Análisis de varianza (ANOVA)
El ANOVA de un factor contrasta si las medias de tres o más grupos independientes son todas iguales. Extiende el test t de dos muestras a múltiples grupos controlando la tasa de error de tipo I, que se inflaría si se aplicaran tests t por pares de forma múltiple.
¿Por qué no múltiples tests t?
Con \(k\) grupos hay \(\binom{k}{2}\) comparaciones por pares posibles. Con \(\alpha = 0{,}05\), cada test t tiene un 5% de probabilidad de falso positivo. Con 3 grupos (3 comparaciones), la probabilidad de al menos un falso positivo es \(1 - 0{,}95^3 \approx 0{,}14\): casi tres veces la tasa nominal. El ANOVA contrasta todos los grupos simultáneamente con un único estadístico F, manteniendo el error de tipo I en \(\alpha\).
Hipótesis
\[H_0: \mu_1 = \mu_2 = \cdots = \mu_k \qquad H_1: \text{al menos un } \mu_i \neq \mu_j\]
Un resultado significativo solo indica que al menos una media de grupo difiere. Los tests post-hoc identifican qué pares difieren.
Descomposición de la varianza
El ANOVA descompone la variación total en dos componentes:
\[SC_\text{total} = SC_\text{entre} + SC_\text{dentro}\]
donde:
- \(SC_\text{entre} = \sum_{i=1}^k n_i (\bar{y}_i - \bar{y})^2\): variación debida a las diferencias entre medias de grupo.
- \(SC_\text{dentro} = \sum_{i=1}^k \sum_{j=1}^{n_i} (y_{ij} - \bar{y}_i)^2\): variación dentro de los grupos (residual).
El estadístico F es el cociente de cuadrados medios:
\[F = \frac{CM_\text{entre}}{CM_\text{dentro}} = \frac{SC_\text{entre}/(k-1)}{SC_\text{dentro}/(N-k)}\]
Bajo \(H_0\) y el supuesto de normalidad, \(F \sim F(k-1, N-k)\). Valores grandes de \(F\) indican que la variación entre grupos supera lo que cabría esperar por azar.
La tabla ANOVA
Los resultados se presentan habitualmente en una tabla estandarizada:
| Fuente | SC | gl | CM | F | p-valor |
|---|---|---|---|---|---|
| Entre grupos | \(SC_E\) | \(k-1\) | \(CM_E = SC_E/(k-1)\) | \(F = CM_E/CM_D\) | \(P(F_{k-1,N-k} \geq F)\) |
| Dentro de grupos | \(SC_D\) | \(N-k\) | \(CM_D = SC_D/(N-k)\) | ||
| Total | \(SC_T\) | \(N-1\) |
