Redes neuronales
Una red neuronal hacia adelante es una composición de transformaciones afines y funciones de activación no lineales. Añadir capas permite a la red aprender representaciones jerárquicas: las capas tempranas detectan patrones simples, las tardías los combinan en representaciones complejas. La retropropagación calcula eficientemente el gradiente de la pérdida respecto a todos los pesos mediante la regla de la cadena, permitiendo al descenso por gradiente optimizar millones de parámetros.
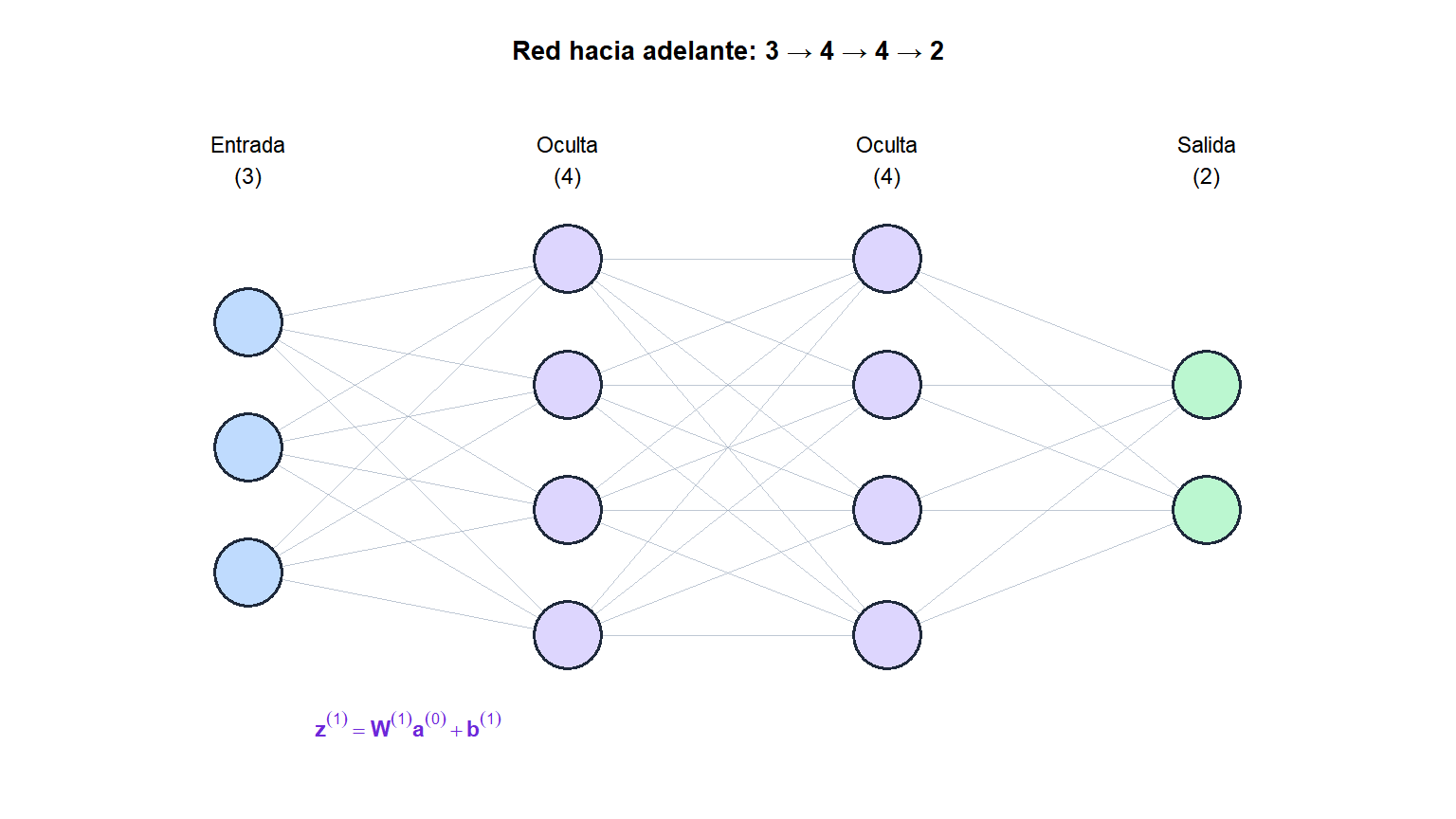
Arquitectura
Una red con \(L\) capas calcula:
\[\mathbf{a}^{(0)} = \mathbf{x} \quad (\text{entrada})\]
\[\mathbf{z}^{(\ell)} = \mathbf{W}^{(\ell)}\mathbf{a}^{(\ell-1)} + \mathbf{b}^{(\ell)}, \qquad \mathbf{a}^{(\ell)} = g^{(\ell)}(\mathbf{z}^{(\ell)}), \qquad \ell = 1,\ldots,L\]
donde \(\mathbf{W}^{(\ell)}\) y \(\mathbf{b}^{(\ell)}\) son la matriz de pesos y el vector de sesgos de la capa \(\ell\), y \(g^{(\ell)}\) es la función de activación. La salida de la última capa \(\mathbf{a}^{(L)}\) es la predicción.
