Distribución beta
La distribución beta está definida en el intervalo \([0, 1]\) y es extraordinariamente flexible: según sus dos parámetros de forma, puede adoptar casi cualquier forma: uniforme, acampanada, en U, en J o sesgada en cualquier dirección. Esto la convierte en el modelo natural para proporciones, probabilidades y tasas.
Definición
Una variable aleatoria \(X\) sigue una distribución beta con parámetros de forma \(\alpha > 0\) y \(\beta > 0\), escrita \(X \sim \text{Beta}(\alpha, \beta)\), si:
\[f(x) = \frac{x^{\alpha-1}(1-x)^{\beta-1}}{B(\alpha, \beta)}, \quad 0 \leq x \leq 1\]
donde \(B(\alpha, \beta) = \frac{\Gamma(\alpha)\Gamma(\beta)}{\Gamma(\alpha+\beta)}\) es la función beta, que actúa como constante normalizadora para que la PDF integre a 1.
La CDF no tiene forma cerrada para \(\alpha, \beta\) generales y se calcula numéricamente como la función beta incompleta regularizada \(I_x(\alpha, \beta)\).
⚠️ La función beta y la distribución beta no son lo mismo
La función beta \(B(\alpha, \beta)\) es una función matemática usada como constante normalizadora en la PDF. No es lo mismo que la distribución beta. La distribución beta es una distribución de probabilidad; la función beta es una función especial. Ambas usan las mismas letras griegas, lo que genera confusión en los libros de texto.
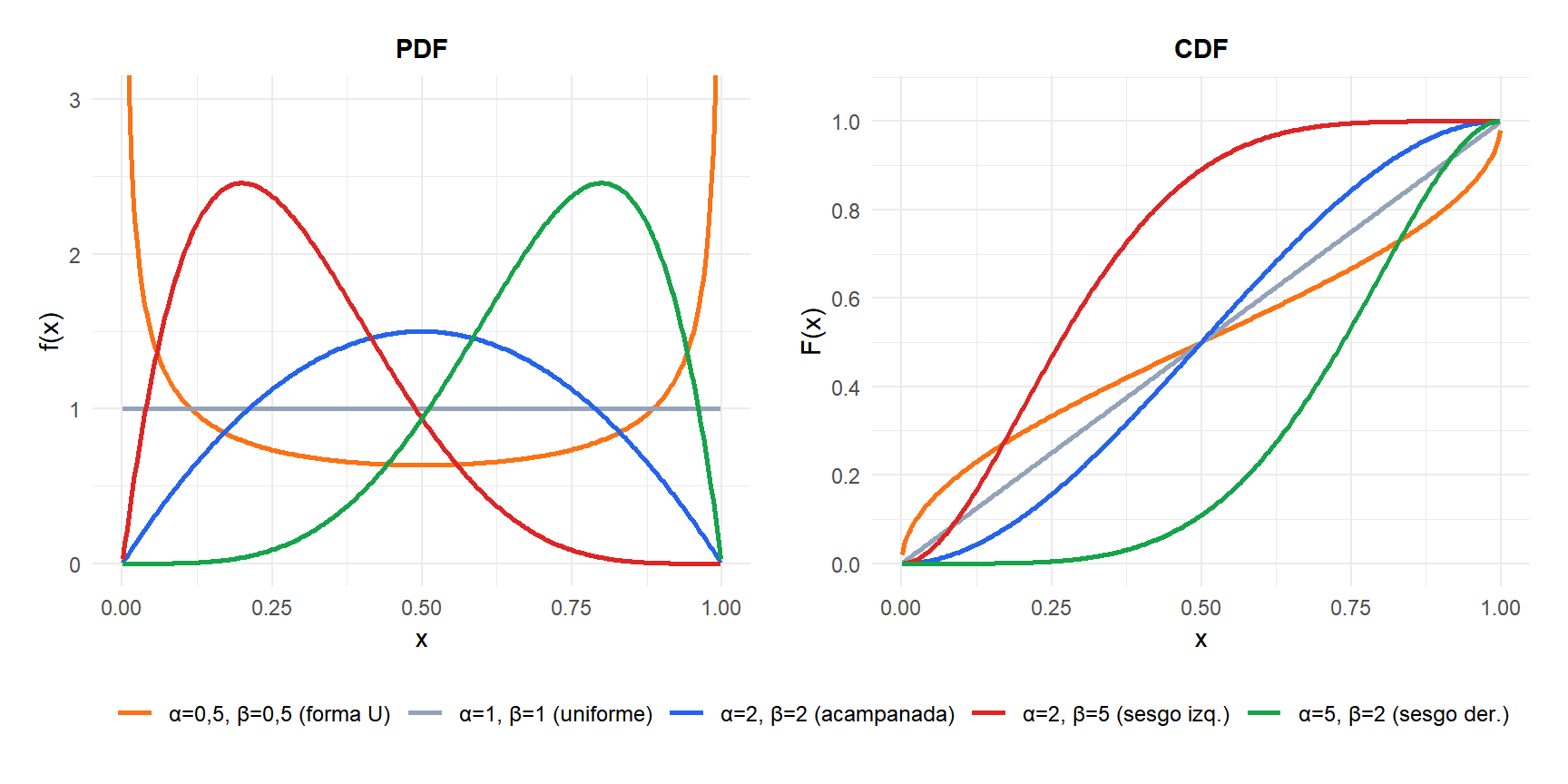
Cómo los parámetros de forma controlan la distribución
El comportamiento de la distribución beta cambia drásticamente según \(\alpha\) y \(\beta\):
- \(\alpha = \beta = 1\): distribución uniforme en \([0,1]\).
