What is sampling?
Sampling is the process of selecting a subset of individuals from a population to estimate characteristics of the whole. It is the bridge between data collection and statistical inference: almost every conclusion in science, medicine, and business is based on a sample rather than a complete census.
Key concepts
- Population
The population is the complete set of individuals, objects, or measurements about which we want to draw conclusions. It is defined by the research question, not by convenience.
- The population of interest for a drug trial might be “all adults over 18 with hypertension in Spain.”
- For a quality control study: “all units produced by Machine 3 during the night shift.”
- For a poll: “all registered voters in the upcoming election.”
The population is often too large, too expensive, or impossible to measure in full.
- Sample
A sample is the subset of the population that is actually observed. A good sample is:
- Representative: it reflects the characteristics of the population.
- Of adequate size: large enough to estimate the parameter with acceptable precision.
- Selected by a defined procedure: so the selection process can be evaluated and reproduced.
- Parameter vs statistic
A parameter is a numerical characteristic of the population (usually unknown): \(\mu\), \(\sigma^2\), \(p\). A statistic is the corresponding quantity computed from the sample: \(\bar{x}\), \(S^2\), \(\hat{p}\). Statistical inference uses statistics to estimate parameters.
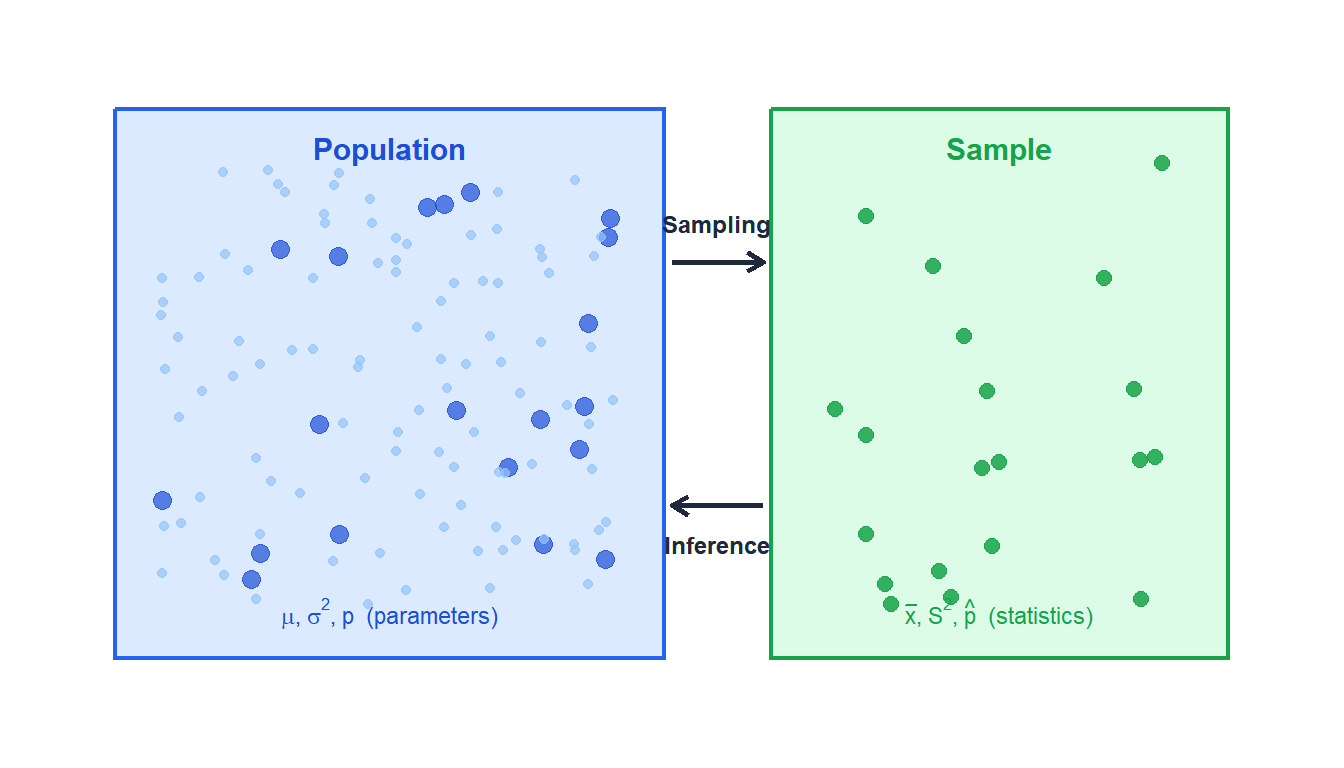
Why sample instead of census?
