Contraste chi-cuadrado
El contraste chi-cuadrado es el método estándar para analizar datos categóricos. Tiene dos formas: el contraste de independencia (¿están asociadas dos variables categóricas?) y el de bondad de ajuste (¿sigue una variable categórica una distribución específica?). Ambos usan el mismo estadístico y la distribución chi-cuadrado como referencia.
El estadístico chi-cuadrado
Ambos contrastes comparten la misma idea central: comparar las frecuencias observadas \(O_i\) con las esperadas \(E_i\) bajo \(H_0\).
\[\chi^2 = \sum \frac{(O_i - E_i)^2}{E_i}\]
Valores grandes de \(\chi^2\) indican que los datos observados se alejan mucho de lo que predice \(H_0\). Bajo \(H_0\), este estadístico sigue una distribución \(\chi^2\) cuyos grados de libertad dependen del tipo de contraste.
Contraste de independencia
Se usa para contrastar si dos variables categóricas están asociadas en una tabla de contingencia.
Hipótesis: \(H_0\): las dos variables son independientes. \(H_1\): existe asociación.
Frecuencias esperadas para cada celda \((i, j)\):
\[E_{ij} = \frac{\text{total fila}_i \times \text{total columna}_j}{\text{total general}}\]
Grados de libertad: \(gl = (f-1)(c-1)\), donde \(f\) = número de filas y \(c\) = número de columnas.
Una encuesta a 200 personas registra el género (Hombre/Mujer) y la preferencia por el producto (Le gusta/No le gusta):
| Le gusta | No le gusta | Total | |
|---|---|---|---|
| Hombre | 60 | 40 | 100 |
| Mujer | 30 | 70 | 100 |
| Total | 90 | 110 | 200 |
Frecuencias esperadas bajo independencia:
\[E_{11} = \frac{100 \times 90}{200} = 45, \quad E_{12} = \frac{100 \times 110}{200} = 55\] \[E_{21} = \frac{100 \times 90}{200} = 45, \quad E_{22} = \frac{100 \times 110}{200} = 55\]
Estadístico del contraste:
\[\chi^2 = \frac{(60-45)^2}{45} + \frac{(40-55)^2}{55} + \frac{(30-45)^2}{45} + \frac{(70-55)^2}{55}\] \[= 5{,}000 + 4{,}091 + 5{,}000 + 4{,}091 = 18{,}182\]
\(gl = (2-1)(2-1) = 1\). Valor crítico con \(\alpha=0{,}05\): \(\chi^2_{0{,}05,1} = 3{,}841\).
Como \(18{,}182 > 3{,}841\), rechazamos \(H_0\). Hay una asociación significativa entre el género y la preferencia por el producto.

El mapa de calor muestra la contribución de cada celda al \(\chi^2\): las celdas más rojas se alejan más de la independencia.
Tamaño del efecto: V de Cramér
El p-valor indica si la asociación es significativa, no cuán fuerte es. Para tablas de contingencia, usa la V de Cramér:
\[V = \sqrt{\frac{\chi^2}{n \times \min(f-1, c-1)}}\]
\(V\) oscila entre 0 (sin asociación) y 1 (asociación perfecta). Para una tabla \(2 \times 2\) es igual al valor absoluto del coeficiente phi.
Para el ejemplo: \(V = \sqrt{18{,}182 / (200 \times 1)} = \sqrt{0{,}0909} \approx 0{,}301\). Una asociación moderada.
⚠️ La significación estadística no equivale a una asociación fuerte
Con muestras grandes, incluso asociaciones triviales producen estadísticos chi-cuadrado significativos. Una encuesta a 10.000 personas podría dar \(\chi^2 = 5{,}2\) (\(p = 0{,}023\)) para una asociación con \(V = 0{,}02\): estadísticamente significativa pero prácticamente despreciable.
Informa siempre la V de Cramér junto con el p-valor. Como guía aproximada: \(V < 0{,}1\) es débil, \(0{,}1 \leq V < 0{,}3\) es moderada, \(V \geq 0{,}3\) es fuerte.
Contraste de bondad de ajuste
Se usa para contrastar si una variable categórica sigue una distribución específica.
Hipótesis: \(H_0\): la variable sigue la distribución especificada. \(H_1\): no la sigue.
Grados de libertad: \(gl = k - 1\), donde \(k\) es el número de categorías.