- \(\alpha = \beta > 1\): forma acampanada simétrica centrada en 0,5. Valores mayores dan una campana más estrecha.
- \(\alpha = \beta < 1\): forma en U, con probabilidad concentrada cerca de 0 y 1.
- \(\alpha > \beta\): sesgada a la derecha, la distribución se inclina hacia 1.
- \(\alpha < \beta\): sesgada a la izquierda, la distribución se inclina hacia 0.
- \(\alpha > 1\), \(\beta = 1\): distribución potencia, monótonamente creciente.
- \(\alpha = 1\), \(\beta > 1\): monótonamente decreciente.
Propiedades
Para \(X \sim \text{Beta}(\alpha, \beta)\):
- Valor esperado (media)
\[E(X) = \frac{\alpha}{\alpha + \beta}\]
- Varianza
\[\text{Var}(X) = \frac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1)}\]
- Asimetría
\[\text{Asimetría} = \frac{2(\beta - \alpha)\sqrt{\alpha+\beta+1}}{(\alpha+\beta+2)\sqrt{\alpha\beta}}\]
Positiva cuando \(\alpha < \beta\) (sesgada hacia 0), negativa cuando \(\alpha > \beta\) (sesgada hacia 1), cero cuando \(\alpha = \beta\).
- Curtosis
\[g_2 = \frac{6\left[(\alpha-\beta)^2(\alpha+\beta+1) - \alpha\beta(\alpha+\beta+2)\right]}{\alpha\beta(\alpha+\beta+2)(\alpha+\beta+3)}\]
- Moda
\[\text{Moda} = \frac{\alpha - 1}{\alpha + \beta - 2}, \quad \text{para } \alpha > 1 \text{ y } \beta > 1\]
Para \(\alpha \leq 1\) o \(\beta \leq 1\), la moda está en 0, en 1 o en ambos extremos (forma en U).
- Función cuantil
No existe forma cerrada; se calcula numéricamente mediante la función beta incompleta inversa.
La distribución beta como distribución a priori bayesiana
La distribución beta es la distribución a priori conjugada para la verosimilitud binomial. Esto significa: si se observan \(k\) éxitos en \(n\) ensayos de Bernoulli y la creencia a priori sobre la probabilidad de éxito \(p\) es \(\text{Beta}(\alpha, \beta)\), entonces la creencia actualizada (a posteriori) es:
\[p \mid k,n \sim \text{Beta}(\alpha + k,\ \beta + n - k)\]
La distribución a posteriori sigue siendo una beta, con parámetros actualizados. Los parámetros \(\alpha\) y \(\beta\) en la distribución a priori pueden interpretarse como pseudorecuentos: \(\alpha - 1\) éxitos previos y \(\beta - 1\) fracasos previos.
Un optimizador de tasas de conversión quiere estimar la tasa de clics \(p\) de un nuevo diseño de botón. Sin datos previos, asume \(p \sim \text{Beta}(1, 1)\) (distribución a priori uniforme: todas las tasas son igualmente plausibles).
Tras mostrar el botón a 100 visitantes, 12 hacen clic. La distribución a posteriori es:
\[p \mid \text{datos} \sim \text{Beta}(1 + 12,\ 1 + 88) = \text{Beta}(13, 89)\]
Media a posteriori: \(13/(13+89) \approx 0{,}127\).
Moda a posteriori: \((13-1)/(13+89-2) = 12/100 = 0{,}12\) (igual que el MLE).
Intervalo de credibilidad al 95%: qbeta(c(0.025, 0.975), 13, 89) \(\approx (0{,}067;\, 0{,}208)\).
