Introducción a la optimización
La optimización matemática busca los valores de las variables de decisión que minimizan o maximizan una función objetivo, posiblemente sujeta a restricciones. Es la base del machine learning, la investigación operativa, la economía y el diseño en ingeniería.
El problema de optimización
La forma general de un problema de optimización es:
\[\min_{x \in \mathcal{X}} f(x) \quad \text{sujeto a} \quad g_i(x) \leq 0,\; i=1,\ldots,m \quad h_j(x) = 0,\; j=1,\ldots,p\]
donde:
- \(x \in \mathbb{R}^n\): variables de decisión (lo que controlamos).
- \(f: \mathbb{R}^n \to \mathbb{R}\): función objetivo (lo que optimizamos).
- \(g_i(x) \leq 0\): restricciones de desigualdad (frontera de la región factible).
- \(h_j(x) = 0\): restricciones de igualdad (deben satisfacerse de forma exacta).
- \(\mathcal{X}\): conjunto factible (todos los \(x\) que satisfacen las restricciones).
Un problema de maximización \(\max f(x)\) es equivalente a \(\min -f(x)\).
Ejemplos en distintos ámbitos:
- Machine learning: minimizar la función de pérdida \(f(\theta) = \frac{1}{n}\sum_i \ell(y_i, \hat{y}_i(\theta))\) sobre los parámetros del modelo \(\theta\).
- Optimización de carteras: maximizar el rendimiento esperado sujeto a una restricción de varianza.
- Planificación de rutas: minimizar el tiempo de desplazamiento sujeto a las restricciones de la red de carreteras.
- Planificación de la producción: maximizar el beneficio sujeto a las restricciones de capacidad de recursos.
Taxonomía de problemas de optimización
