Valores de Shapley y SHAP
Los valores de Shapley responden a una pregunta aparentemente sencilla: dada la predicción de un modelo para una observación específica, ¿cuánto contribuyó cada característica a esa predicción? Provienen de la teoría de juegos cooperativos y tienen una justificación matemática única: son el único método de atribución que satisface cuatro axiomas naturales de equidad simultáneamente. SHAP hace los valores de Shapley factibles para modelos de aprendizaje automático.
El problema de atribución
Un modelo predice que un solicitante de préstamo tiene un 78% de probabilidad de impago, comparado con la predicción media del 35%. La predicción está 43 puntos porcentuales por encima de la media. ¿Cuánto de ese exceso explica cada característica (ingresos, edad, historial crediticio, ratio de deuda)?
Esto no es una pregunta trivial. Las características interaccionan: el efecto de los ingresos depende del ratio de deuda. Un enfoque ingenuo que evalúa las características de una en una pierde estas interacciones. Los valores de Shapley resuelven esto promediando sobre todos los posibles órdenes en que las características pueden “introducirse” en el modelo.
Valores de Shapley: la base en teoría de juegos
En la teoría de juegos cooperativos, un conjunto de jugadores \(N = \{1, \ldots, p\}\) juega un juego y obtiene una recompensa conjunta \(v(S)\) para cada coalición \(S \subseteq N\). El valor de Shapley \(\phi_j\) es la parte justa del jugador \(j\):
\[\phi_j = \sum_{S \subseteq N \setminus \{j\}} \frac{|S|!\,(p-|S|-1)!}{p!} \left[v(S \cup \{j\}) - v(S)\right]\]
Para la interpretabilidad de modelos: jugadores = características, recompensa = predicción del modelo, \(v(S)\) = salida esperada del modelo cuando solo se conocen las características en \(S\) (las demás se marginalizan).
La fórmula promedia la contribución marginal de la característica \(j\) sobre todos los posibles órdenes de las características: ¿cuánto cambia añadir \(j\) a la coalición \(S\) la predicción?
Los cuatro axiomas de equidad
Los valores de Shapley son la única atribución que satisface los cuatro simultáneamente:
Eficiencia: los valores de Shapley suman la diferencia entre la predicción y la línea base (predicción media):
\[\sum_{j=1}^p \phi_j = f(\mathbf{x}) - E[f(\mathbf{X})]\]
Cada desviación de la línea base queda completamente explicada.
Simetría: si dos características \(j\) y \(k\) hacen contribuciones idénticas a toda coalición (\(v(S \cup \{j\}) = v(S \cup \{k\})\) para todo \(S\)), reciben el mismo valor de Shapley.
Variable ficticia: si una característica \(j\) no cambia la predicción en ninguna coalición (\(v(S \cup \{j\}) = v(S)\) para todo \(S\)), su valor de Shapley es cero.
Aditividad: para modelos que se descomponen como \(f = f_1 + f_2\), los valores de Shapley se suman: \(\phi_j(f) = \phi_j(f_1) + \phi_j(f_2)\).
Ningún otro método de atribución satisface los cuatro. Métodos como la atribución basada en gradientes, LIME y la importancia por permutación violan al menos uno de los axiomas.
SHAP: aproximación eficiente de Shapley
Calcular los valores de Shapley exactos requiere evaluar el modelo en los \(2^p\) subconjuntos, lo que es exponencial. SHAP (SHapley Additive exPlanations, Lundberg y Lee 2017) proporciona algoritmos eficientes exactos o aproximados para clases específicas de modelos:
TreeSHAP: valores de Shapley exactos para modelos basados en árboles (árboles de decisión, random forests, XGBoost, LightGBM) en tiempo \(O(TLD^2)\) donde \(T\) es el número de árboles, \(L\) es el número de hojas y \(D\) es la profundidad del árbol. Es polinomial, lo que lo hace factible para grandes ensambles.
