Estimación de una proporción
La proporción muestral \(\hat{p}\) es el estimador puntual estándar para una proporción poblacional \(p\). Es insesgada, consistente y aproximadamente normal para muestras grandes, lo que la convierte en la base de toda inferencia sobre proporciones.
Definición
La proporción poblacional \(p\) es la fracción de una población que tiene una característica determinada. Como no es posible medir toda la población, se toma una muestra aleatoria de tamaño \(n\) y se cuenta el número de éxitos \(X\).
La proporción muestral es:
\[\hat{p} = \frac{X}{n}\]
donde \(X \sim \text{Binomial}(n, p)\). Como \(E[X] = np\), la proporción muestral es un estimador insesgado: \(E[\hat{p}] = p\).
Distribución muestral de \(\hat{p}\)
Antes de recoger datos, \(\hat{p}\) es una variable aleatoria. Su distribución exacta es:
\[\hat{p} = X/n \quad \text{donde } X \sim \text{Binomial}(n, p)\]
Por el Teorema Central del Límite, para \(n\) suficientemente grande:
\[\hat{p} \approx N\!\left(p,\ \sqrt{\frac{p(1-p)}{n}}\right)\]
El error estándar de \(\hat{p}\) es:
\[\text{EE}(\hat{p}) = \sqrt{\frac{p(1-p)}{n}}\]
Como \(p\) es desconocida, en la práctica se estima con \(\hat{p}\):
\[\widehat{\text{EE}}(\hat{p}) = \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}\]
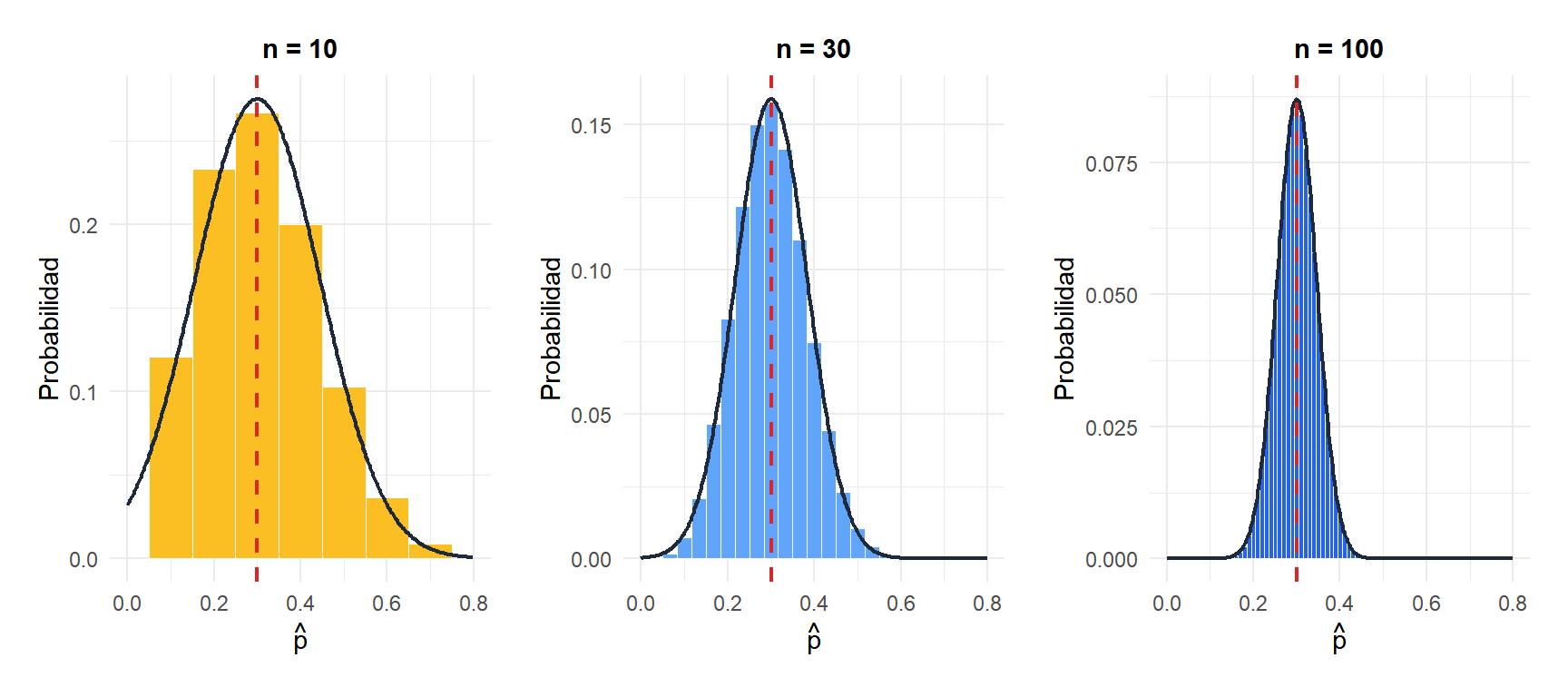
Para \(n\) pequeño, la distribución binomial discreta claramente no es normal (especialmente si \(p\) está cerca de 0 o 1). A medida que \(n\) crece, la aproximación normal (curva negra) se ajusta bien.
