Bootstrap uniforme
El bootstrap uniforme, también llamado bootstrap no paramétrico o bootstrap naive, es la forma estándar de remuestreo bootstrap. Cada observación de la muestra original recibe igual probabilidad \(1/n\) de ser extraída en cada paso, por lo que las muestras bootstrap se extraen de la distribución empírica \(\hat{F}_n\). Es el método descrito en el artículo original de Efron de 1979 y el predeterminado en la mayoría del software.
Definición
Dada una muestra original \(\mathbf{x} = (x_1, \ldots, x_n)\), el bootstrap uniforme genera remuestras extrayendo \(n\) observaciones de forma independiente y con reemplazamiento, eligiendo cada una de forma uniforme de \(\{x_1, \ldots, x_n\}\).
Esto equivale a muestrear de la distribución empírica \(\hat{F}_n\), que asigna masa de probabilidad \(1/n\) a cada valor observado:
\[\hat{F}_n(x) = \frac{1}{n} \sum_{i=1}^n \mathbf{1}(x_i \leq x)\]
El término “uniforme” hace referencia a los pesos uniformes \(w_i = 1/n\) asignados a cada observación. Esto lo distingue del bootstrap suavizado (que añade ruido a los valores remuestreados) y del bootstrap paramétrico (que muestrea de una distribución paramétrica ajustada).
La representación con pesos multinomiales
Cada remuestra bootstrap puede caracterizarse mediante un vector de pesos \((m_1, m_2, \ldots, m_n)\), donde \(m_i\) es el número de veces que la observación \(x_i\) aparece en la remuestra. Estos recuentos siguen una distribución multinomial:
