Método de Newton y BFGS
El método de Newton usa información de segundo orden (la matriz hessiana) para dar pasos curvos hacia el óptimo, logrando convergencia cuadrática: el número de dígitos correctos se duplica aproximadamente en cada iteración. BFGS aproxima el hessiano a partir únicamente de diferencias de gradientes, obteniendo una convergencia cercana a la de Newton sin el coste \(O(n^3)\) de invertir una matriz densa.
El método de Newton
El descenso del gradiente usa solo el gradiente: avanza en la dirección de mayor descenso con un tamaño de paso fijo. Esto ignora la curvatura de \(f\): en las direcciones donde la función es muy pronunciada, el paso es demasiado grande y el algoritmo oscila; en las direcciones planas, es demasiado pequeño.
El método de Newton ajusta una aproximación cuadrática local a \(f\) en \(x_k\) usando la expansión de Taylor de segundo orden:
\[f(x) \approx f(x_k) + \nabla f(x_k)^T(x - x_k) + \frac{1}{2}(x-x_k)^T \nabla^2 f(x_k)(x-x_k)\]
Minimizar esta cuadrática en \(x\) da el paso de Newton:
\[x_{k+1} = x_k - \left[\nabla^2 f(x_k)\right]^{-1} \nabla f(x_k)\]
\[p_k = -H_k^{-1} g_k \qquad \text{donde } H_k = \nabla^2 f(x_k),\; g_k = \nabla f(x_k)\]
El hessiano \(H_k\) escala el gradiente por la curvatura local: en las direcciones pronunciadas (valores propios grandes de \(H_k\)) el paso es pequeño; en las direcciones planas (valores propios pequeños) el paso es grande. Esto adapta automáticamente el tamaño del paso a la geometría de \(f\).
Convergencia cuadrática
Cerca de un mínimo local no degenerado \(x^*\) donde \(H^* = \nabla^2 f(x^*)\) es definido positivo, el método de Newton converge de forma cuadrática:
\[\|x_{k+1} - x^*\| \leq C \|x_k - x^*\|^2\]
para alguna constante \(C > 0\). Si el error en el paso \(k\) es \(\varepsilon\), el error en el paso \(k+1\) es aproximadamente \(C\varepsilon^2\). Esto significa que el número de dígitos decimales correctos se duplica en cada iteración: si tienes 2 dígitos correctos, el siguiente paso da 4, luego 8, luego 16.
Compáralo con la convergencia lineal del descenso del gradiente, \(\|x_{k+1} - x^*\| \leq \rho \|x_k - x^*\|\) para algún \(\rho < 1\): los errores disminuyen en un factor constante, no se elevan al cuadrado.
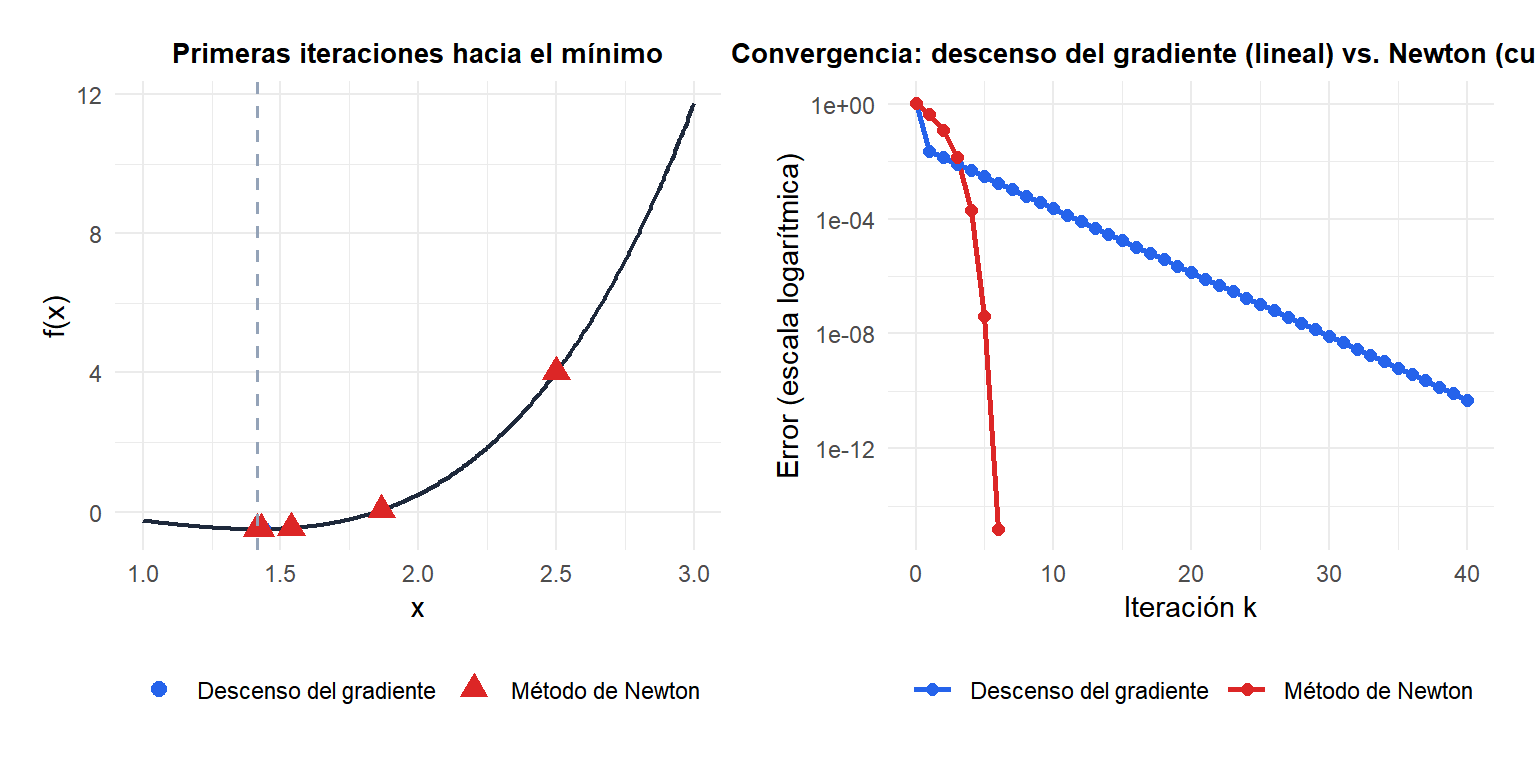
El método de Newton (rojo) alcanza la precisión de máquina en 6 iteraciones. El descenso del gradiente (azul) aún tiene un error apreciable tras 40 iteraciones.