Error estándar y precisión
El error estándar \(\text{EE}(\hat{p}) = \sqrt{p(1-p)/n}\) depende tanto de la proporción real como del tamaño muestral.
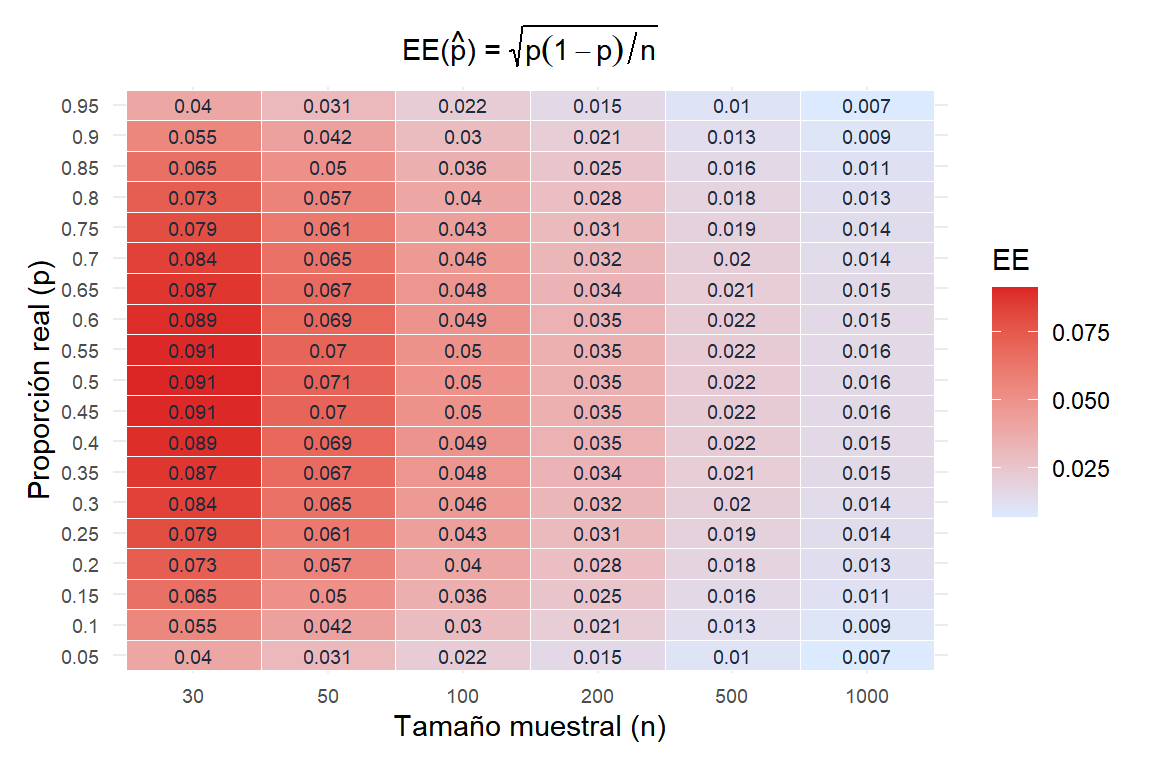
Observaciones clave:
- El EE se maximiza en \(p = 0{,}5\) (caso de mayor incertidumbre) y disminuye hacia 0 y 1.
