K-medias (k-means)
K-medias divide \(n\) observaciones en \(K\) clusters minimizando la varianza total intra-cluster. Alterna entre asignar cada punto a su centroide más cercano y recalcular los centroides hasta la convergencia. Simple, rápido y escalable a grandes conjuntos de datos, k-medias es el punto de partida por defecto para el clustering. Su principal limitación: asume clusters esféricos de tamaño similar.
Función objetivo
K-medias minimiza la suma de cuadrados intra-cluster (WCSS):
\[\min_{C_1,\ldots,C_K} \sum_{k=1}^K \sum_{\mathbf{x}_i \in C_k} \|\mathbf{x}_i - \boldsymbol{\mu}_k\|^2\]
donde \(\boldsymbol{\mu}_k = \frac{1}{|C_k|}\sum_{\mathbf{x}_i \in C_k} \mathbf{x}_i\) es el centroide del cluster \(k\). Esto equivale a maximizar la varianza entre clusters: un buen clustering concentra los puntos dentro de los clusters y separa los clusters entre sí.
La optimización es NP-difícil en general (número exponencial de particiones que comprobar), pero el algoritmo de Lloyd encuentra un mínimo local eficientemente.
El algoritmo de Lloyd
Inicialización: coloca \(K\) centroides en el espacio de características (véase k-means++ más abajo).
Repetir hasta convergencia:
Paso de asignación: asigna cada punto a su centroide más cercano:
\[c_i = \arg\min_{k} \|\mathbf{x}_i - \boldsymbol{\mu}_k\|^2\]
Paso de actualización: recalcula cada centroide como la media de sus puntos asignados:
\[\boldsymbol{\mu}_k = \frac{1}{|C_k|}\sum_{i: c_i=k} \mathbf{x}_i\]
Cada paso decrece o mantiene la WCSS, por lo que el algoritmo siempre converge. Sin embargo, converge a un mínimo local, no necesariamente al global.
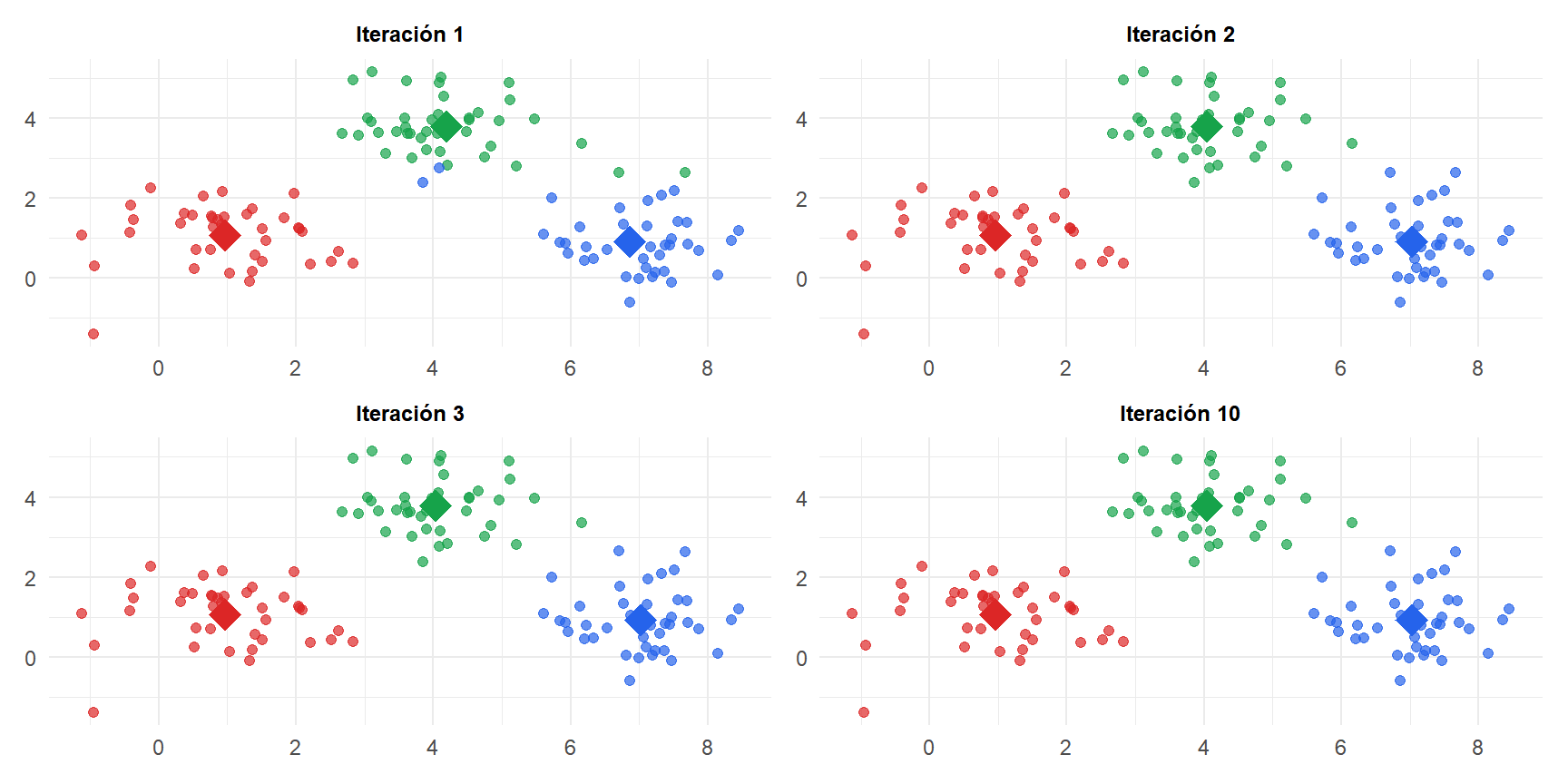
Los diamantes son los centroides. Tras la iteración 1 las asignaciones son aproximadas; en la iteración 10 el algoritmo ha convergido a los tres clusters correctos.
