Random forest
El random forest construye un gran número de árboles de decisión profundos sobre muestras bootstrap de los datos, usando un subconjunto aleatorio de características en cada división. La predicción final es el voto mayoritario (clasificación) o la media (regresión) entre todos los árboles. Promediar muchos árboles descorrelacionados reduce drásticamente la varianza sin alterar esencialmente el sesgo, haciendo del random forest uno de los algoritmos más fiables listos para usar en machine learning.
De un único árbol al bagging
Un único árbol de decisión tiene sesgo bajo pero varianza alta: pequeños cambios en los datos de entrenamiento pueden producir un árbol completamente diferente. La idea clave detrás del bagging (bootstrap aggregating): si promediamos muchos estimadores independientes e insesgados, la varianza del promedio es \(\sigma^2/B\) donde \(B\) es el número de estimadores.
Para \(B\) árboles con varianza \(\sigma^2\) cada uno y correlación por pares \(\rho\), la varianza del promedio es:
\[\text{Var}\!\left(\frac{1}{B}\sum_{b=1}^B \hat{f}_b(\mathbf{x})\right) = \rho\sigma^2 + \frac{1-\rho}{B}\sigma^2\]
Cuando \(B \to \infty\), el segundo término desaparece. La varianza restante es \(\rho\sigma^2\): la correlación entre árboles establece un suelo a lo que el bagging puede ayudar. Los árboles entrenados en muestras bootstrap de los mismos datos están correlacionados (todos usan los mismos predictores fuertes), por lo que el bagging solo deja una varianza sustancial.
La innovación del random forest: en cada división, solo se considera un subconjunto aleatorio de \(m\) características (en lugar de todas las \(p\)). Esto impide que los predictores fuertes dominen cada árbol, descorrelacionando el ensemble y reduciendo \(\rho\).