\[(m_1, m_2, \ldots, m_n) \sim \text{Multinomial}\!\left(n;\; \frac{1}{n}, \frac{1}{n}, \ldots, \frac{1}{n}\right)\]
Esto implica que:
- \(E[m_i] = 1\): en promedio, cada observación aparece una vez.
- \(\text{Var}(m_i) = (n-1)/n \approx 1\) para \(n\) grande.
- Aproximadamente \(1 - (1-1/n)^n \approx 1 - e^{-1} \approx 63{,}2\%\) de las observaciones aparecen al menos una vez en cualquier remuestra bootstrap. El \(\approx 36{,}8\%\) restante queda fuera.
Las observaciones fuera de bolsa (OOB, por sus siglas en inglés), es decir las no incluidas en una remuestra, pueden usarse para validar modelos sin necesidad de un conjunto de prueba separado. Esta propiedad es clave en los bosques aleatorios y los estimadores por agregación (bagging).
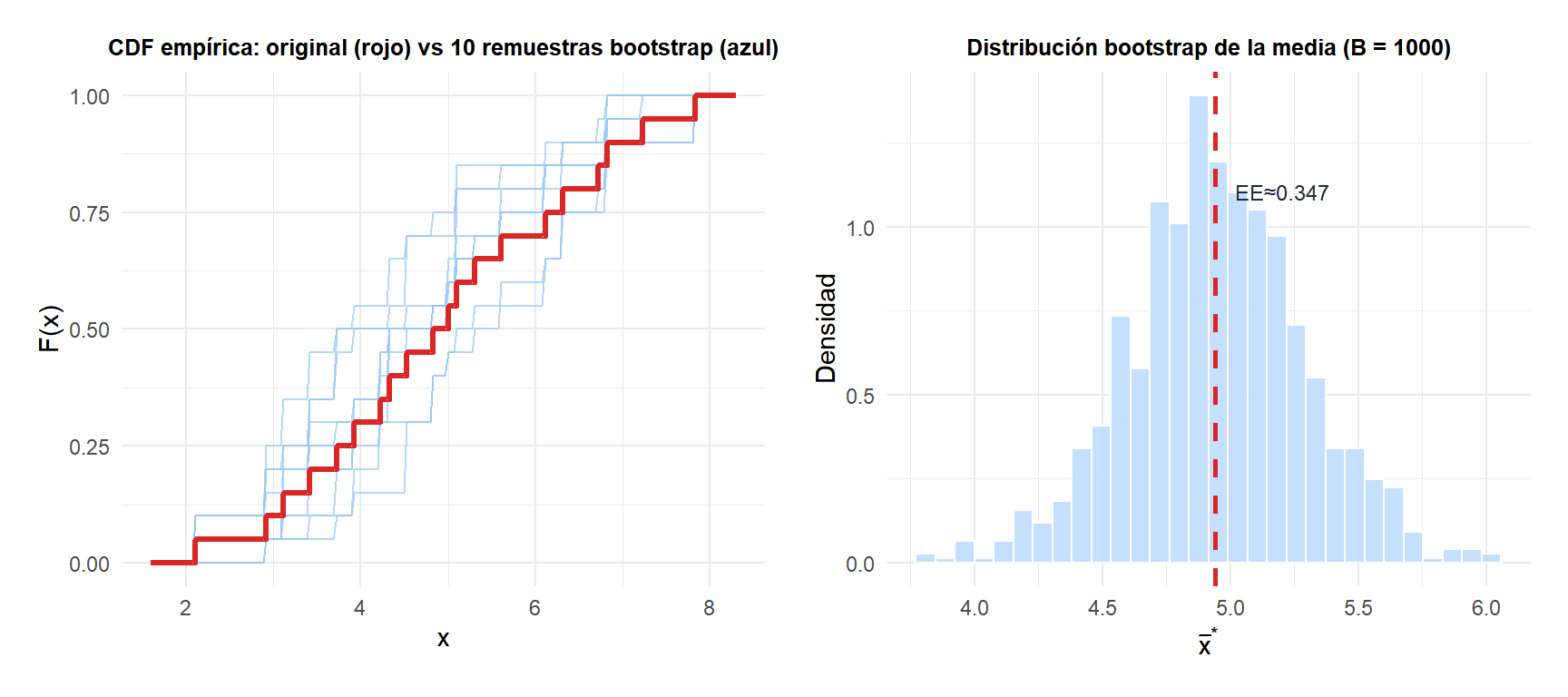
El panel izquierdo muestra cómo cada CDF empírica bootstrap (azul) fluctúa alrededor de la CDF original (rojo): esta variabilidad es exactamente lo que usa el bootstrap para estimar la incertidumbre. El panel derecho muestra la distribución bootstrap resultante de la media muestral.
Ejemplo completo
Un ingeniero de fiabilidad registra el tiempo hasta el fallo (horas) de 15 componentes electrónicos:
\[x = (120, 95, 142, 108, 87, 155, 131, 99, 167, 113, 78, 144, 102, 138, 91)\]
La media observada es \(\bar{x} = 117{,}9\) horas. El EE teórico de la media para una distribución exponencial requeriría conocer el parámetro de tasa. En su lugar, se usa el bootstrap uniforme.