A census measures every unit in the population. In most situations this is impractical:
- Cost and time: interviewing every voter in a country, or testing every component from a production run.
- Destructive testing: measuring the breaking strength of a cable requires destroying it. You cannot test every unit.
- Infinite or dynamic populations: the population of future customers does not yet exist; the population of bacteria in a culture changes continuously.
- Accuracy: a well-designed sample with careful measurement can be more accurate than a poorly executed census with many measurement errors.
A properly drawn sample of 1,000 people can estimate the opinion of 40 million voters with a margin of error of ±3%.
Probability vs non-probability sampling
The most important distinction in sampling is whether each unit has a known, non-zero probability of being selected.
Probability sampling:
- Every unit has a known probability of selection.
- The selection is random.
- Sampling error can be quantified and controlled.
- Valid for statistical inference about the population.
- Examples: simple random, systematic, stratified, cluster.
Non-probability sampling:
- Selection probabilities are unknown.
- Relies on convenience, judgment, or volunteer response.
- Sampling error cannot be formally estimated.
- Results may not generalize to the population.
- Examples: convenience sampling, snowball sampling, purposive sampling.
⚠️ Non-probability samples cannot support valid statistical inference
Convenience samples (students in a psychology class, online volunteers, social media followers) are not representative of any well-defined population. Confidence intervals and p-values computed from convenience samples have no valid interpretation, because the formulas assume probability sampling. This does not mean convenience samples are useless: they are common in exploratory research, pilot studies, and qualitative work. But the conclusions must be stated as “among participants in this study,” not as generalizations to a population.
Sampling error vs bias
Two types of problems can affect sample-based estimates:
Sampling error
Random variation due to the fact that a sample, not the full population, is measured. It decreases as \(n\) increases (proportional to \(1/\sqrt{n}\)). It is unavoidable but quantifiable through the standard error and confidence intervals. With probability sampling, it can be controlled by choosing an appropriate \(n\).
Bias
Systematic error that pushes estimates in a consistent direction away from the true parameter. Unlike sampling error, it does not decrease with larger samples: a biased study of 1,000,000 people is still biased.
Common sources of bias:
- Selection bias: certain units are more likely to be included. Online polls attract self-selected respondents who feel strongly about an issue.
- Non-response bias: units that do not respond differ systematically from those that do. In health surveys, sicker people may be less able to participate.
- Measurement bias: the measurement instrument systematically over- or underestimates. A scale that reads 2 kg too heavy produces biased weight estimates regardless of sample size.
- Survivorship bias: only units that “survived” some selection process are available. Studying the performance of currently active companies misses those that went bankrupt.