- Clasificación: \(m = \lfloor\sqrt{p}\rfloor\) (por defecto)
- Regresión: \(m = \lfloor p/3 \rfloor\) (por defecto)
El algoritmo
Para \(b = 1, \ldots, B\):
- Extrae una muestra bootstrap \(\mathcal{D}^*_b\) de tamaño \(n\) de los datos de entrenamiento (con reemplazamiento).
- Crece un árbol de decisión profundo sobre \(\mathcal{D}^*_b\). En cada nodo, selecciona \(m\) características al azar y divide por la mejor de esas \(m\).
- No podar.
Para un nuevo punto \(\mathbf{x}\):
\[\hat{f}^{RF}(\mathbf{x}) = \frac{1}{B}\sum_{b=1}^B \hat{f}_b(\mathbf{x}) \quad \text{(regresión)}\]
\[\hat{c}^{RF}(\mathbf{x}) = \text{voto mayoritario}\{c_b(\mathbf{x})\}_{b=1}^B \quad \text{(clasificación)}\]
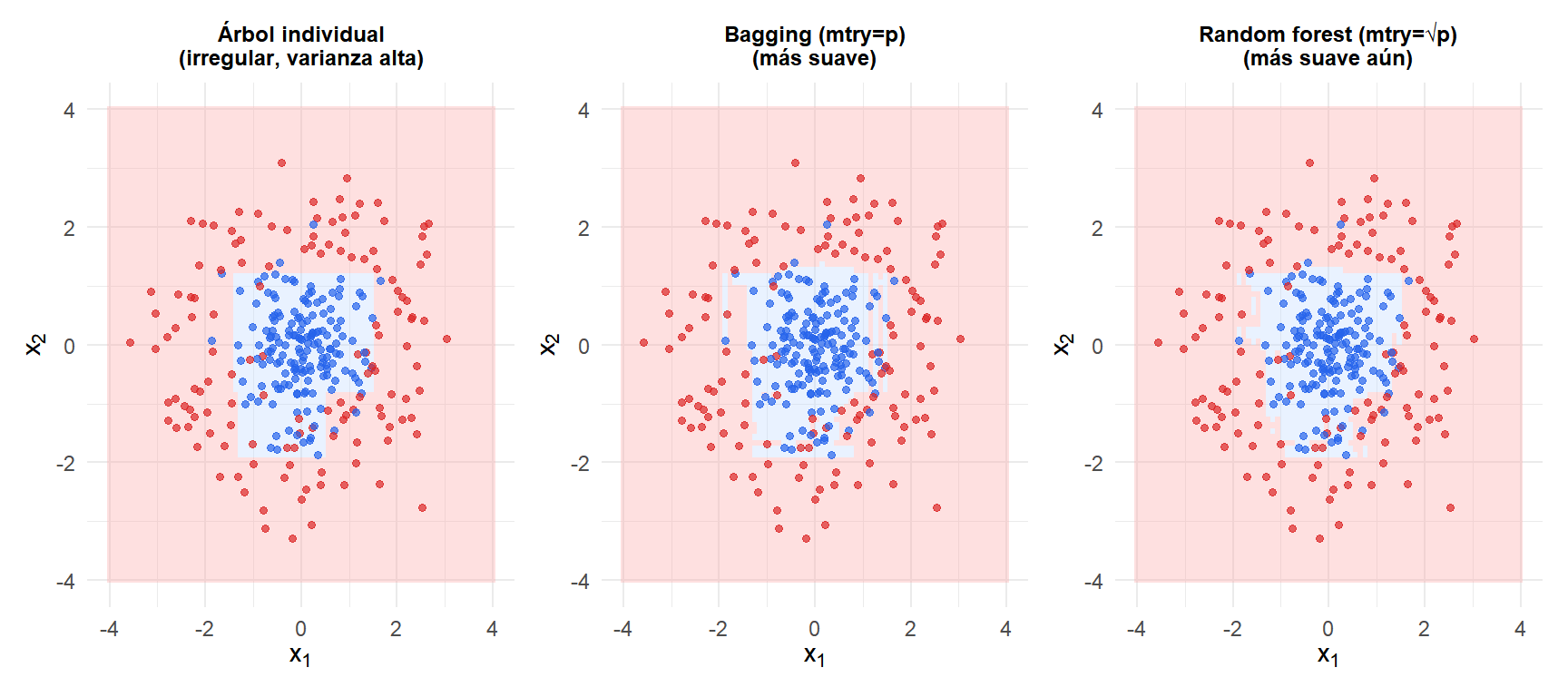
El árbol individual (izquierda) tiene una frontera irregular que sigue el ruido. El bagging (centro) la suaviza, pero los árboles correlacionados limitan la mejora. El random forest (derecha) produce la frontera más suave al descorrelacionar los árboles mediante el submuestreo de características.
Error out-of-bag
Cada muestra bootstrap omite aproximadamente \(1/e \approx 37\%\) de las observaciones de entrenamiento (las observaciones out-of-bag). El árbol \(b\) no se entrenó con sus observaciones OOB, por lo que pueden usarse como conjunto de validación:
\[\hat{f}^{OOB}(\mathbf{x}_i) = \frac{1}{|\{b: i \in \text{OOB}_b\}|} \sum_{b: i \in \text{OOB}_b} \hat{f}_b(\mathbf{x}_i)\]
El error OOB promedia los errores de predicción sobre todos los puntos de entrenamiento usando solo los árboles que no vieron ese punto. Es una estimación casi insesgada del error de test, sin necesitar un conjunto de validación separado.