Limitaciones del método de Newton
A pesar de su convergencia cuadrática, el método de Newton tiene tres limitaciones prácticas importantes:
Coste por iteración: calcular \(H_k\) requiere \(O(n^2)\) entradas; resolver \(H_k p_k = -g_k\) requiere \(O(n^3)\) operaciones (factorización LU o de Cholesky). Para \(n = 10^4\) parámetros (una red neuronal pequeña), esto supone \(10^{12}\) operaciones por paso: completamente inviable.
Indefinitud del hessiano: lejos del óptimo, \(H_k\) puede no ser definido positivo. El paso de Newton \(p_k = -H_k^{-1}g_k\) puede entonces apuntar hacia arriba. Los métodos de Newton modificados añaden un término de regularización: \(p_k = -(H_k + \lambda_k I)^{-1}g_k\) con \(\lambda_k\) elegido para garantizar la definición positiva (estrategia de Levenberg-Marquardt).
Convergencia solo local: la convergencia cuadrática solo está garantizada cerca de \(x^*\). Partiendo de un punto lejano, el método de Newton puede diverger o ciclar. Conviene combinarlo siempre con una búsqueda lineal o una región de confianza para garantizar la convergencia global.
⚠️ Los pasos de Newton pueden diverger sin salvaguardas
Un paso de Newton puro sin búsqueda lineal puede pasarse del mínimo y diverger, especialmente cuando el hessiano es casi singular o indefinido. En la práctica, el método de Newton se implementa siempre con una búsqueda lineal con retroceso (reducir el tamaño del paso hasta lograr un descenso suficiente) o con una región de confianza (restringir la norma del paso a una bola donde la aproximación cuadrática es fiable).
Métodos cuasi-Newton
Los métodos cuasi-Newton aproximan el hessiano (o su inversa) a partir de diferencias de gradientes, evitando el cálculo explícito de las derivadas de segundo orden. Logran convergencia superlineal: más lenta que la cuadrática de Newton, pero mucho más rápida que la convergencia lineal del descenso del gradiente.
La idea clave: usar el cambio en el gradiente entre iteradas sucesivas para actualizar la aproximación del hessiano. Si \(s_k = x_{k+1} - x_k\) e \(y_k = g_{k+1} - g_k\), la aproximación actualizada \(B_{k+1}\) debe satisfacer la condición de secante:
\[B_{k+1} s_k = y_k\]
Esto garantiza que la aproximación es coherente con la curvatura observada en la dirección del último paso.