LinearSHAP: valores de Shapley exactos para modelos lineales. Para un modelo lineal \(f(\mathbf{x}) = \boldsymbol{\beta}^T\mathbf{x} + \beta_0\), el valor de Shapley de la característica \(j\) es simplemente \(\phi_j = \beta_j(x_j - E[x_j])\) cuando las características son independientes.
KernelSHAP: aproximación agnóstica al modelo usando regresión lineal ponderada sobre coaliciones muestreadas. Funciona para cualquier modelo de caja negra pero es más lento.
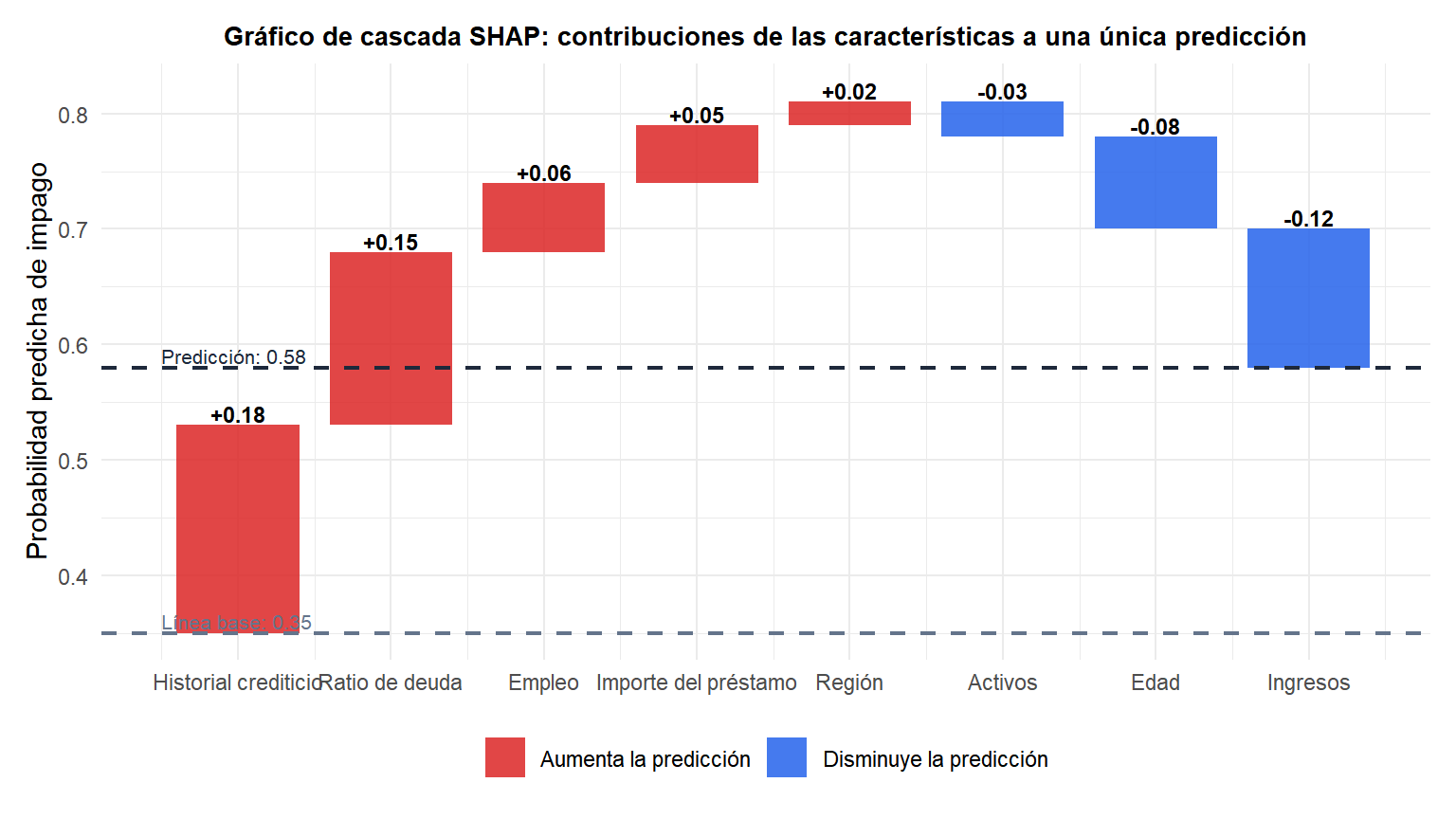
El gráfico de cascada comienza en la línea base (predicción media = 0,35) y añade secuencialmente el valor SHAP de cada característica. Las barras rojas elevan la predicción; las azules la reducen. La predicción final (0,58) es igual a la línea base más todos los valores SHAP, satisfaciendo el axioma de eficiencia.
