Filtro de Kalman
El filtro de Kalman es un algoritmo recursivo que estima el estado oculto de un sistema dinámico a partir de observaciones ruidosas. Es óptimo bajo supuestos gaussianos: ningún otro estimador lineal tiene menor error cuadrático medio. Desarrollado originalmente para la navegación aeroespacial, hoy es fundamental en econometría, procesamiento de señales, robótica y análisis de series de tiempo.
El modelo en espacio de estados
El filtro de Kalman opera sobre sistemas descritos por dos ecuaciones:
\[\alpha_{t+1} = T_t \alpha_t + R_t \eta_t \qquad \text{(ecuación de transición)}\]
\[y_t = Z_t \alpha_t + \varepsilon_t \qquad \text{(ecuación de observación)}\]
donde:
- \(\alpha_t\): el vector de estado (no observable). Contiene las cantidades que queremos estimar: posición, nivel, tendencia, componentes estacionales.
- \(y_t\): la observación (medida ruidosa de \(\alpha_t\)).
- \(T_t\): matriz de transición que gobierna cómo evoluciona el estado en el tiempo.
- \(Z_t\): matriz de observación que relaciona el estado con la observación.
- \(\eta_t \sim N(0, Q_t)\): ruido de estado (ruido de proceso).
- \(\varepsilon_t \sim N(0, H_t)\): ruido de observación (ruido de medición).
- \(\eta_t\) y \(\varepsilon_t\) son mutuamente independientes.
La relación \(Q/H\) controla el equilibrio entre confiar en la dinámica del modelo (\(Q\) grande) y confiar en las observaciones (\(H\) grande).
El algoritmo predicción-actualización
El filtro de Kalman se ejecuta recursivamente en cada instante \(t\):
Predicción (propagar el estado hacia adelante con la ecuación de transición):
\[\hat{\alpha}_{t|t-1} = T_t \hat{\alpha}_{t-1|t-1}\]
\[P_{t|t-1} = T_t P_{t-1|t-1} T_t' + R_t Q_t R_t'\]
Actualización (incorporar la nueva observación \(y_t\)):
\[v_t = y_t - Z_t \hat{\alpha}_{t|t-1} \qquad \text{(innovación)}\]
\[F_t = Z_t P_{t|t-1} Z_t' + H_t \qquad \text{(varianza de la innovación)}\]
\[K_t = P_{t|t-1} Z_t' F_t^{-1} \qquad \text{(ganancia de Kalman)}\]
\[\hat{\alpha}_{t|t} = \hat{\alpha}_{t|t-1} + K_t v_t\]
\[P_{t|t} = (I - K_t Z_t) P_{t|t-1}\]
La ganancia de Kalman \(K_t\) controla el peso que se da a la nueva observación frente a la predicción:
- \(K_t \to 0\) (\(H_t\) pequeño, \(Q_t\) grande): confía en el modelo; ignora la nueva observación.
- \(K_t \to 1\) (\(H_t\) grande, \(Q_t\) pequeño): confía en la observación; actualiza mucho el estado.
La innovación \(v_t = y_t - Z_t\hat{\alpha}_{t|t-1}\) es el error de predicción a un paso. Bajo el modelo correcto, las innovaciones son ruido blanco con varianza \(F_t\).