Teorema de aproximación universal: una red hacia adelante con una única capa oculta y una activación no lineal puede aproximar cualquier función continua sobre un dominio compacto con precisión arbitraria, dado suficientes neuronas. Esto garantiza potencia expresiva pero no dice nada sobre cómo encontrar los pesos ni cuántas neuronas se necesitan en la práctica.
Funciones de activación
Sin funciones de activación no lineales, una red profunda se reduce a una única transformación lineal independientemente de la profundidad. Las funciones de activación rompen esta linealidad.
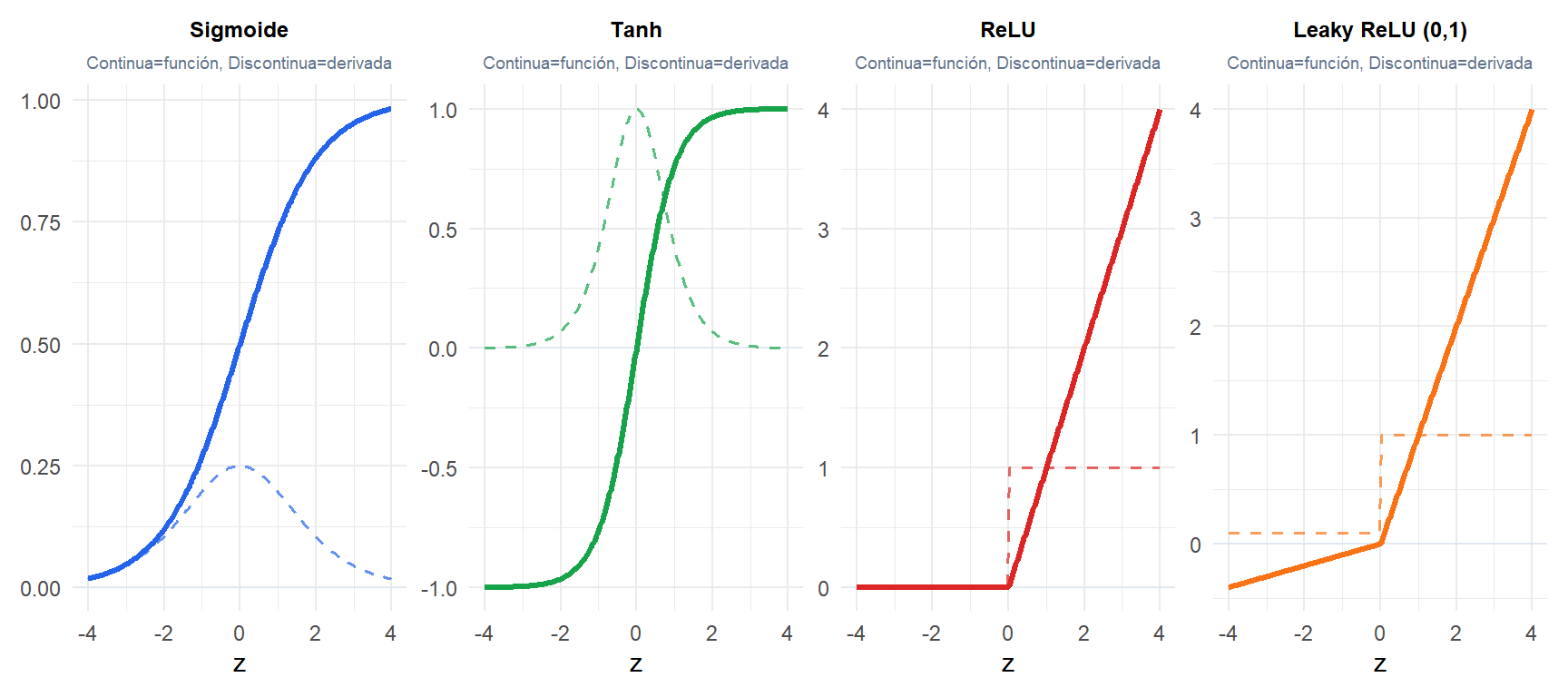
Sigmoide y tanh se saturan en valores extremos: sus derivadas se aproximan a cero, causando el problema del gradiente evanescente. ReLU (\(\max(0,z)\)) tiene una derivada constante de 1 para entradas positivas, lo que previene el gradiente evanescente y es la elección predeterminada para capas ocultas. Su debilidad: neuronas muertas (la salida de ReLU es siempre cero para entradas \(\leq 0\), por lo que el gradiente es cero y la neurona nunca se actualiza). Leaky ReLU lo soluciona permitiendo una pequeña pendiente negativa.