Continuo vs discreto
- Continuo: \(x \in \mathbb{R}^n\). Son aplicables los métodos basados en gradiente. Ejemplos: entrenamiento de redes neuronales, regresión.
- Discreto (combinatorio): \(x \in \mathbb{Z}^n\) o \(x \in \{0,1\}^n\). Mucho más difícil en general. Ejemplos: planificación, enrutamiento, programación entera.
- Mixto-entero: algunas variables son continuas y otras discretas.
Con restricciones vs sin restricciones
- Sin restricciones: \(\mathcal{X} = \mathbb{R}^n\). La optimalidad se caracteriza únicamente mediante derivadas.
- Con restricciones: el conjunto factible es un subconjunto propio de \(\mathbb{R}^n\). Requiere multiplicadores de Lagrange o condiciones KKT.
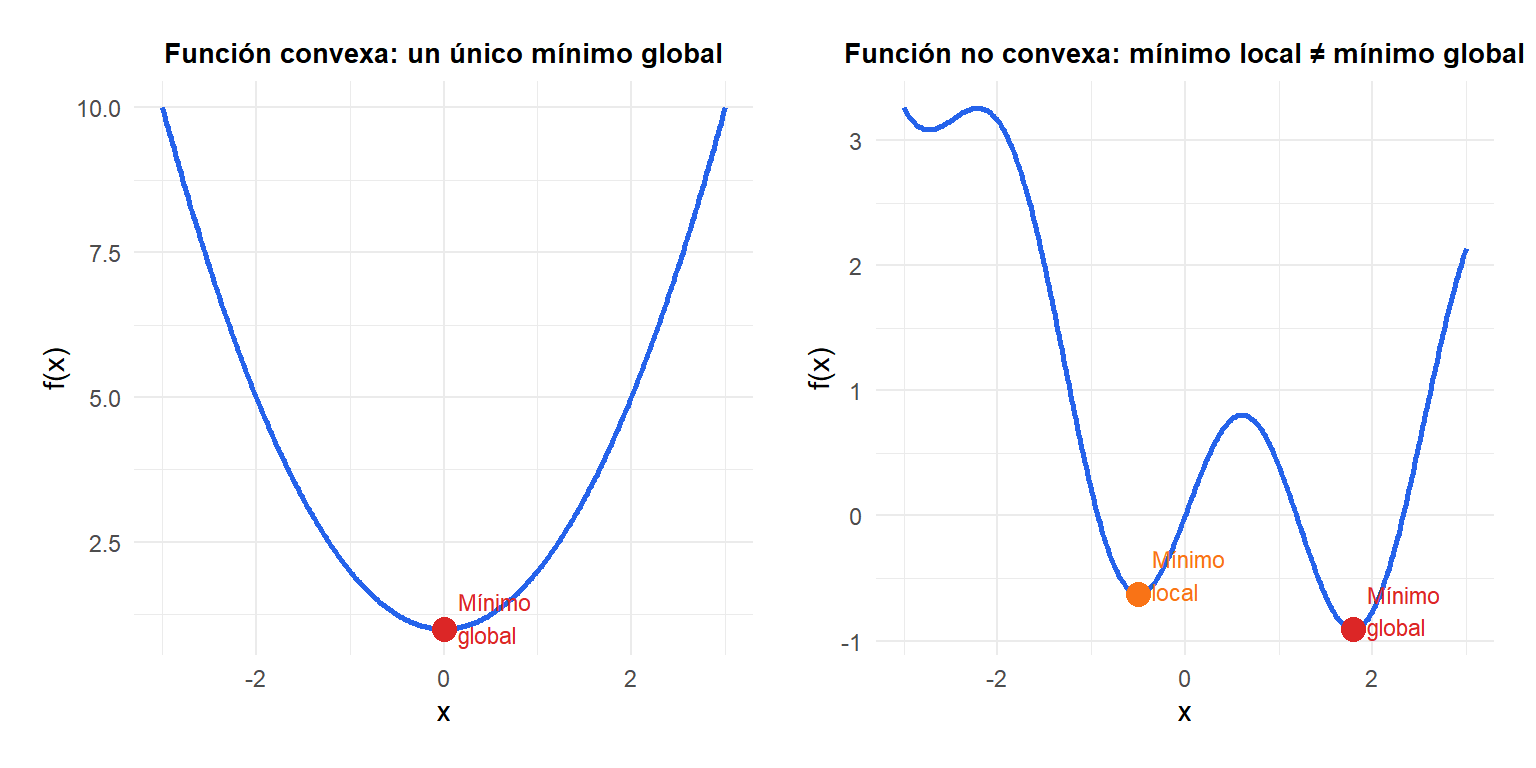
Convexo vs no convexo
La distinción más importante en la práctica:
- Convexo: \(f\) es convexa y \(\mathcal{X}\) es un conjunto convexo. Todo mínimo local es también global. Existen algoritmos eficientes con garantías de convergencia.
- No convexo: pueden existir múltiples mínimos locales. No hay garantía de que ningún algoritmo encuentre el mínimo global. La mayoría de problemas de deep learning son no convexos.
Condiciones de optimalidad
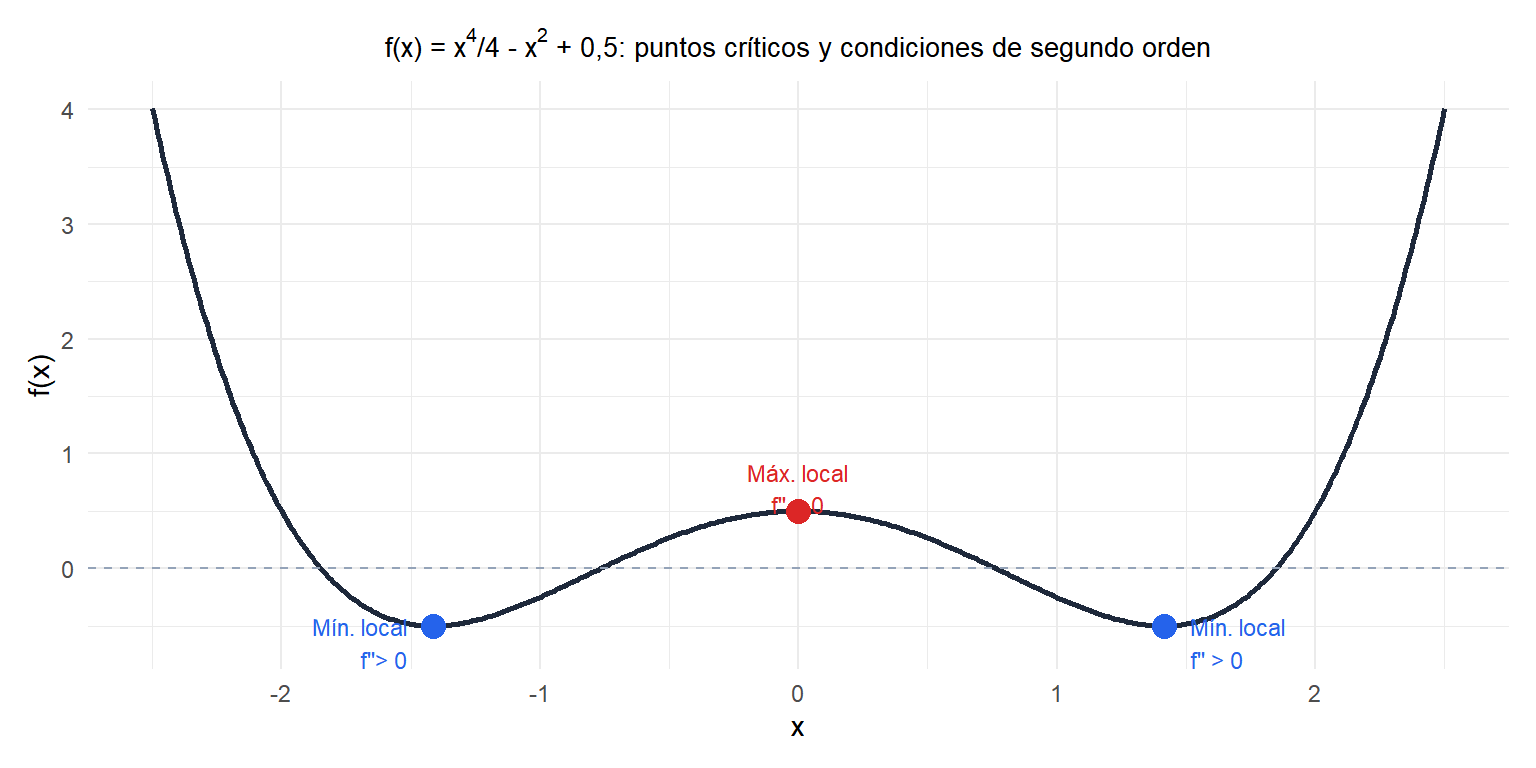
Condición necesaria de primer orden (sin restricciones)
Si \(x^*\) es un mínimo local de una función diferenciable \(f\), entonces:
\[\nabla f(x^*) = \mathbf{0}\]
Los puntos donde \(\nabla f = 0\) se denominan puntos estacionarios o puntos críticos. Incluyen mínimos, máximos y puntos de silla.