Actualización BFGS
La actualización Broyden-Fletcher-Goldfarb-Shanno (BFGS) es el método cuasi-Newton más exitoso. Actualiza directamente la aproximación de la inversa del hessiano \(H_k^{-1} \approx B_k^{-1}\):
\[B_{k+1}^{-1} = \left(I - \rho_k s_k y_k^T\right) B_k^{-1} \left(I - \rho_k y_k s_k^T\right) + \rho_k s_k s_k^T\]
\[\rho_k = \frac{1}{y_k^T s_k}\]
La actualización BFGS es una actualización de rango 2 de la inversa del hessiano: incorpora información del paso actual y del cambio en el gradiente. Propiedades clave:
- Preserva la simetría: \(B_{k+1}^{-1}\) es simétrica si \(B_k^{-1}\) lo es.
- Preserva la definición positiva (cuando \(y_k^T s_k > 0\), garantizado por una búsqueda lineal de Wolfe).
- Requiere solo \(O(n^2)\) de almacenamiento y \(O(n^2)\) operaciones por actualización.
- Converge de forma superlineal: \(\|x_{k+1} - x^*\| = o(\|x_k - x^*\|)\), lo que significa que la propia tasa de convergencia mejora en cada paso.
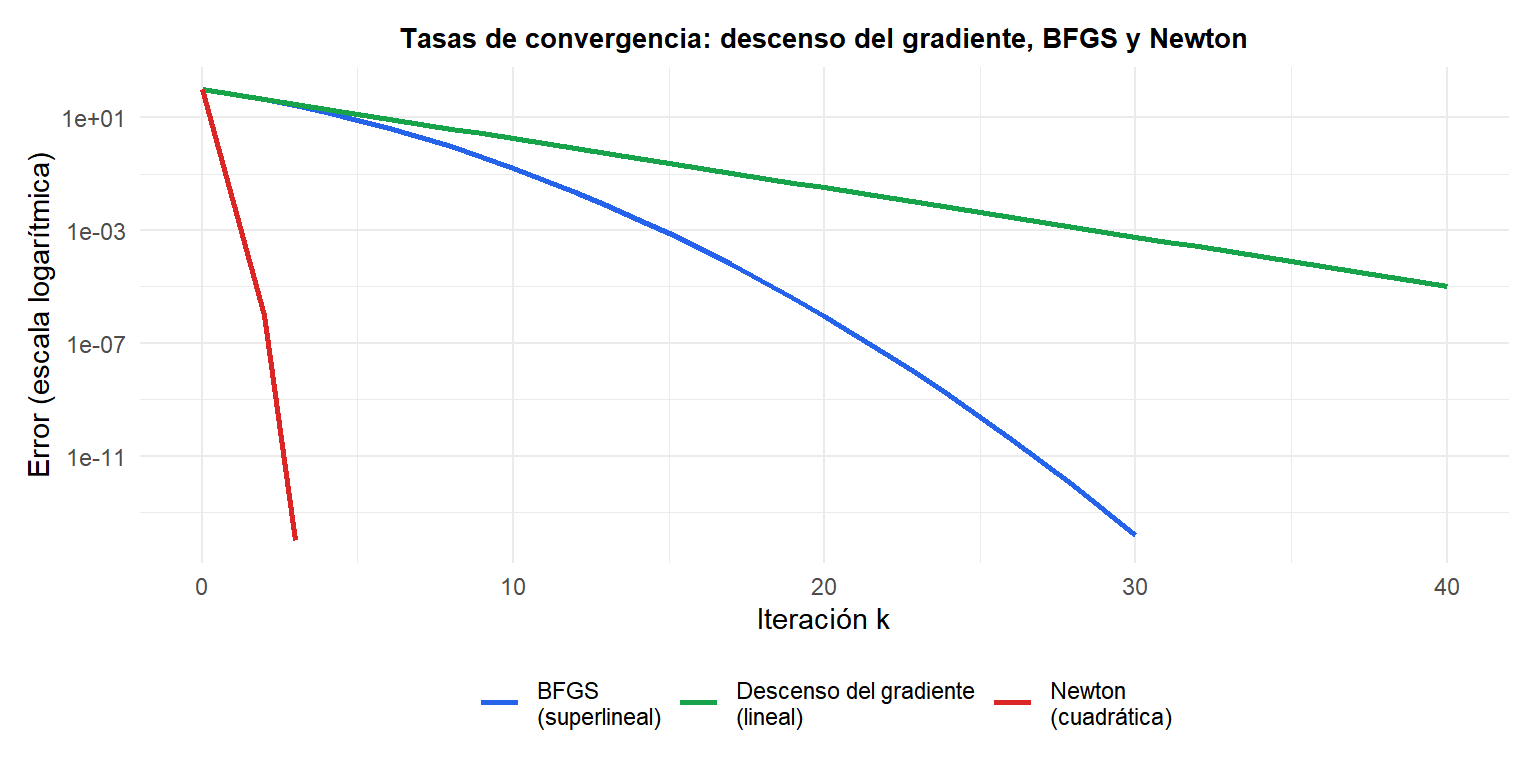
BFGS (azul) se sitúa entre el descenso del gradiente (verde, lineal lento) y Newton (rojo, cuadrático): converge mucho más rápido que el descenso del gradiente sin el coste \(O(n^3)\) de Newton.