Interpretabilidad global: el gráfico de resumen SHAP
Los valores de Shapley individuales explican una predicción. Para entender el modelo globalmente, calcula los valores SHAP para todas las observaciones y visualiza la distribución.
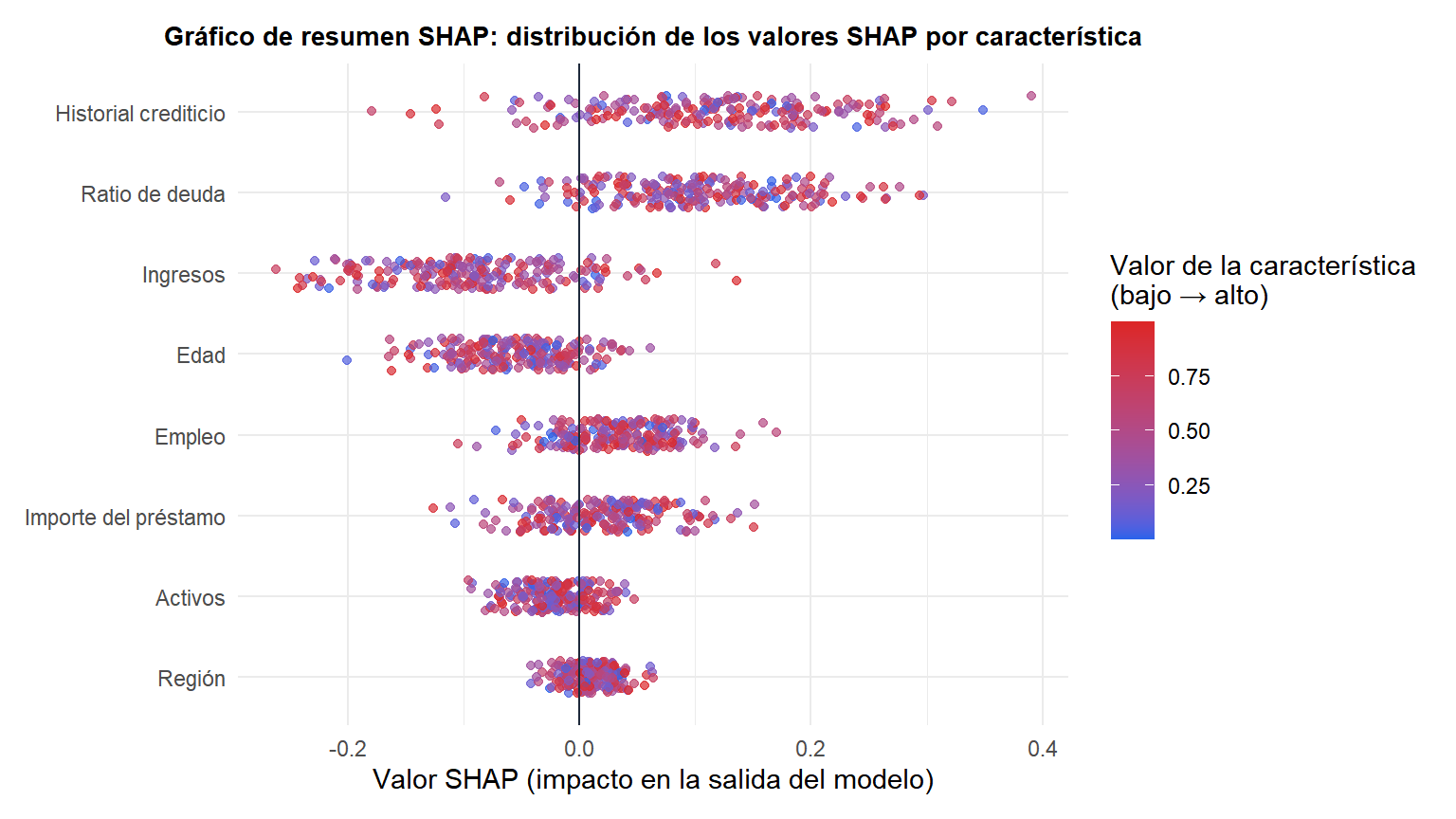
Cada punto es una observación. La posición en x muestra el valor SHAP (dirección y magnitud del efecto de la característica). El color muestra el valor de la característica (azul = bajo, rojo = alto). El gráfico de resumen revela: un ratio de deuda alto (rojo) eleva las predicciones; unos ingresos altos (rojo) las reducen. Las características están ordenadas por valor SHAP absoluto medio (importancia global).