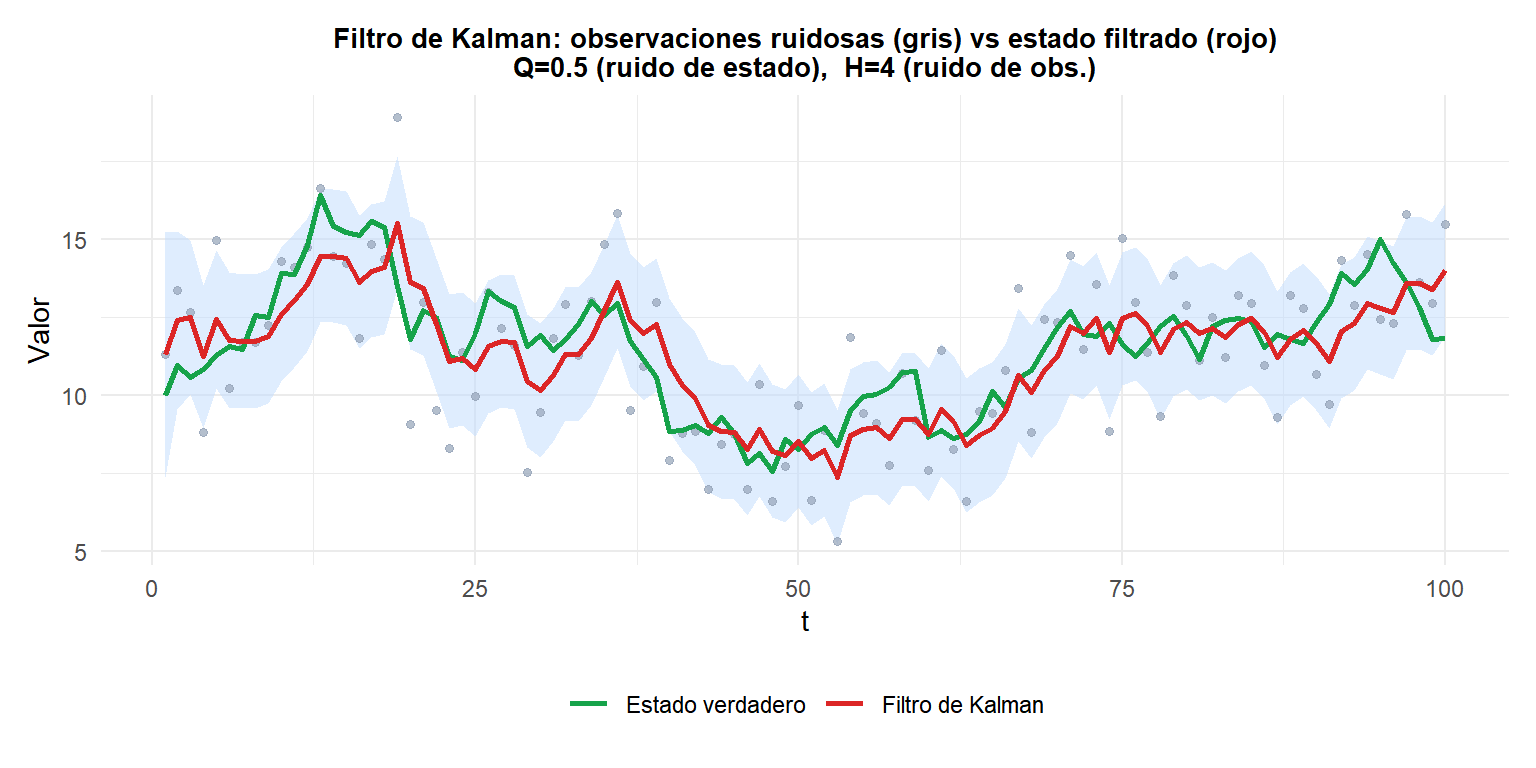
Puntos grises: observaciones ruidosas. Verde: estado subyacente verdadero (paseo aleatorio). Rojo: estimación del filtro de Kalman con banda de incertidumbre al 95%. El filtro sigue de cerca el estado verdadero a pesar del elevado ruido de observación.
El equilibrio Q/H
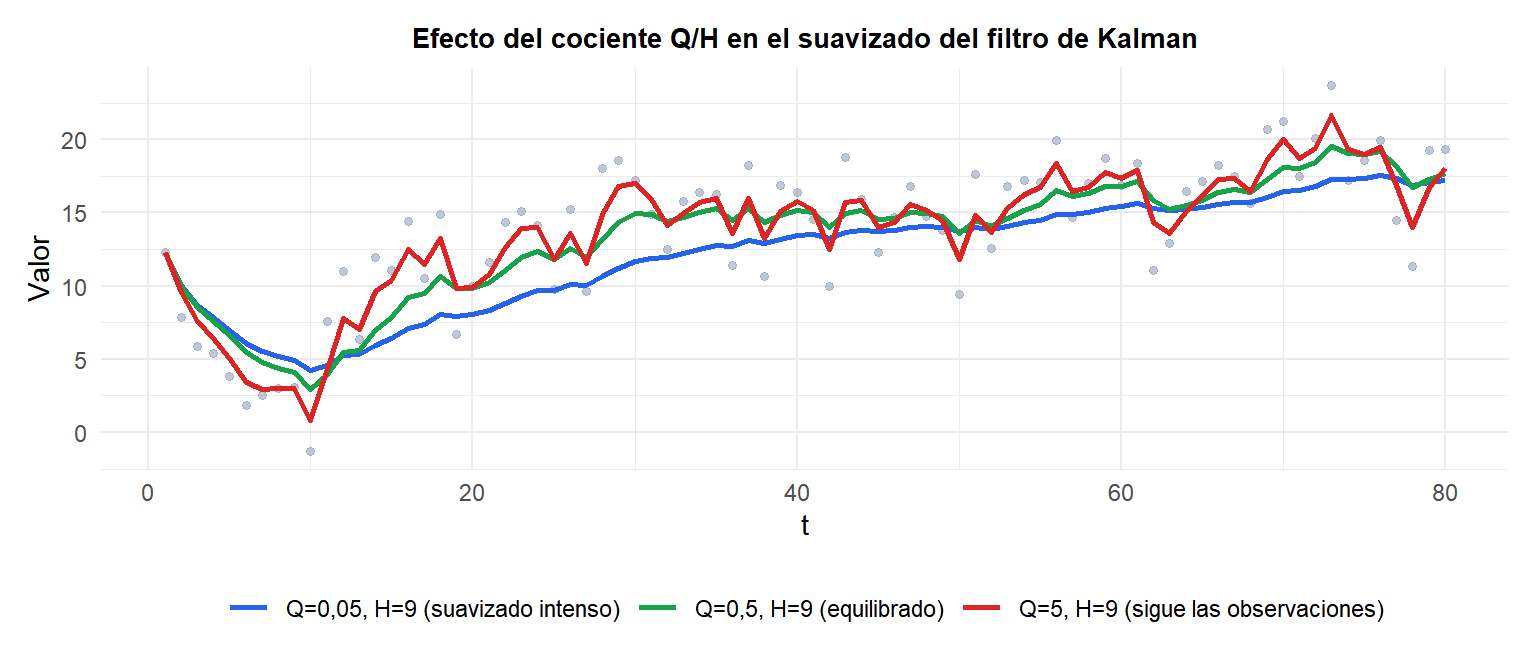
Un Q/H bajo (azul) produce un suavizado intenso: el filtro reacciona lentamente a los cambios. Un Q/H alto (rojo) sigue de cerca las observaciones. Los valores óptimos de Q y H se estiman a partir de los datos por máxima verosimilitud.
Conexión con ARIMA
Todo modelo ARIMA tiene una representación exacta en espacio de estados. Por ejemplo, ARIMA(1,1,1):
\[\alpha_t = \begin{pmatrix}\mu_t \\ b_t\end{pmatrix}, \quad T = \begin{pmatrix}1 & 1 \\ 0 & 1\end{pmatrix}, \quad Z = \begin{pmatrix}1 & 0\end{pmatrix}\]
Esto permite ajustar modelos ARIMA usando el filtro de Kalman, que gestiona:
- Datos faltantes: el paso de actualización simplemente se omite cuando falta \(y_t\).
- Cálculo exacto de la verosimilitud: las innovaciones \(v_t\) y sus varianzas \(F_t\) dan directamente la log-verosimilitud gaussiana: \(\ell = -\frac{1}{2}\sum_t (\log F_t + v_t^2/F_t)\).
- Inicialización no estacionaria: las distribuciones a priori difusas gestionan componentes \(I(1)\) o \(I(2)\) sin necesidad de prediferenciar.
Las funciones stats::arima() y forecast::Arima() de R usan el filtro de Kalman internamente.
Filtrado, suavizado y predicción
El filtro de Kalman produce tres tipos de estimaciones del estado:
- Estimación filtrada \(\hat{\alpha}_{t|t}\): usa todos los datos hasta \(t\). Estimación en tiempo real.
- Estimación suavizada \(\hat{\alpha}_{t|T}\): usa todos los datos hasta \(T > t\). Retrospectiva; siempre más precisa que la filtrada.
- Predicción \(\hat{\alpha}_{t+h|t}\): proyecta hacia adelante desde \(t\) usando solo la ecuación de transición.