Ejemplo completo: tres planes de dieta
Una nutricionista compara la pérdida de peso (kg) en tres planes de dieta tras 8 semanas:
- Dieta A: 4, 5, 6, 5, 7 (\(n_1 = 5\), \(\bar{y}_1 = 5{,}4\))
- Dieta B: 8, 7, 9, 10, 8 (\(n_2 = 5\), \(\bar{y}_2 = 8{,}4\))
- Dieta C: 3, 2, 4, 3, 2 (\(n_3 = 5\), \(\bar{y}_3 = 2{,}8\))
Media global: \(\bar{y} = (5{,}4 + 8{,}4 + 2{,}8)/3 = 5{,}533\).
\(SC_\text{entre}\):
\[SC_E = 5(5{,}4-5{,}533)^2 + 5(8{,}4-5{,}533)^2 + 5(2{,}8-5{,}533)^2\] \[= 5(0{,}018) + 5(8{,}211) + 5(7{,}474) = 0{,}089 + 41{,}056 + 37{,}369 = 78{,}533\]
\(SC_\text{dentro}\) (suma de desviaciones al cuadrado dentro de cada grupo):
Dieta A: \((4-5{,}4)^2+(5-5{,}4)^2+(6-5{,}4)^2+(5-5{,}4)^2+(7-5{,}4)^2 = 1{,}96+0{,}16+0{,}36+0{,}16+2{,}56 = 5{,}2\)
Dieta B: \((8-8{,}4)^2+(7-8{,}4)^2+(9-8{,}4)^2+(10-8{,}4)^2+(8-8{,}4)^2 = 0{,}16+1{,}96+0{,}36+2{,}56+0{,}16 = 5{,}2\)
Dieta C: \((3-2{,}8)^2+(2-2{,}8)^2+(4-2{,}8)^2+(3-2{,}8)^2+(2-2{,}8)^2 = 0{,}04+0{,}64+1{,}44+0{,}04+0{,}64 = 2{,}8\)
\(SC_D = 5{,}2 + 5{,}2 + 2{,}8 = 13{,}2\)
Tabla ANOVA:
| Fuente | SC | gl | CM | F | p-valor |
|---|---|---|---|---|---|
| Entre | 78,533 | 2 | 39,267 | 35,70 | < 0,001 |
| Dentro | 13,200 | 12 | 1,100 | ||
| Total | 91,733 | 14 |
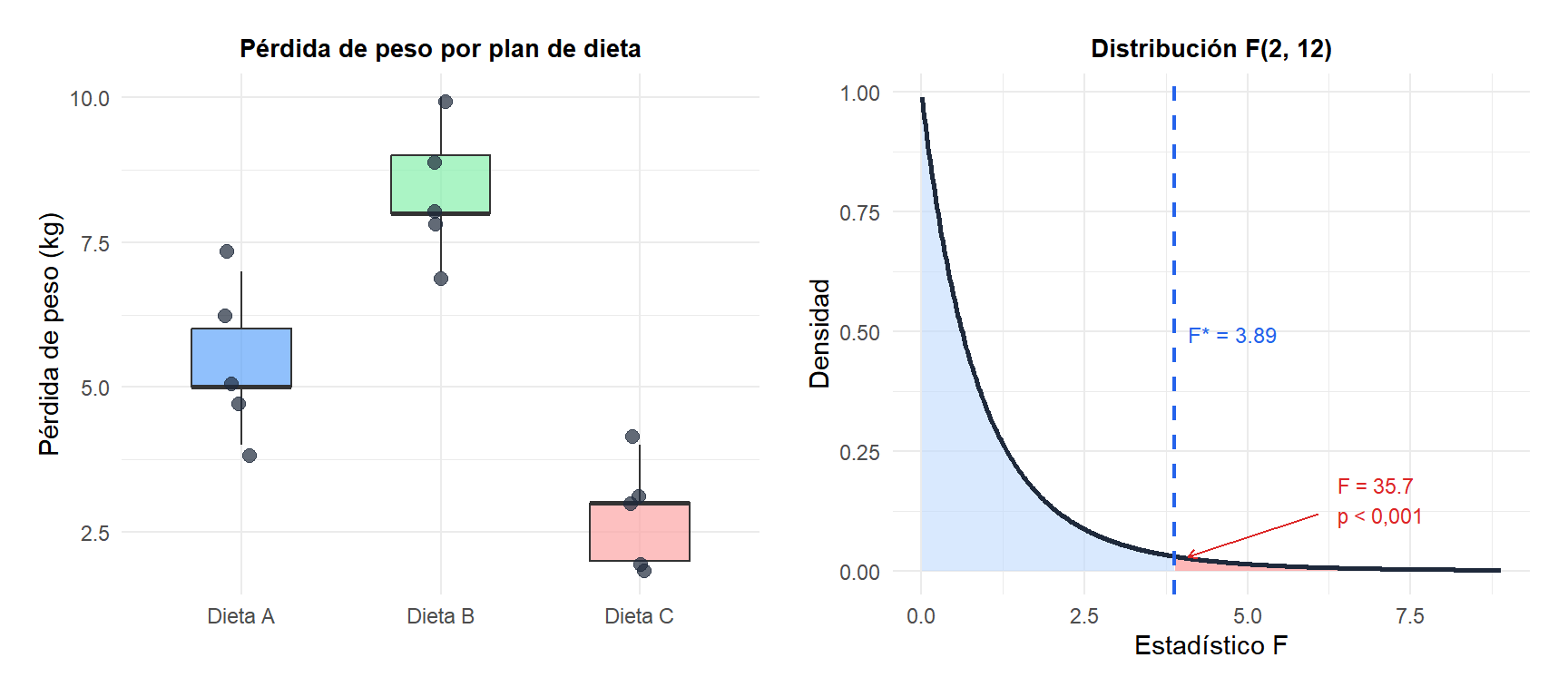
Decisión: \(F = 35{,}70 \gg F_{0{,}05,2,12} = 3{,}885\), \(p < 0{,}001\). Rechazamos \(H_0\): al menos una dieta produce una pérdida de peso media distinta.
Tests post-hoc: ¿qué grupos difieren?
El rechazo de \(H_0\) por el ANOVA solo indica que algunas medias difieren. Los tests post-hoc identifican qué pares, controlando las comparaciones múltiples.
La HSD de Tukey (Diferencia Significativa Honesta) es la opción estándar cuando se comparan todos los pares. Usa la distribución del rango estudentizado y controla la tasa de error familiar en \(\alpha\).
Para tamaños de grupo iguales, la diferencia mínima significativa entre dos medias es:
\[\text{HSD} = q_{\alpha,k,N-k} \sqrt{\frac{CM_D}{n}}\]
donde \(q_{\alpha,k,N-k}\) es el valor crítico de la distribución del rango estudentizado.