Retropropagación
La retropropagación calcula \(\partial \mathcal{L}/\partial \mathbf{W}^{(\ell)}\) para todas las capas eficientemente usando la regla de la cadena. Define la señal de error en la capa \(\ell\) como \(\boldsymbol{\delta}^{(\ell)} = \partial \mathcal{L}/\partial \mathbf{z}^{(\ell)}\).
Paso hacia adelante: calcula \(\mathbf{z}^{(\ell)}\) y \(\mathbf{a}^{(\ell)}\) para todas las capas, almacenando los valores intermedios.
Paso hacia atrás: comenzando desde la capa de salida:
\[\boldsymbol{\delta}^{(L)} = \nabla_{\mathbf{a}^{(L)}} \mathcal{L} \odot g'^{(L)}(\mathbf{z}^{(L)})\]
\[\boldsymbol{\delta}^{(\ell)} = \left[(\mathbf{W}^{(\ell+1)})^T \boldsymbol{\delta}^{(\ell+1)}\right] \odot g'^{(\ell)}(\mathbf{z}^{(\ell)})\]
\[\frac{\partial \mathcal{L}}{\partial \mathbf{W}^{(\ell)}} = \boldsymbol{\delta}^{(\ell)}(\mathbf{a}^{(\ell-1)})^T, \qquad \frac{\partial \mathcal{L}}{\partial \mathbf{b}^{(\ell)}} = \boldsymbol{\delta}^{(\ell)}\]
El coste total es \(O(W)\) por muestra donde \(W\) es el número de pesos: el mismo orden que un único paso hacia adelante. Sin retropropagación, la diferenciación numérica costaría \(O(W^2)\).
Actualización de pesos (SGD por mini-batch):
\[\mathbf{W}^{(\ell)} \leftarrow \mathbf{W}^{(\ell)} - \frac{\eta}{B}\sum_{i \in \mathcal{B}} \frac{\partial \mathcal{L}_i}{\partial \mathbf{W}^{(\ell)}}\]
donde \(B\) es el tamaño del mini-batch y \(\eta\) es la tasa de aprendizaje.
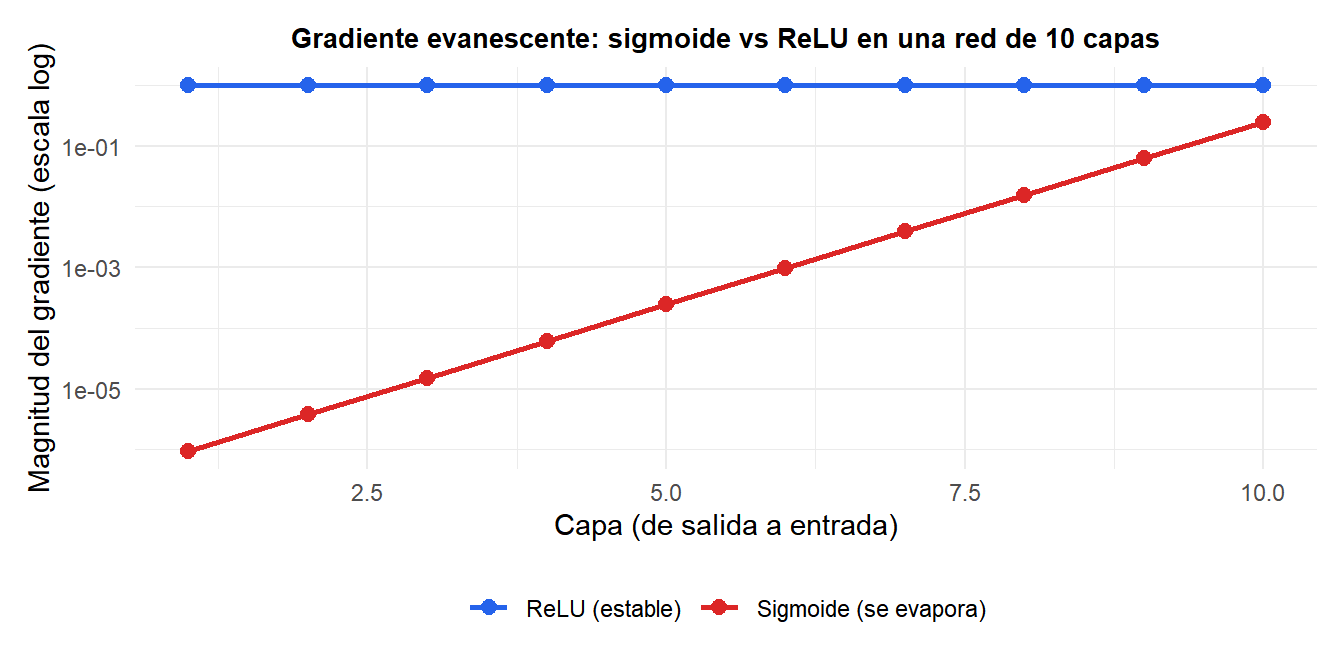
El problema del gradiente evanescente
En redes profundas con activaciones sigmoide o tanh, el gradiente de la pérdida respecto a los pesos de las capas tempranas implica productos de muchos términos como \(\sigma'(z) \leq 0{,}25\). Para una red de 10 capas: \(0{,}25^{10} \approx 10^{-6}\). El gradiente desaparece efectivamente, y las capas tempranas aprenden extremadamente despacio o no aprenden.