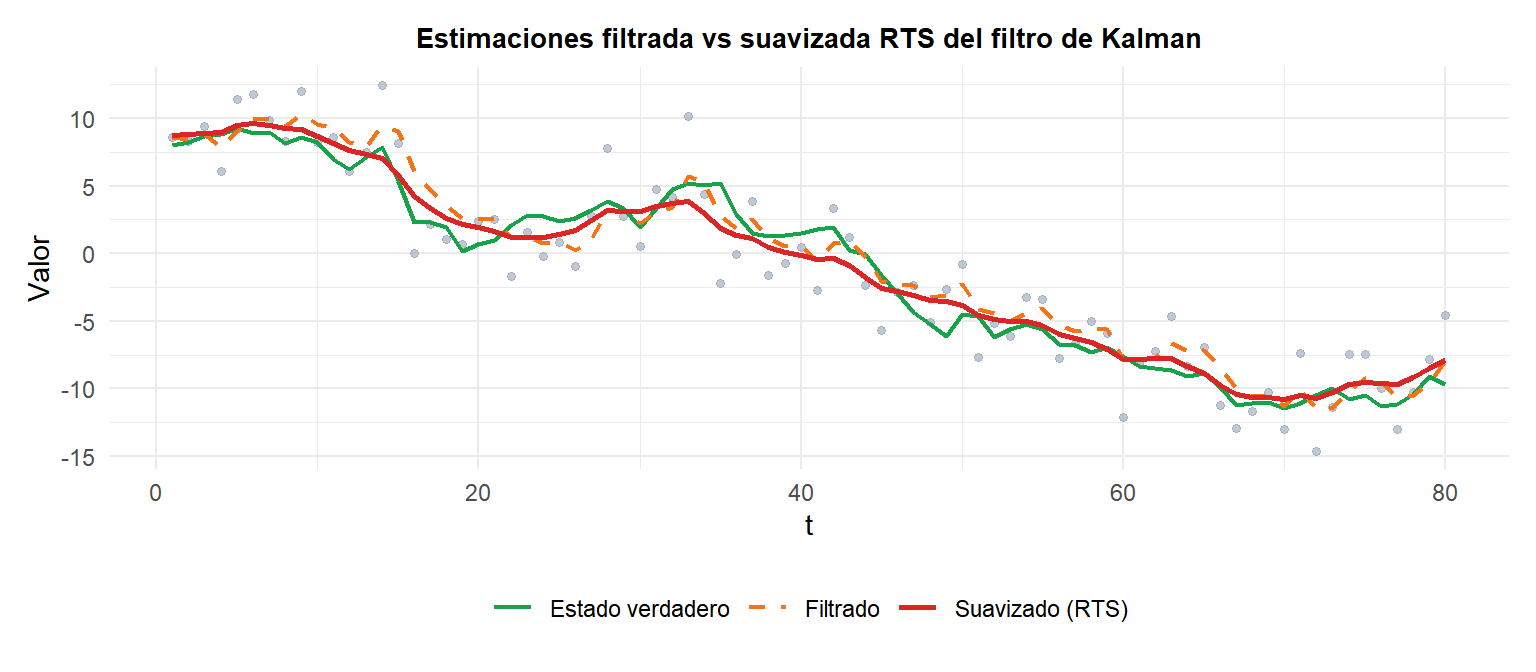
La estimación suavizada (rojo) está siempre más cerca del estado verdadero que la estimación filtrada (naranja) porque usa las \(T\) observaciones, no solo las disponibles hasta \(t\).
⚠️ Los valores mal especificados de Q y H producen un filtrado deficiente
El filtro de Kalman es óptimo solo cuando Q y H están correctamente especificados. Problemas habituales:
- Q demasiado pequeño: el filtro está sobreconfiado en sus predicciones y es lento para seguir cambios reales en el estado.
- H demasiado pequeño: el filtro confía demasiado en las observaciones, produciendo estimaciones ruidosas que siguen cada fluctuación de medición.
- Ambos mal especificados: la secuencia de innovaciones \(v_t\) no será ruido blanco. Comprueba siempre la ACF de las innovaciones tras el ajuste.
Estima Q y H por máxima verosimilitud (maximiza \(\ell = -\frac{1}{2}\sum_t (\log F_t + v_t^2/F_t)\)) usando optimización numérica. En R, dlm::dlmMLE() o KFAS::fitSSM() lo hacen automáticamente.
💡 Filtro de Kalman en R
# A través de ARIMA (el filtro de Kalman se usa internamente)
arima(y, order = c(1,1,1))
# Espacio de estados explícito con el paquete dlm
library(dlm)
model <- dlmModPoly(order = 1, dV = H, dW = Q) # modelo de nivel local
filtered <- dlmFilter(y, model)
smoothed <- dlmSmooth(filtered)
# Paquete KFAS (más flexible)
library(KFAS)
model <- SSModel(y ~ SSMtrend(1, Q = Q), H = H)
out <- KFS(model) # filtrado + suavizado en una sola llamada