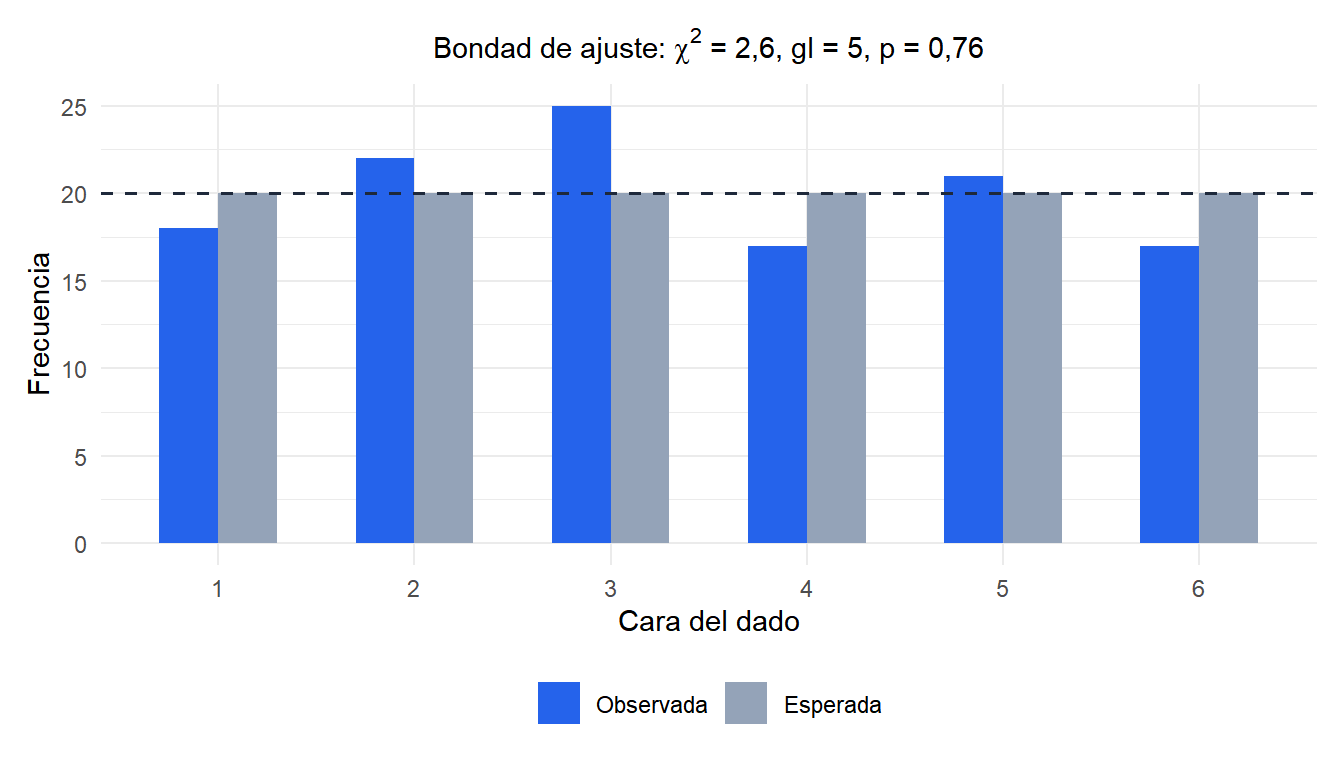
Se lanza un dado 120 veces. Si es justo, cada cara debería aparecer 20 veces. Frecuencias observadas:
| Cara | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Observada | 18 | 22 | 25 | 17 | 21 | 17 |
| Esperada | 20 | 20 | 20 | 20 | 20 | 20 |
\[\chi^2 = \frac{(18-20)^2}{20} + \frac{(22-20)^2}{20} + \frac{(25-20)^2}{20} + \frac{(17-20)^2}{20} + \frac{(21-20)^2}{20} + \frac{(17-20)^2}{20}\] \[= 0{,}2 + 0{,}2 + 1{,}25 + 0{,}45 + 0{,}05 + 0{,}45 = 2{,}6\]
\(gl = 6 - 1 = 5\). Valor crítico con \(\alpha=0{,}05\): \(\chi^2_{0{,}05,5} = 11{,}07\).
Como \(2{,}6 < 11{,}07\), no rechazamos \(H_0\). No hay evidencia significativa de que el dado sea injusto.
Supuestos
Ambos contrastes chi-cuadrado requieren:
- Independencia: las observaciones no están emparejadas ni agrupadas.
- Frecuencias esperadas \(\geq 5\): cada celda de la tabla debe tener una frecuencia esperada de al menos 5. Si esto no se cumple, combina categorías o usa el test exacto de Fisher (para tablas \(2 \times 2\)).
- Recuentos, no porcentajes: el estadístico del contraste debe calcularse a partir de recuentos brutos, no de proporciones.
⚠️ El contraste chi-cuadrado no identifica qué celdas impulsan la asociación
Un resultado significativo en una tabla de contingencia grande indica que hay una asociación en algún lugar, pero no dónde. Usa los residuos estandarizados para identificar qué celdas se desvían más de la independencia:
\[r_{ij} = \frac{O_{ij} - E_{ij}}{\sqrt{E_{ij}}}\]
Las celdas con \(|r_{ij}| > 2\) contribuyen significativamente al \(\chi^2\) global. En R: chisq.test(tabla)$residuals.
Realizar los contrastes en R
Ambos contrastes están disponibles en R base. Para el contraste de independencia, pasa la tabla de contingencia a chisq.test(). Para la bondad de ajuste, pasa los recuentos observados y, opcionalmente, las probabilidades esperadas. El argumento correct = FALSE desactiva la corrección de continuidad de Yates, que rara vez es necesaria con muestras grandes pero se aplica por defecto en tablas \(2 \times 2\).
# Contraste de independencia
tabla <- matrix(c(60, 40, 30, 70), nrow = 2)
chisq.test(tabla, correct = FALSE)
# V de Cramér (paquetes rstatix o vcd)
library(vcd)
assocstats(tabla)
# Bondad de ajuste
observado <- c(18, 22, 25, 17, 21, 17)
chisq.test(observado) # contrasta uniformidad por defectoLa salida incluye el estadístico, los grados de libertad y el p-valor. Los residuos estandarizados son accesibles mediante chisq.test(tabla)$residuals, lo que ayuda a identificar qué celdas impulsan un resultado significativo.
💡 Elegir entre chi-cuadrado y el test exacto de Fisher
Para tablas \(2 \times 2\) con muestras pequeñas (alguna frecuencia esperada \(< 5\)), usa el test exacto de Fisher (fisher.test() en R). Calcula el p-valor exacto a partir de la distribución hipergeométrica y no requiere muestras grandes. Para tablas mayores, el chi-cuadrado es el enfoque estándar.