SHAP vs. importancia de características tradicional
| Importancia por permutación | Importancia por impureza | SHAP | |
|---|---|---|---|
| Explica predicciones individuales | No | No | Sí |
| Consistente con el modelo | No (puede diferir) | No | Sí (axioma de eficiencia) |
| Maneja características correlacionadas | Mal | Mal | Mejor |
| Muestra la dirección del efecto | No | No | Sí |
| Computacionalmente costoso | Moderado | Rápido | Rápido (TreeSHAP) |
SHAP supera a la importancia de características tradicional en casi todas las dimensiones excepto la velocidad (aunque TreeSHAP es suficientemente rápido para la mayoría de aplicaciones). Para características correlacionadas, SHAP distribuye el crédito de forma más justa que la importancia por permutación, que puede asignar importancia cero a una característica relevante si una característica correlacionada absorbe su efecto.
⚠️ SHAP mide asociación, no causalidad
Un valor SHAP de +0,18 para “historial crediticio” significa que conocer el historial crediticio de este solicitante eleva la predicción del modelo 18 puntos porcentuales por encima de la línea base. No significa que cambiar el historial crediticio cambiaría el resultado en 18 puntos porcentuales en el mundo real.
SHAP explica el modelo, no el proceso generador de datos. Si el modelo ha aprendido una correlación espuria (p.ej., código postal como proxy de raza en un conjunto de datos sesgado), SHAP explicará fielmente esa asociación espuria. Las herramientas de interpretabilidad hacen los modelos más transparentes; no corrigen modelos defectuosos.
Además: los valores SHAP dependen de la distribución de referencia usada para marginalizar las características ausentes. Distintas implementaciones lo manejan de forma diferente (esperanza marginal vs. condicional), dando valores distintos para el mismo modelo. Comprueba siempre qué línea base se está usando.
💡 SHAP en R
library(shapviz) # la mejor visualización SHAP en R
library(xgboost)
# Entrenar modelo XGBoost
dtrain <- xgb.DMatrix(X_train, label=y_train)
fit <- xgb.train(params=list(eta=0.1, max_depth=5,
objective="binary:logistic"),
data=dtrain, nrounds=100)
# Calcular valores SHAP exactos (TreeSHAP)
shp <- shapviz(fit, X_pred=X_train)
# Gráfico de cascada para una observación
sv_waterfall(shp, row_id=1)
# Gráfico de resumen (beeswarm)
sv_importance(shp, kind="beeswarm")
# Gráfico de dependencia: SHAP vs valor de la característica
sv_dependence(shp, v="ingresos")
# SHAP absoluto medio (gráfico de barras de importancia global)
sv_importance(shp, kind="bar")
# Para cualquier modelo de caja negra: KernelSHAP
library(kernelshap)
ks <- kernelshap(fit_rf, X=X_train, bg_X=X_train[1:100,])
sv <- shapviz(ks)
sv_importance(sv, kind="beeswarm")