- Para \(p = 0{,}5\) y \(n = 100\): \(\text{EE} = \sqrt{0{,}25/100} = 0{,}05\).
- Para reducir el EE a la mitad se necesita cuatro veces el tamaño muestral.
¿Cuándo es válida la aproximación normal?
La regla práctica estándar exige que se cumplan ambas condiciones:
\[n\hat{p} \geq 10 \quad \text{y} \quad n(1-\hat{p}) \geq 10\]
Esto garantiza suficientes éxitos y fracasos para que la binomial quede bien aproximada por una distribución normal.
⚠️ La aproximación normal falla para eventos raros y muestras pequeñas
Cuando \(p\) es muy pequeño (eventos raros) o muy grande, o cuando \(n\) es pequeño, la aproximación normal es mala:
- Para \(p = 0{,}02\) y \(n = 100\): \(n\hat{p} = 2 < 10\). La distribución está fuertemente sesgada a la derecha y la aproximación normal no es válida.
- En este caso, usa la distribución binomial exacta o, para eventos raros, la aproximación de Poisson.
Una alternativa más conservadora es el intervalo de Wilson, que funciona bien incluso cuando la aproximación normal falla, y se prefiere en muchos contextos aplicados frente al intervalo de Wald estándar.
Ejemplos
Control de calidad: tasa de defectos
Una fábrica inspecciona 200 componentes y encuentra 14 defectuosos. La estimación puntual de la tasa de defectos es:
\[\hat{p} = \frac{14}{200} = 0{,}07\]
El error estándar estimado:
\[\widehat{\text{EE}} = \sqrt{\frac{0{,}07 \times 0{,}93}{200}} = \sqrt{\frac{0{,}0651}{200}} \approx 0{,}018\]
Comprobación: \(n\hat{p} = 200 \times 0{,}07 = 14 \geq 10\) y \(n(1-\hat{p}) = 186 \geq 10\). La aproximación normal es válida.
La mejor estimación de la tasa de defectos poblacional es el 7%, con un error estándar del 1,8%.
Ensayo clínico: tasa de respuesta
En un ensayo de fase II, 45 de 120 pacientes responden a un nuevo tratamiento:
\[\hat{p} = \frac{45}{120} = 0{,}375\]
\[\widehat{\text{EE}} = \sqrt{\frac{0{,}375 \times 0{,}625}{120}} \approx \sqrt{0{,}001953} \approx 0{,}044\]
La estimación puntual de la tasa de respuesta es el 37,5% con un error estándar del 4,4%.
Mismo \(\hat{p} = 0{,}375\), distintos tamaños muestrales:
| \(n\) | \(\widehat{\text{EE}}\) | Margen de error (\(\times 1{,}96\)) |
|---|---|---|
| 30 | 0,088 | ±17,3% |
| 120 | 0,044 | ±8,7% |
| 480 | 0,022 | ±4,3% |
| 1920 | 0,011 | ±2,2% |
Cuadruplicar el tamaño muestral reduce el margen de error a la mitad. Para conseguir un margen de error del 2% se necesitan aproximadamente 2.000 observaciones cuando \(p \approx 0{,}375\).
💡 Cómo elegir entre estimadores de proporciones
- \(\hat{p} = X/n\) estándar: la opción por defecto, insesgada, funciona bien cuando \(n\hat{p} \geq 10\) y \(n(1-\hat{p}) \geq 10\).
- Estimador +2 (Agresti-Coull): \(\tilde{p} = (X+2)/(n+4)\). Ligeramente sesgado pero mejor para \(n\) pequeño o \(p\) extremo. Recomendado para intervalos de confianza.
- Estimador bayesiano: usa una distribución a priori Beta. Con una a priori uniforme Beta(1,1), la media a posteriori es \((X+1)/(n+2)\), una suavización natural hacia 0,5.
Para muestras grandes con \(p\) no demasiado extremo, los tres dan resultados prácticamente idénticos.

