Introducción a la regularización
La regularización añade un término de penalización a la función de pérdida para limitar la complejidad del modelo. En lugar de minimizar solo la suma de cuadrados de los residuos, se minimiza la suma de cuadrados más una penalización que encoge los coeficientes hacia cero. Esto reduce la varianza del modelo (sobreajuste) a costa de un pequeño incremento de sesgo, lo que a menudo mejora notablemente la capacidad de generalización.
El problema: sobreajuste en regresión
La regresión MCO minimiza:
\[\text{SCR}(\boldsymbol{\beta}) = \|\mathbf{y} - \mathbf{X}\boldsymbol{\beta}\|^2\]
Con muchos predictores (\(p\) grande) o predictores correlacionados, los coeficientes MCO pueden ser muy grandes con errores estándar enormes. El modelo ajusta los datos de entrenamiento perfectamente pero falla en datos nuevos.
La regularización añade una penalización:
\[\min_{\boldsymbol{\beta}} \underbrace{\|\mathbf{y} - \mathbf{X}\boldsymbol{\beta}\|^2}_{\text{pérdida}} + \underbrace{\lambda \cdot P(\boldsymbol{\beta})}_{\text{penalización}}\]
donde \(\lambda > 0\) controla la intensidad de la regularización y \(P(\boldsymbol{\beta})\) penaliza coeficientes grandes:
- Ridge (\(L_2\)): \(P(\boldsymbol{\beta}) = \|\boldsymbol{\beta}\|_2^2 = \sum_j \beta_j^2\)
- Lasso (\(L_1\)): \(P(\boldsymbol{\beta}) = \|\boldsymbol{\beta}\|_1 = \sum_j |\beta_j|\)