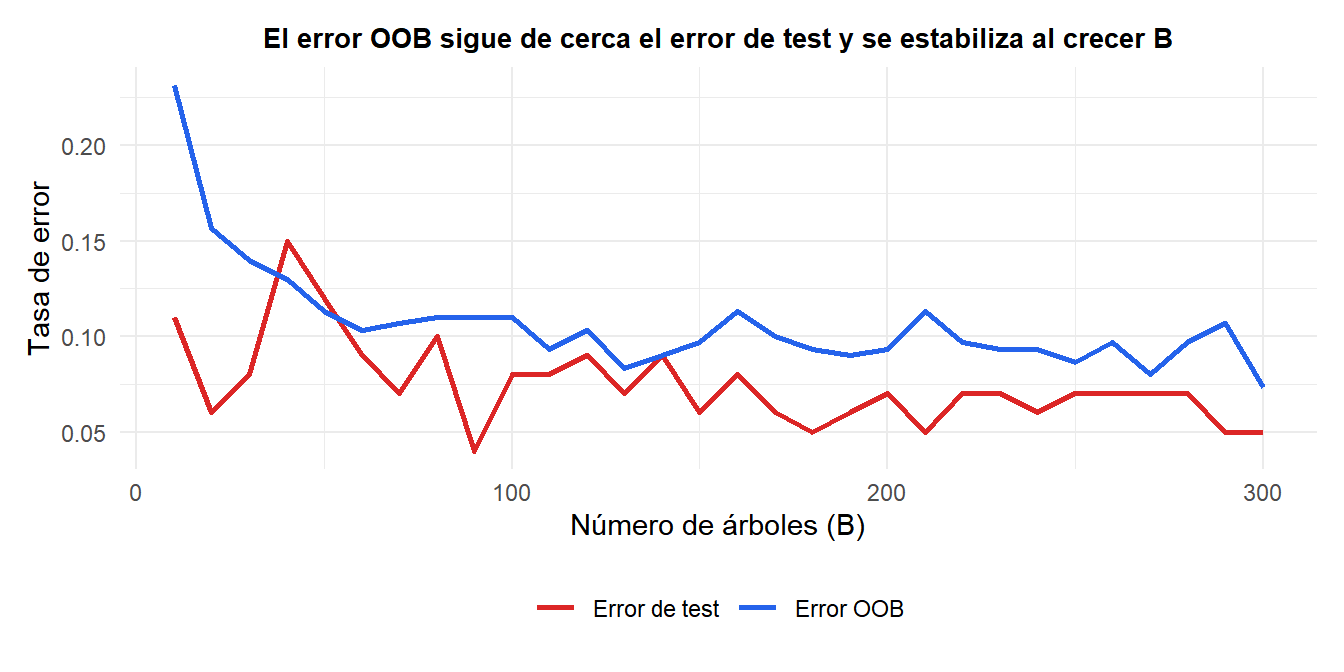
El error OOB (azul) sigue de cerca el error de test real (rojo) sin necesitar un conjunto de validación separado. Ambos se estabilizan después de aproximadamente 100-200 árboles: añadir más árboles más allá de este punto no mejora la precisión pero sí aumenta el tiempo de cómputo.
Importancia de características
Importancia basada en impureza (reducción media de impureza)
La importancia de la característica \(j\) es la reducción total de impureza del nodo ponderada por la proporción de muestras que llegan a cada nodo, promediada sobre todos los árboles:
\[\text{MDI}(j) = \frac{1}{B}\sum_{b=1}^B \sum_{\text{nodos sobre } j \text{ en árbol } b} \frac{n_\text{nodo}}{n} \cdot \Delta G\]
Rápida de calcular. Sesgada hacia características de alta cardinalidad: las características con muchos valores únicos tienen más oportunidades de división y tienden a puntuar más alto aunque no sean verdaderamente importantes.
Importancia por permutación (reducción media de precisión)
Para cada característica \(j\): permuta sus valores en las muestras OOB (rompiendo la asociación con la respuesta), vuelve a predecir y mide el aumento en el error OOB. Las características que importan provocarán grandes aumentos de error al permutarlas:
\[\text{MDA}(j) = \frac{1}{B}\sum_{b=1}^B \left[\text{error OOB tras permutar } j \text{ en árbol } b\right] - \text{error OOB}\]
Más fiable que la importancia basada en impureza: no está sesgada por la cardinalidad, mide la contribución predictiva real en lugar de la estructura del árbol.