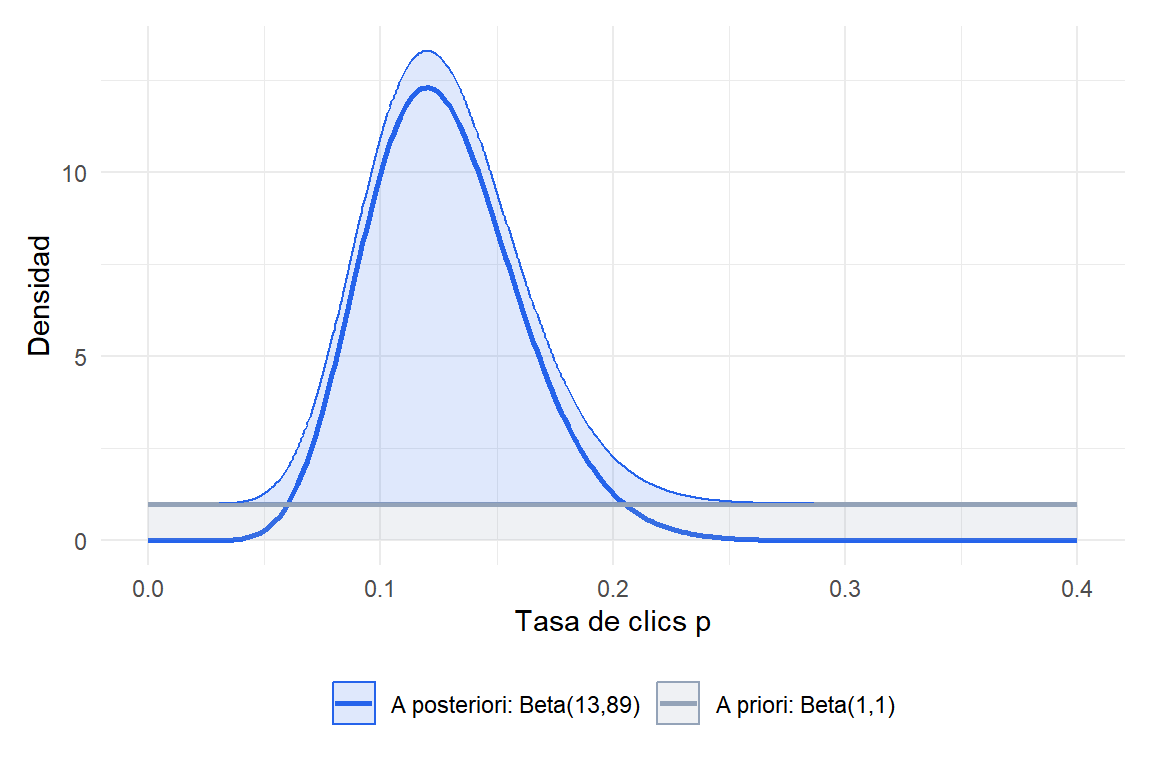
Figure 1: Actualización bayesiana: distribución a priori plana Beta(1,1) actualizada a Beta(13,89) tras observar 12 clics de 100 visitantes
Ejemplo paso a paso
Un proceso de fabricación tiene una tasa de defectos \(p\) que se modela como \(p \sim \text{Beta}(3, 15)\), basándose en datos históricos que sugieren que la mayoría de los lotes tienen una tasa de defectos de alrededor del 15-20%.
Tasa de defectos esperada:
\[E(p) = \frac{3}{3+15} = \frac{3}{18} \approx 0{,}167\]
Varianza:
\[\text{Var}(p) = \frac{3 \times 15}{18^2 \times 19} \approx 0{,}0073\]
Desviación típica \(\approx 0{,}086\).
Moda (tasa de defectos más probable):
\[\text{Moda} = \frac{3-1}{3+15-2} = \frac{2}{16} = 0{,}125\]
Probabilidad de que la tasa de defectos supere el 25%:
\[P(p > 0{,}25) = 1 - F(0{,}25) = 1 - I_{0{,}25}(3, 15) \approx 1 - 0{,}902 = 0{,}098\]
Aproximadamente el 10% de los lotes tienen una tasa de defectos superior al 25%.
Test A/B: tras un experimento, las tasas de conversión de dos variantes se modelan como \(p_A \sim \text{Beta}(40, 160)\) y \(p_B \sim \text{Beta}(55, 145)\). La probabilidad de que \(p_B > p_A\) se puede calcular por simulación o integración numérica: es el núcleo del test A/B bayesiano.
Tasa de finalización de proyectos: en gestión de proyectos, la proporción de tareas completadas a tiempo en proyectos similares sigue \(\text{Beta}(8, 2)\) (media 0,8; la mayoría de los proyectos completan el 80% o más a tiempo). Probabilidad de completar más del 90% a tiempo: \(P(X > 0{,}9) = 1 - I_{0{,}9}(8,2) \approx 0{,}264\).
Estadísticos de orden: el \(k\)-ésimo estadístico de orden de \(n\) variables \(\text{Uniforme}(0,1)\) independientes sigue \(\text{Beta}(k,\, n-k+1)\).
💡 Relación con otras distribuciones
- Uniforme: \(\text{Beta}(1,1) = \text{Uniforme}(0,1)\).
- Gamma: si \(X \sim \text{Gamma}(\alpha,1)\) e \(Y \sim \text{Gamma}(\beta,1)\) son independientes, entonces \(X/(X+Y) \sim \text{Beta}(\alpha,\beta)\).
- Binomial: la beta es la distribución a priori conjugada para el parámetro \(p\) de la verosimilitud binomial.
- Dirichlet: la generalización multivariante de la distribución beta, usada para modelar vectores de probabilidades (por ejemplo, distribuciones de temas en modelos de texto).
- Estadísticos de orden: \(\text{Beta}(k,\, n-k+1)\) es la distribución del \(k\)-ésimo estadístico de orden de \(n\) muestras uniformes.