L-BFGS: cuasi-Newton a gran escala
BFGS almacena la aproximación completa \(n \times n\) de la inversa del hessiano, lo que requiere \(O(n^2)\) de memoria. Para \(n = 10^6\) parámetros (un modelo típico de deep learning), esto es completamente inviable.
L-BFGS (Limited-memory BFGS) almacena solo los últimos \(m\) pares de curvatura \(\{(s_k, y_k)\}_{k=t-m}^{t-1}\) (típicamente \(m = 5\) a 20) y representa implícitamente la aproximación del hessiano a través de esos pares. El producto matriz-vector \(B_k^{-1} g_k\) se calcula mediante una recursión de dos bucles en tiempo \(O(mn)\) y memoria \(O(mn)\).
L-BFGS es el algoritmo estándar para optimización no restringida suave a gran escala. Se usa en regresión logística, ajuste de procesos gaussianos y muchas aplicaciones de machine learning donde el hessiano es demasiado grande para almacenarse.
| Método | Convergencia | Coste/iteración | Memoria | Ideal para |
|---|---|---|---|---|
| Descenso del gradiente | Lineal | \(O(n)\) | \(O(n)\) | \(n\) muy grande, no suave |
| BFGS | Superlineal | \(O(n^2)\) | \(O(n^2)\) | \(n\) medio (\(\leq 10^4\)) |
| L-BFGS | Superlineal | \(O(mn)\) | \(O(mn)\) | \(n\) grande (\(> 10^4\)) |
| Newton | Cuadrática | \(O(n^3)\) | \(O(n^2)\) | \(n\) pequeño (\(\leq 10^3\)), hessiano exacto disponible |
Búsqueda lineal y condiciones de Wolfe
Todos los métodos cuasi-Newton requieren una búsqueda lineal en cada paso para elegir el tamaño de paso \(\alpha_k\). Las condiciones de Wolfe son el estándar:
Descenso suficiente (Armijo): \(f(x_k + \alpha_k p_k) \leq f(x_k) + c_1 \alpha_k g_k^T p_k\)
Condición de curvatura: \(g(x_k + \alpha_k p_k)^T p_k \geq c_2 g_k^T p_k\)
con \(0 < c_1 < c_2 < 1\) (típicamente \(c_1 = 10^{-4}\), \(c_2 = 0{,}9\)). La condición de curvatura garantiza que \(y_k^T s_k > 0\), necesario para que BFGS mantenga la definición positiva de la aproximación del hessiano.
💡 Newton y BFGS en R
# optim() implementa BFGS y L-BFGS-B
f <- function(x) x[1]^4/4 - x[1]^2 + x[2]^2
grad_f <- function(x) c(x[1]^3 - 2*x[1], 2*x[2])
# BFGS
optim(c(2, 1), f, grad_f, method="BFGS")
# L-BFGS-B (con restricciones de caja)
optim(c(2, 1), f, grad_f, method="L-BFGS-B",
lower=c(-Inf,-Inf), upper=c(Inf,Inf))
# Método de Newton via nlm()
nlm(f, c(2, 1), hessian=TRUE)
# Para problemas restringidos: nloptr con BFGS
library(nloptr)
nloptr(x0=c(2,1), eval_f=f, eval_grad_f=grad_f,
opts=list(algorithm="NLOPT_LD_LBFGS"))En la práctica, proporciona siempre el gradiente de forma analítica cuando sea posible: la diferenciación numérica es más lenta y menos precisa.

