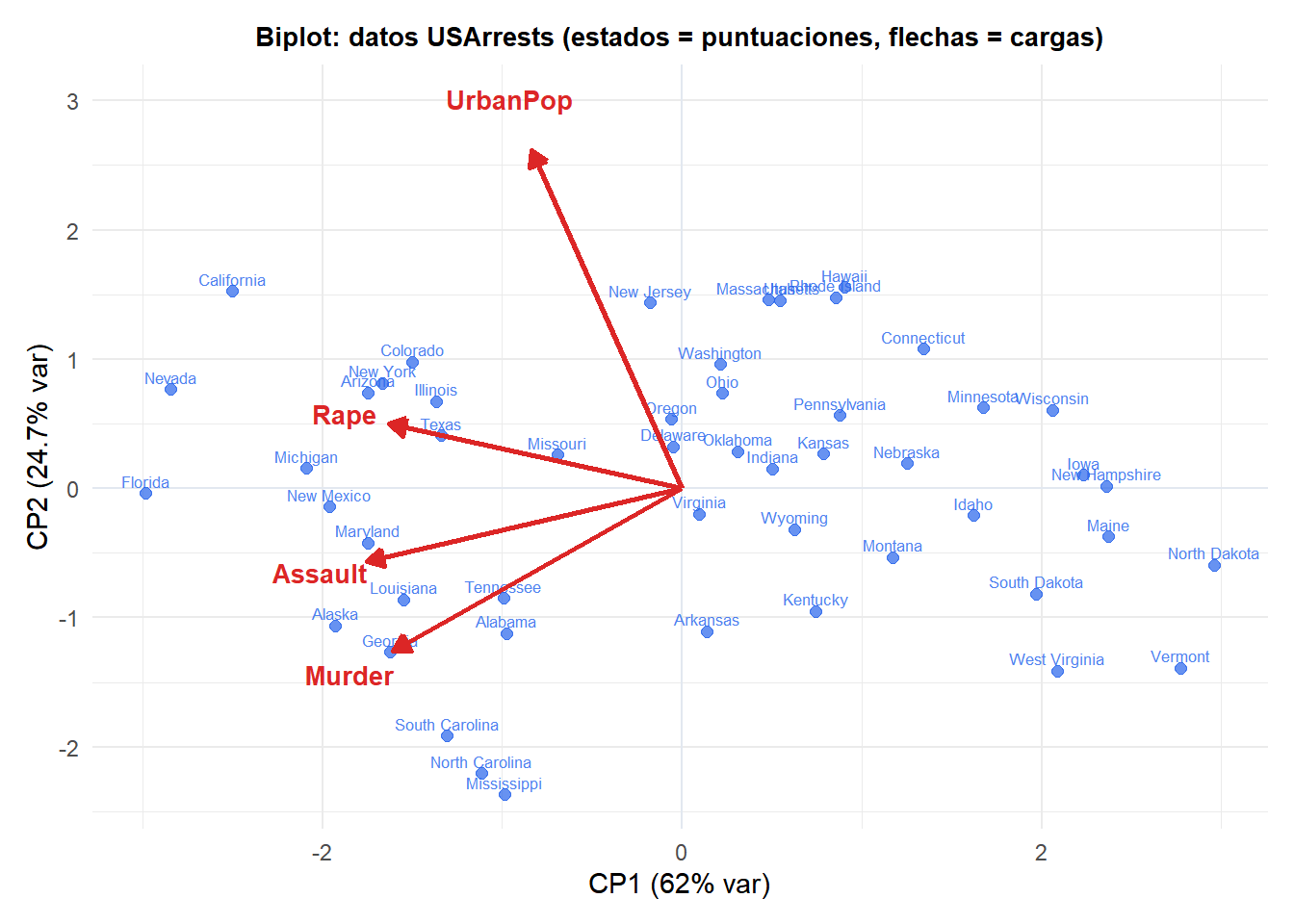
CP1 (horizontal) separa los estados de alta criminalidad (derecha) de los de baja (izquierda): Murder, Assault y Rape apuntan a la derecha, lo que significa que CP1 es un índice general de criminalidad. CP2 (vertical) está impulsado principalmente por UrbanPop: los estados con alta población urbana puntúan alto en CP2 independientemente de las tasas de criminalidad.
PCA vs LDA
Tanto el PCA como el LDA proyectan los datos en un espacio de menor dimensión, pero con objetivos distintos:
- PCA: no supervisado. Maximiza la varianza total de los datos proyectados. Ignora las etiquetas de clase. Útil para visualización, reducción de ruido y preprocesado.
- LDA: supervisado. Maximiza la varianza entre clases en relación con la varianza dentro de clase. Usa las etiquetas de clase. Útil cuando el objetivo es la clasificación o encontrar direcciones que separen clases conocidas.
Si las direcciones de máxima varianza resultan ser las mismas que las que separan las clases, el PCA y el LDA coinciden. Cuando la dirección más variable es ruido dentro de clase (p.ej., los individuos varían mucho dentro de cada clase pero las clases difieren en una dirección de baja varianza), el PCA no encuentra la estructura discriminante y se necesita el LDA.
⚠️ El PCA no garantiza componentes interpretables
Cada componente principal es una combinación lineal de todas las variables originales. Aunque CP1 captura el 60% de la varianza, puede ser una media ponderada de 20 variables con cargas similares: no hay garantía de que corresponda a un concepto científico significativo.
Técnicas como el PCA disperso (impone penalización L1 en las cargas para forzar la mayoría a cero) y la rotación varimax (rota las componentes para maximizar la simplicidad de la estructura de cargas) pueden mejorar la interpretabilidad, a costa de perder la propiedad de varianza máxima.
💡 PCA en R
# Ajustar PCA
pca <- prcomp(X, center=TRUE, scale.=TRUE)
summary(pca) # varianza explicada por componente
pca$rotation # cargas (vectores propios)
pca$x # puntuaciones (datos proyectados)
# Gráfico de sedimentación
plot(pca, type="l")
# Biplot
biplot(pca, scale=0)
# Elegir el número de componentes
cumsum(pca$sdev^2) / sum(pca$sdev^2) # PVE acumulado
# Proyectar nuevos datos sobre el PCA existente
predict(pca, newdata=X_new)
# PCA disperso para cargas interpretables
library(sparsepca)
spca <- spca(X, k=3, alpha=1e-3, beta=1e-3)