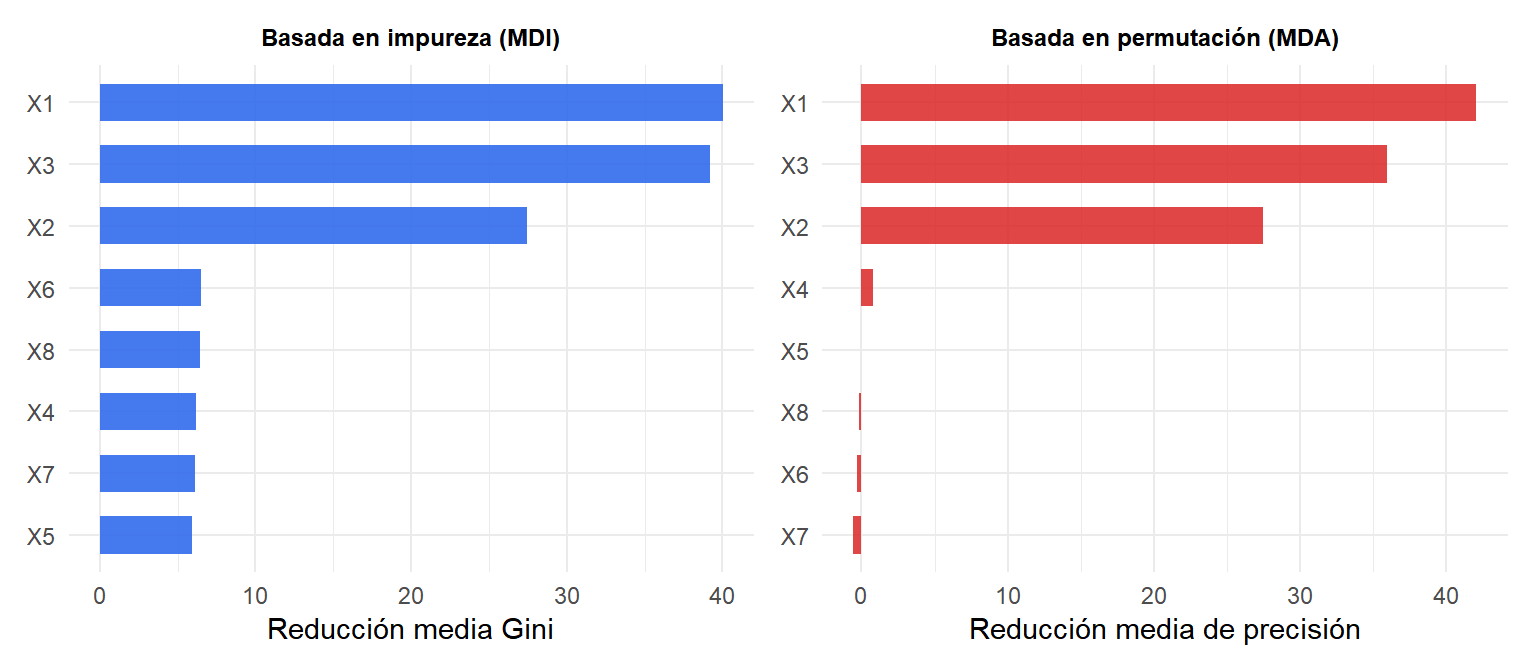
Hiperparámetros clave
| Parámetro | Por defecto | Efecto |
|---|---|---|
ntree (\(B\)) |
500 | Más árboles = menor varianza, rendimientos decrecientes tras ~200 |
mtry (\(m\)) |
\(\sqrt{p}\) / \(p/3\) | Menor \(m\) = árboles más descorrelacionados, mayor sesgo individual |
maxdepth |
Ninguno (completo) | Árboles más superficiales = mayor sesgo, menor varianza |
nodesize |
1 (clas.) / 5 (reg.) | Tamaño mínimo del nodo antes de dividir |
mtry es el hiperparámetro más importante. Ajústalo con el error OOB: prueba valores de 1 a \(p\) y elige el que tenga el menor error OOB.
⚠️ La importancia de características del random forest puede ser engañosa con características correlacionadas
Cuando dos características están altamente correlacionadas, permutar una no elimina su información (la otra la conserva). Ambas características pueden parecer poco importantes aunque el par tenga colectivamente un alto poder predictivo. Por el contrario, la importancia basada en impureza divide el mérito arbitrariamente entre ellas.
Para estimaciones de importancia fiables con características correlacionadas: usa la importancia por permutación condicional (paquete permimp), que condiciona los valores de las características correlacionadas al permutar. O usa valores SHAP (paquete treeshap) que proporcionan atribuciones consistentes y con base teórica.
💡 Random forest en R
library(randomForest)
# Clasificación
fit <- randomForest(y ~ ., data=df_train,
ntree=500, mtry=floor(sqrt(ncol(df_train)-1)),
importance=TRUE)
# Evolución del error OOB
plot(fit) # tasa de error vs número de árboles
# Importancia de características
importance(fit)
varImpPlot(fit)
# Ajustar mtry con error OOB
library(caret)
ctrl <- trainControl(method="oob")
fit_cv <- train(y ~ ., data=df_train, method="rf",
trControl=ctrl,
tuneGrid=data.frame(mtry=c(1,2,3,5,8)))
fit_cv$bestTune
# Random forest de regresión
fit_reg <- randomForest(y ~ ., data=df_train, ntree=500)
fit_reg$mse # MSE OOB por árbol