Inicialización K-means++
La inicialización aleatoria puede llevar a mínimos locales malos: si dos centroides comienzan en el mismo cluster, ese cluster se dividirá artificialmente. K-means++ selecciona centroides iniciales separados entre sí:
- Elige el primer centroide uniformemente al azar entre los datos.
- Para cada centroide siguiente: elige un punto con probabilidad proporcional a su distancia cuadrada al centroide ya elegido más cercano.
- Repite hasta tener \(K\) centroides.
Esto proporciona una garantía de aproximación \(O(\log K)\) a la WCSS óptima en expectativa, y en la práctica reduce el número de iteraciones necesarias y la probabilidad de soluciones malas. K-means++ es el método predeterminado en la mayoría de implementaciones.
Elegir K
Método del codo
Representa la WCSS en función de \(K\). La WCSS siempre decrece al aumentar \(K\) (con \(K=n\) cada punto es su propio cluster, WCSS=0). El “codo” es el punto donde añadir otro cluster da rendimientos decrecientes.
Puntuación de silueta
Para cada punto \(i\), sea \(a_i\) su distancia media a los puntos de su propio cluster y \(b_i\) su distancia media a los puntos del cluster más cercano diferente:
\[s_i = \frac{b_i - a_i}{\max(a_i, b_i)} \in [-1, 1]\]
\(s_i \approx 1\): bien agrupado. \(s_i \approx 0\): en la frontera entre clusters. \(s_i < 0\): probablemente en el cluster incorrecto. La puntuación de silueta media sobre todos los puntos se maximiza en el mejor \(K\).
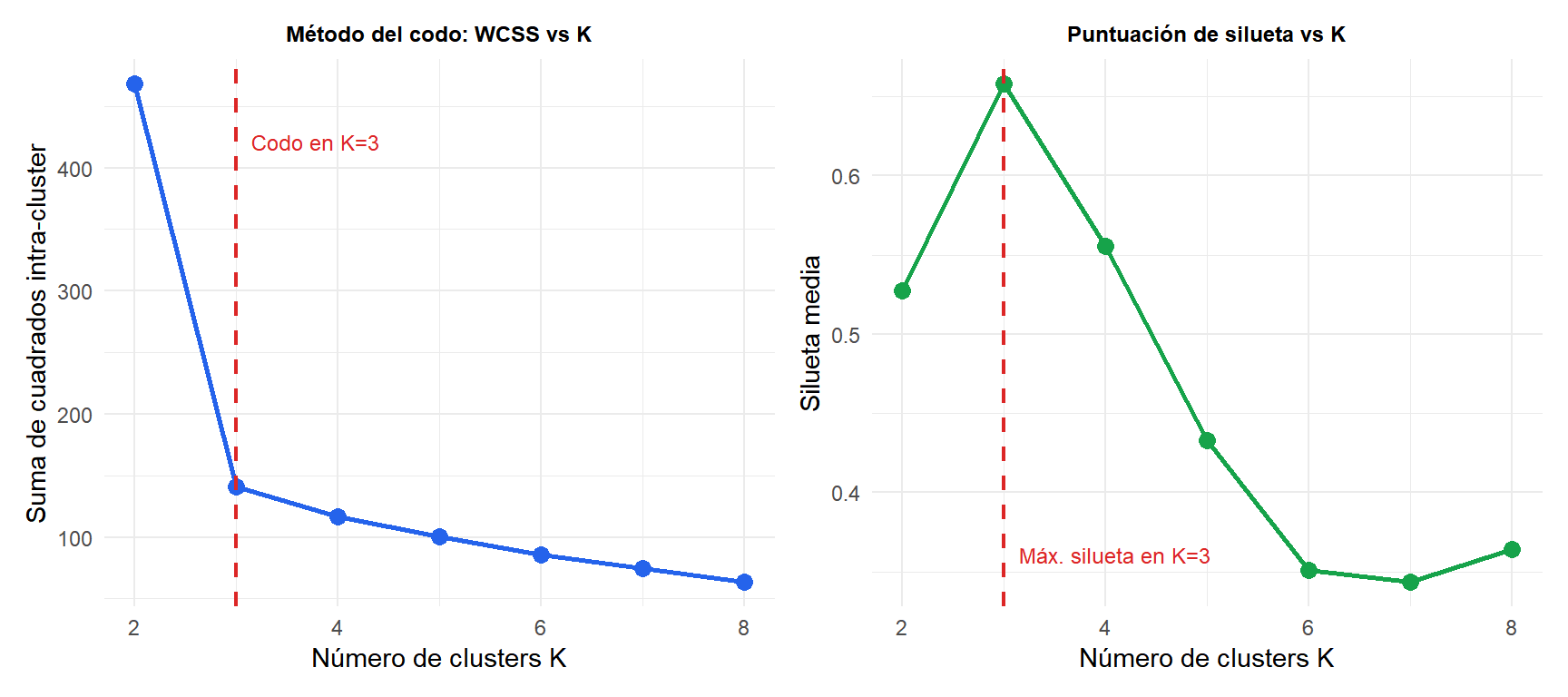
Ambos métodos identifican correctamente \(K=3\) como óptimo para este conjunto de datos: el codo es claro y la silueta se maximiza en \(K=3\).