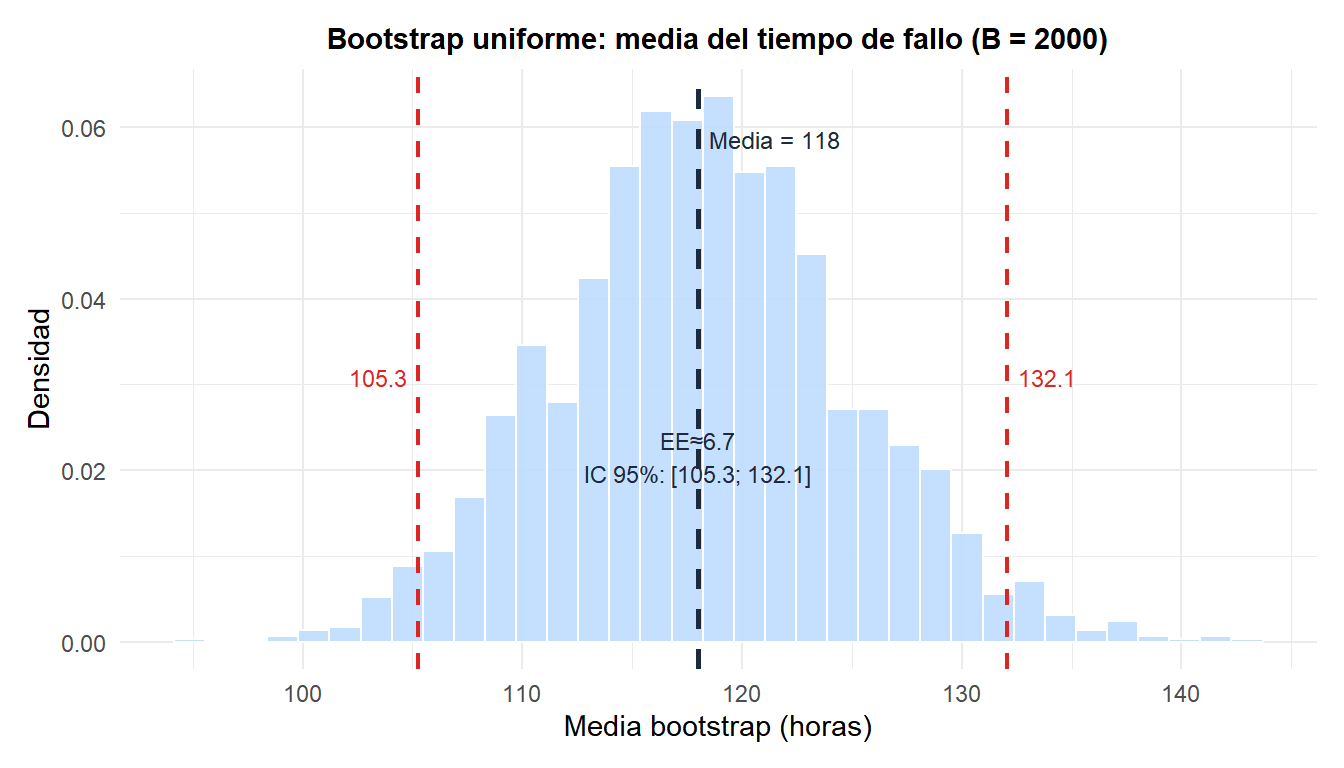
EE bootstrap \(\approx\) 6.6 horas. El IC percentil al 95% da los límites mostrados en rojo.
Bootstrap uniforme vs otras variantes
| Uniforme | Suavizado | Paramétrico | |
|---|---|---|---|
| Remuestrea de | \(\hat{F}_n\) (empírica) | \(\hat{F}_n\) + ruido | \(F_\theta\) ajustada |
| Asume distribución | No | No | Sí |
| Para \(n\) pequeño | Moderado | Mejor | Mejor (si correcto) |
| Para datos continuos | Discretiza | Correcto | Correcto |
| Por defecto en la práctica | Sí | Raramente | Habitual en modelización |
El bootstrap uniforme es el predeterminado porque no requiere supuestos. Su principal debilidad es que la distribución empírica \(\hat{F}_n\) es discreta incluso cuando la población es continua, lo que puede subestimar la variabilidad en muestras pequeñas. El bootstrap suavizado aborda esto.
💡 La regla del 63,2% y la estimación fuera de bolsa
En cualquier remuestra del bootstrap uniforme, aproximadamente \(1 - e^{-1} \approx 63{,}2\%\) de las observaciones originales aparecen al menos una vez. El \(36{,}8\%\) restante queda fuera de bolsa (OOB). Esta propiedad se usa en los bosques aleatorios: cada árbol se entrena con una remuestra bootstrap y sus observaciones OOB sirven como conjunto de validación integrado. La estimación del error OOB es casi equivalente a la validación cruzada dejando uno fuera, sin el coste computacional que ello implica.