Condiciones de segundo orden (sin restricciones)
En un punto estacionario \(x^*\):
| Hessiano \(\nabla^2 f(x^*)\) | Tipo de punto crítico |
|---|---|
| Definido positivo | Mínimo local |
| Definido negativo | Máximo local |
| Indefinido | Punto de silla |
| Semidefinido positivo | No se puede determinar (requiere análisis de orden superior) |
Para una función de una variable: \(f''(x^*) > 0\) implica mínimo local; \(f''(x^*) < 0\) implica máximo local.
Optimalidad con restricciones: Lagrange y KKT
En problemas con restricciones, el gradiente de \(f\) en el óptimo no es necesariamente cero. En cambio, debe poder expresarse como una combinación lineal de los gradientes de las restricciones.
Para problemas con restricciones de igualdad únicamente (\(h_j(x) = 0\)), las condiciones de Lagrange exigen:
\[\nabla f(x^*) + \sum_j \lambda_j \nabla h_j(x^*) = \mathbf{0}\]
Para problemas con restricciones de igualdad y desigualdad, las condiciones KKT (Karush-Kuhn-Tucker) generalizan esto añadiendo condiciones de holgura complementaria para las restricciones de desigualdad. Se tratan en detalle en los artículos sobre multiplicadores de Lagrange y condiciones KKT.
Visión general de los métodos de resolución
| Método | Tipo de problema | Idea clave |
|---|---|---|
| Simplex | Programación lineal | Recorrer los vértices del poliedro factible |
| Descenso del gradiente | Sin restricciones, diferenciable | Seguir el gradiente negativo |
| Método de Newton | Sin restricciones, dos veces diferenciable | Usar el hessiano para dar pasos curvos |
| BFGS / L-BFGS | Sin restricciones, gran escala | Aproximar el hessiano de forma eficiente |
| Multiplicadores de Lagrange | Con restricciones de igualdad | Aumentar el objetivo con penalizaciones por restricción |
| Punto interior | Convexo, con restricciones | Mantenerse dentro de la región factible |
| Dijkstra | Camino más corto en grafos | Expansión voraz del nodo más cercano |
| Recocido simulado | No convexo, combinatorio | Aceptar soluciones peores con cierta probabilidad |
⚠️ Los métodos locales pueden quedarse atrapados en mínimos locales
Los métodos basados en gradiente (descenso del gradiente, método de Newton, BFGS) convergen a un mínimo local, no necesariamente al global. En problemas no convexos esto es una limitación fundamental:
- Problemas convexos: cualquier mínimo local es global. Los métodos basados en gradiente funcionan con total garantía.
- Problemas no convexos (redes neuronales, optimización combinatoria): los métodos locales pueden encontrar soluciones pobres. Las estrategias habituales incluyen múltiples reinicios aleatorios, métodos estocásticos u heurísticas de optimización global (recocido simulado, algoritmos genéticos).
En la práctica, muchos problemas no convexos de machine learning se comportan bien empíricamente: los puntos de silla son más frecuentes que los mínimos locales, y la mayoría de mínimos locales tienen valores de la función objetivo similares.
💡 Elegir el método de optimización adecuado
Preguntas clave antes de elegir un método:
- ¿Es el problema convexo? Si es así, cualquier solver local encuentra el óptimo global.
- ¿Es \(f\) diferenciable? Los métodos basados en gradiente requieren al menos las derivadas de primer orden.
- ¿Cuántas variables hay? Los problemas de gran escala (\(n > 10^4\)) necesitan métodos que eviten almacenar el hessiano (L-BFGS, SGD).
- ¿Hay restricciones? Solo de igualdad: Lagrange. También de desigualdad: KKT, punto interior o métodos de penalización.
- ¿Es el problema combinatorio? Usa programación entera, programación dinámica o metaheurísticas.