Regularización
Las redes neuronales tienen muchos parámetros y sobreajustan fácilmente sin regularización.
Dropout
En cada paso de entrenamiento, anula aleatoriamente la salida de cada neurona con probabilidad \(p\) (típicamente 0,2-0,5). En inferencia, escala las salidas por \((1-p)\). Esto previene la co-adaptación: ninguna neurona puede depender de que otras neuronas específicas estén presentes. Equivale a entrenar un ensemble de \(2^n\) redes diferentes y promediar sus predicciones.
Normalización por lotes
Tras cada transformación lineal, normaliza las activaciones a media cero y varianza unitaria sobre el mini-batch, luego las reescala con parámetros aprendidos \(\gamma\) y \(\beta\):
\[\hat{\mathbf{z}} = \frac{\mathbf{z} - \mu_{\mathcal{B}}}{\sqrt{\sigma_{\mathcal{B}}^2 + \varepsilon}}, \qquad \mathbf{a} = \gamma\hat{\mathbf{z}} + \beta\]
La normalización por lotes acelera el entrenamiento reduciendo el cambio de covariables interno, permite tasas de aprendizaje más altas y tiene un efecto de regularización moderado. Es estándar en la mayoría de arquitecturas modernas de deep learning.
Weight decay (regularización \(L_2\))
Añade \(\lambda\|\mathbf{W}\|_F^2\) a la pérdida. Encoge los pesos hacia cero, reduciendo la complejidad del modelo. Equivalente a una prior gaussiana sobre los pesos desde una perspectiva bayesiana.
⚠️ Las redes neuronales requieren una inicialización cuidadosa
Si los pesos se inicializan a cero, todas las neuronas calculan la misma salida y reciben el mismo gradiente: la red nunca rompe la simetría. Si los pesos son demasiado grandes, las activaciones se saturan y los gradientes se evanecen. Si son demasiado pequeños, las señales se desvanecen a través de las capas.
Inicialización estándar: inicialización He (\(\mathbf{W} \sim N(0, 2/n_\text{entrada})\)) para ReLU; inicialización Glorot/Xavier (\(\mathbf{W} \sim N(0, 2/(n_\text{entrada}+n_\text{salida}))\)) para tanh/sigmoide. Estas mantienen la varianza de las activaciones y los gradientes aproximadamente constante entre capas.
💡 Redes neuronales en R
library(torch)
# Define a simple feedforward network
net <- nn_module(
initialize = function() {
self$fc1 <- nn_linear(10, 64)
self$fc2 <- nn_linear(64, 32)
self$fc3 <- nn_linear(32, 1)
self$drop <- nn_dropout(p=0.3)
},
forward = function(x) {
x %>% self$fc1() %>% nnf_relu() %>%
self$drop() %>%
self$fc2() %>% nnf_relu() %>%
self$fc3() %>% torch_sigmoid()
}
)
# With keras (simpler interface)
library(keras)
model <- keras_model_sequential() %>%
layer_dense(64, activation="relu", input_shape=10) %>%
layer_batch_normalization() %>%
layer_dropout(0.3) %>%
layer_dense(32, activation="relu") %>%
layer_dense(1, activation="sigmoid")
model %>% compile(optimizer="adam",
loss="binary_crossentropy",
metrics="accuracy")
model %>% fit(X_train, y_train, epochs=50,
batch_size=32, validation_split=0.2)