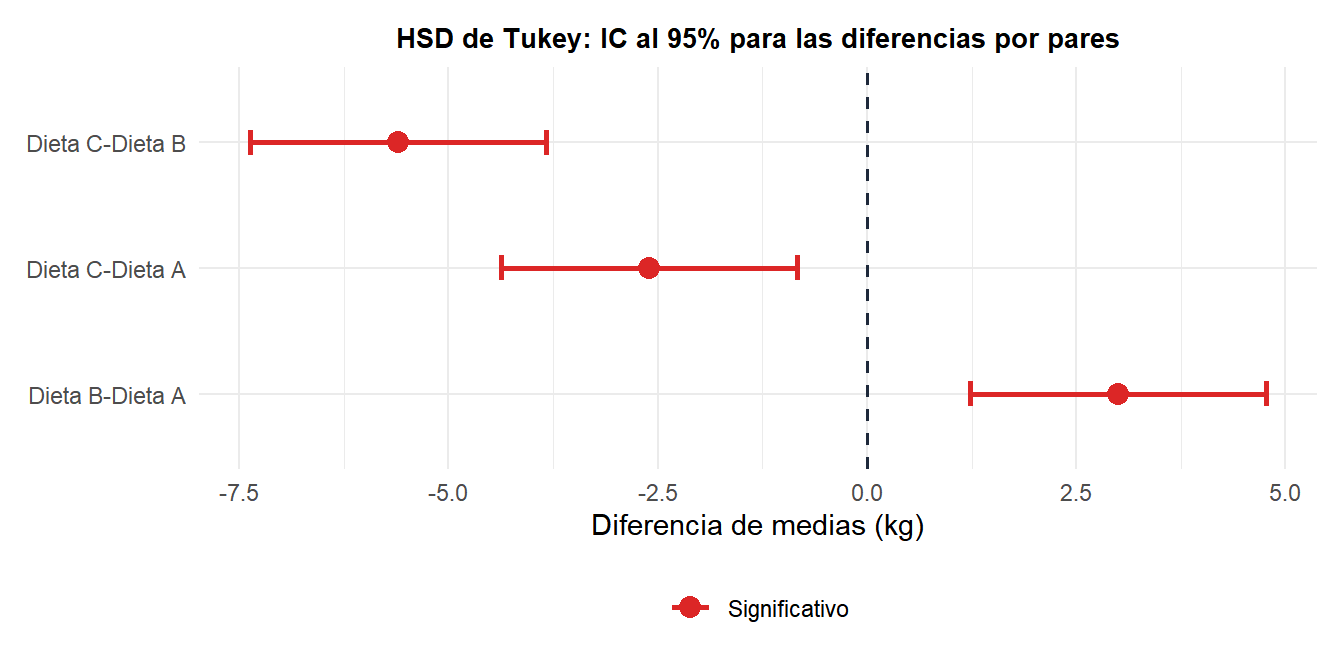
Las tres comparaciones por pares son significativas: todas las dietas difieren entre sí. La dieta B produce la mayor pérdida de peso; la dieta C, la menor.
Supuestos
El ANOVA de un factor requiere:
- Independencia: las observaciones son independientes dentro de cada grupo y entre grupos.
- Normalidad: los residuos son aproximadamente normales dentro de cada grupo. Verifica con el test de Shapiro-Wilk o gráficos Q-Q.
- Homocedasticidad: varianzas iguales entre grupos. Verifica con el test de Levene.
⚠️ El ANOVA es robusto frente a desviaciones leves de normalidad pero no frente a la heterocedasticidad
Con tamaños de grupo iguales o similares, el ANOVA es bastante robusto frente a desviaciones leves de la normalidad (TCL). Es más sensible a las varianzas desiguales, especialmente cuando los tamaños de grupo difieren.
Si el test de Levene rechaza la homocedasticidad:
- Usa el ANOVA de Welch (
oneway.test(..., var.equal = FALSE)en R): no asume varianzas iguales. - Usa Kruskal-Wallis como alternativa no paramétrica.
Si la normalidad se viola gravemente: usa Kruskal-Wallis.
Realizar el ANOVA en R
# ANOVA de un factor
fit <- aov(perdida ~ dieta, data = df_diet)
summary(fit)
# ANOVA de Welch (varianzas desiguales)
oneway.test(perdida ~ dieta, data = df_diet, var.equal = FALSE)
# Post-hoc de Tukey
TukeyHSD(fit)
# Test de Levene para la homocedasticidad
car::leveneTest(perdida ~ dieta, data = df_diet)
# Kruskal-Wallis (alternativa no paramétrica)
kruskal.test(perdida ~ dieta, data = df_diet)💡 ANOVA vs múltiples tests t: la regla clave
Nunca apliques tests t por pares como sustituto del ANOVA. Usa primero el ANOVA para contrastar la \(H_0\) global. Si es significativo, usa tests post-hoc (Tukey, Bonferroni, Scheffé) que controlen la tasa de error familiar. Aplicar tests t por pares sin corrección infla la tasa de error de tipo I y no es científicamente válido.