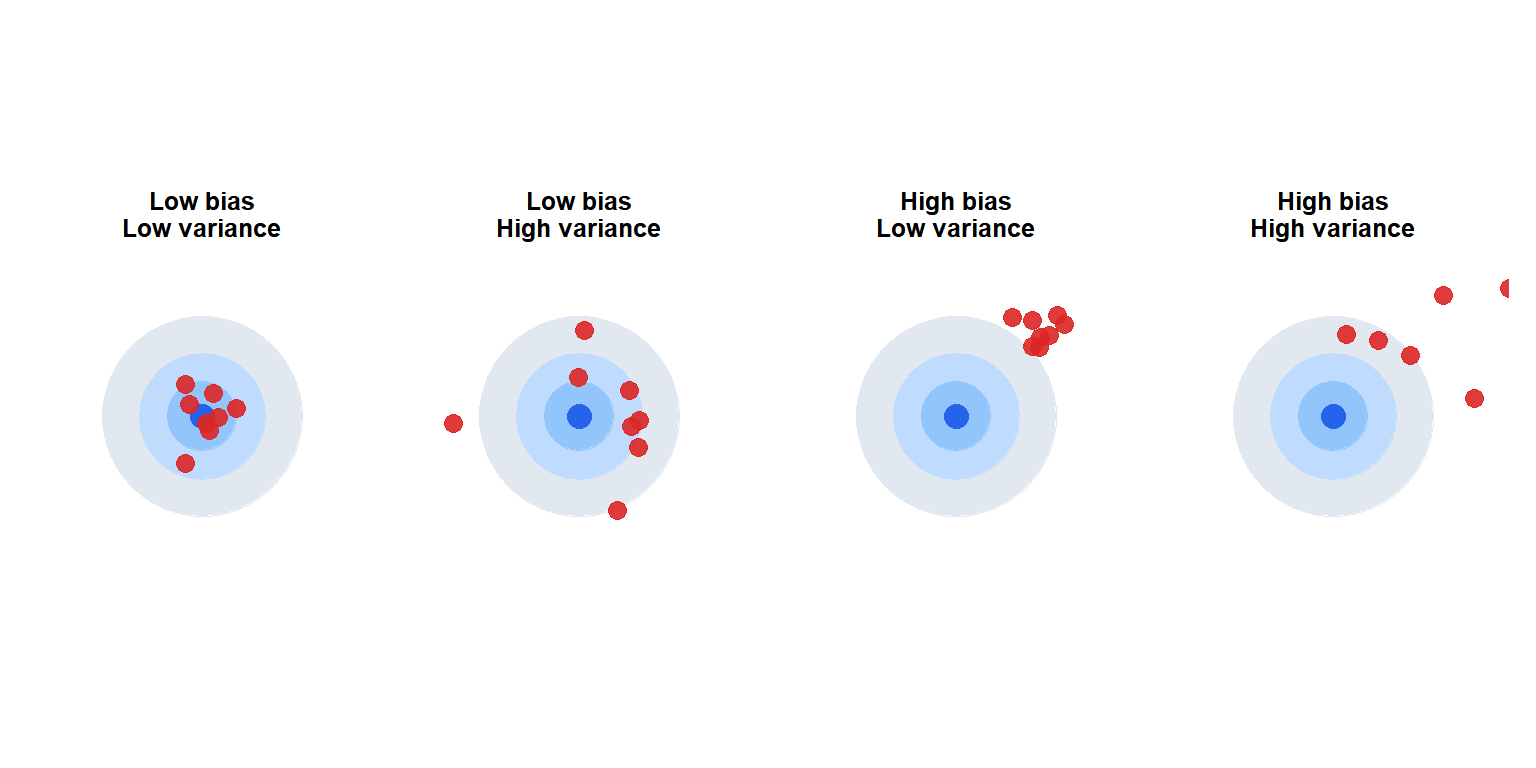
The ideal estimator (top-left) has both low bias and low variance. Increasing sample size moves estimates from high variance to low variance but does not fix bias.
Overview of sampling methods
The following posts in this section cover the main probability sampling methods:
| Method | When to use | Key property |
|---|---|---|
| Simple random | Homogeneous population, complete list available | Every unit equally likely |
| Systematic | Ordered list available, no periodicity | Every \(k\)-th unit selected |
| Stratified | Population has identifiable subgroups | Ensures representation of each stratum |
| Cluster | Population naturally grouped, no complete list | Groups selected, then all or some units within |
| Multistage | Large, geographically dispersed populations | Sequential selection of clusters and units |
💡 The choice of sampling method matters
A poorly chosen sampling method can introduce bias or inefficiency even with a large sample. Key questions before selecting a method:
- Is a complete list of the population (sampling frame) available?
- Is the population homogeneous or does it have identifiable subgroups?
- Are the units geographically concentrated or dispersed?
- What is the available budget and time?
Stratified sampling is more efficient than simple random when the population has distinct subgroups. Cluster sampling is more practical for geographically dispersed populations but typically less efficient per unit.