- ElasticNet: \(P(\boldsymbol{\beta}) = \alpha\|\boldsymbol{\beta}\|_1 + (1-\alpha)\|\boldsymbol{\beta}\|_2^2\)
La geometría que lo explica todo
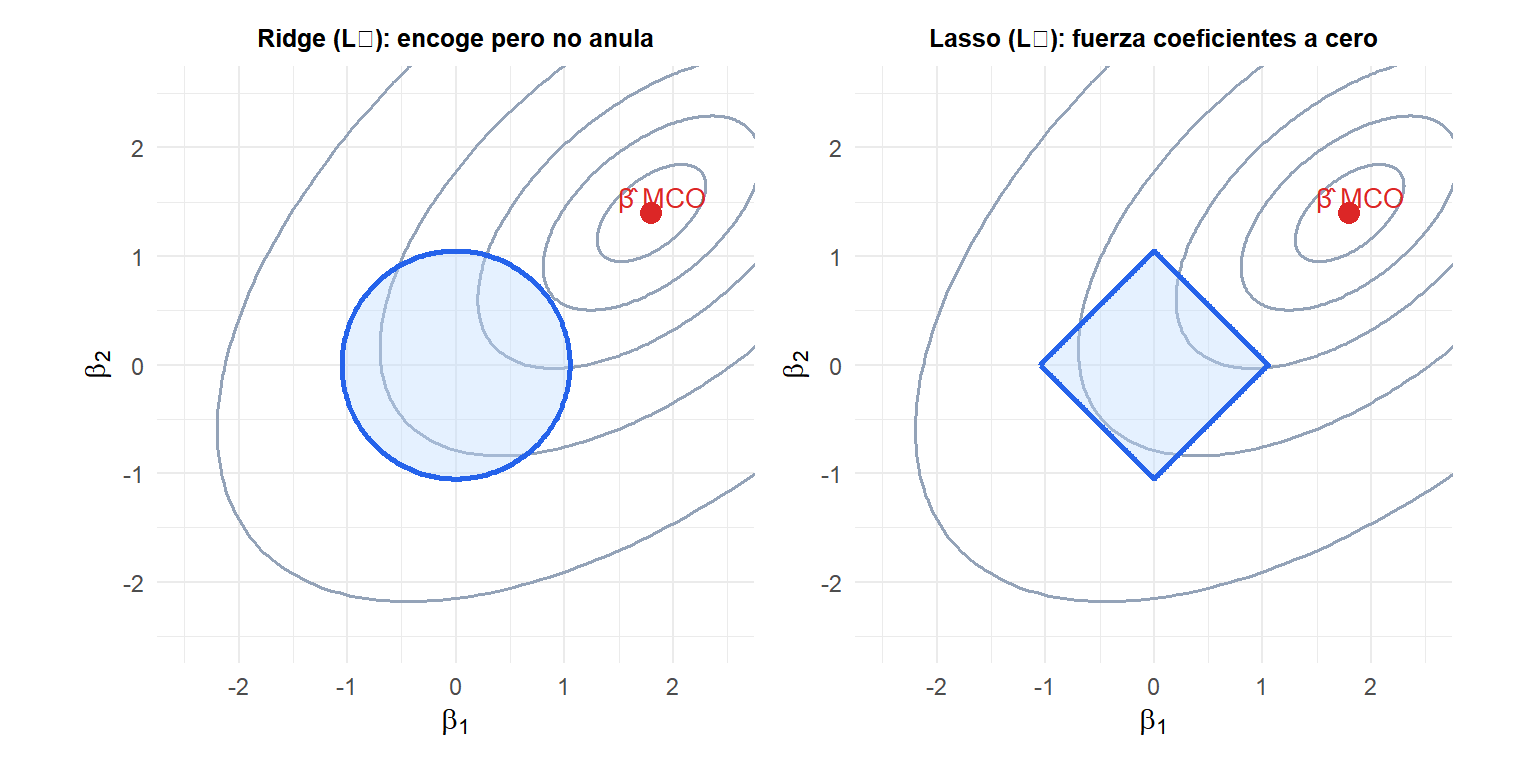
Las curvas de nivel de la SCR (elipses) se centran en \(\hat{\boldsymbol{\beta}}_{\text{MCO}}\). La región factible (azul) es la penalización: la bola \(L_2\) para Ridge (círculo), el diamante \(L_1\) para Lasso. La solución regularizada es el punto donde la curva de nivel más pequeña de la SCR toca la región factible.
La clave: el diamante \(L_1\) tiene esquinas en los ejes. Las curvas de nivel tienden a tocar el diamante en una esquina, lo que fuerza uno o más coeficientes exactamente a cero. El círculo \(L_2\) no tiene esquinas: la solución Ridge no tiene coeficientes exactamente nulos (aunque muy pequeños).
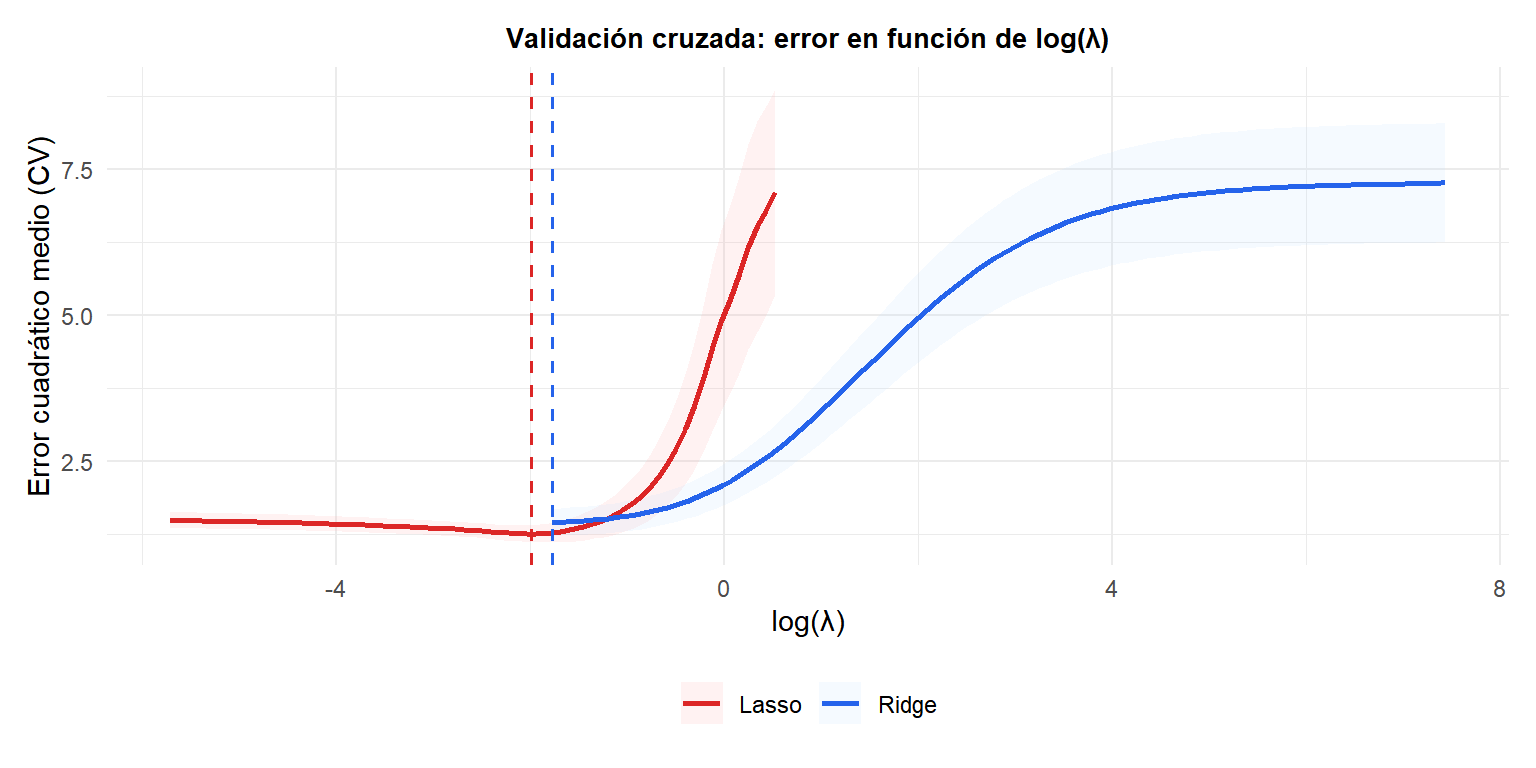
Selección de lambda con validación cruzada
\(\lambda\) es el hiperparámetro más importante. Valores grandes encogen más (más sesgo, menos varianza). Valores pequeños se aproximan al MCO.
La selección estándar es validación cruzada (CV): evaluar el error de predicción en datos no usados para entrenar, barriendo una rejilla de valores de \(\lambda\).
Interpretación bayesiana
La regularización tiene una interpretación bayesiana natural:
- Ridge: equivale a imponer una distribución a priori gaussiana \(\beta_j \sim N(0, \tau^2)\) sobre los coeficientes. El parámetro de precisión \(\lambda = \sigma^2/\tau^2\) controla cuánto se encogen los coeficientes.
- Lasso: equivale a imponer una distribución a priori de Laplace (doble exponencial) \(p(\beta_j) \propto e^{-|\beta_j|/\tau}\). Las colas más pesadas de la Laplace respecto a la gaussiana explican por qué el Lasso produce soluciones exactamente dispersas.
⚠️ Estandariza los predictores antes de regularizar
La regularización penaliza por igual todos los coeficientes. Si los predictores tienen escalas diferentes (p. ej., ingresos en euros vs edad en años), los coeficientes tendrán magnitudes muy distintas y la penalización tratará de forma injusta a los predictores con menor escala.
Estandariza siempre las variables (media cero, desviación típica uno) antes de aplicar Ridge, Lasso o ElasticNet. Las funciones glmnet y cv.glmnet de R estandarizan por defecto (standardize=TRUE): recuerda esto al interpretar los coeficientes.
💡 Regularización en R
library(glmnet)
# Validación cruzada para Ridge (alpha=0), Lasso (alpha=1)
cv_ridge <- cv.glmnet(X, y, alpha=0, nfolds=10)
cv_lasso <- cv.glmnet(X, y, alpha=1, nfolds=10)
# Mejor lambda y lambda 1se (más parsimonioso)
cv_lasso$lambda.min
cv_lasso$lambda.1se
plot(cv_lasso) # curva de CV
plot(cv_lasso$glmnet.fit, xvar="lambda") # ruta de coeficientes
# Coeficientes con lambda.min
coef(cv_lasso, s="lambda.min")