Cuándo falla K-medias
K-medias asume que los clusters son esféricos (distancia euclídea al centroide), de tamaño aproximadamente igual y con densidad similar. Falla cuando se violan estos supuestos.
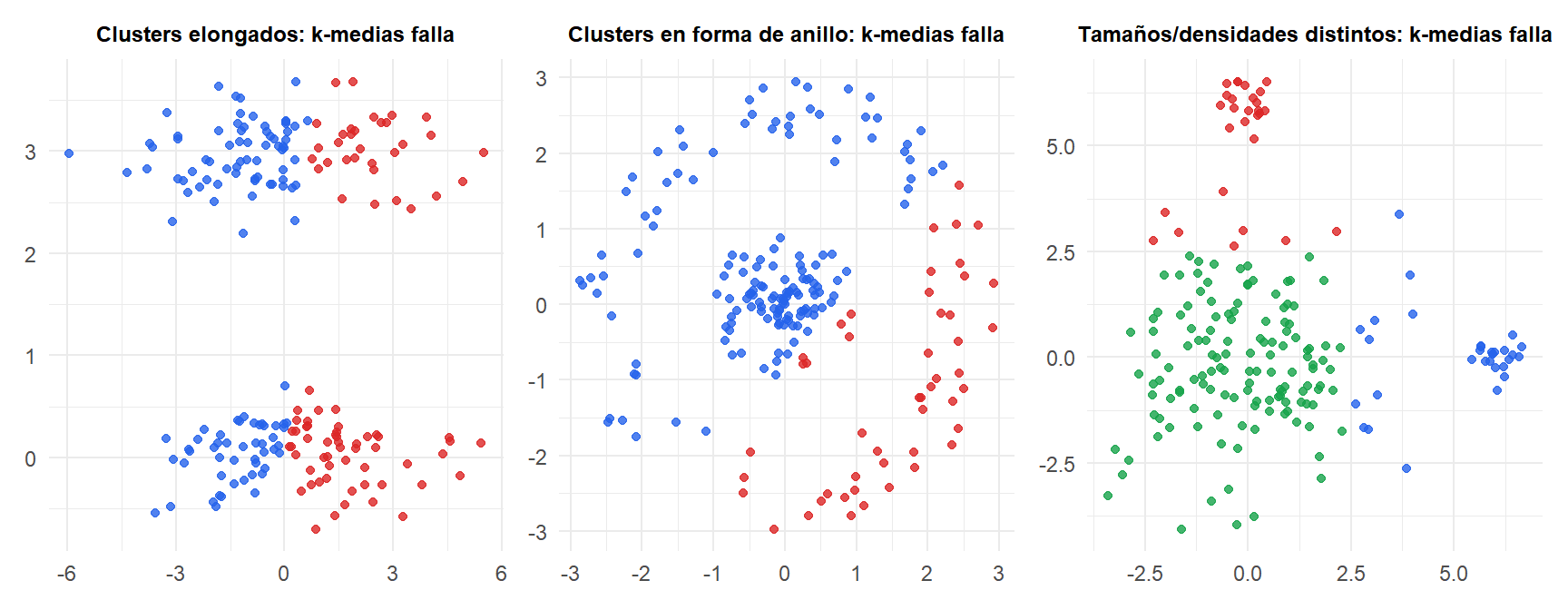
Para clusters no esféricos o de tamaño diferente, usa DBSCAN (basado en densidad) o agrupamiento jerárquico con el enlace apropiado.
⚠️ K-medias es sensible a valores atípicos y a la escala de las características
Un único valor atípico lejos de cualquier centroide de cluster atraerá el centroide hacia él, distorsionando el cluster entero. Estandariza las características antes de ejecutar k-medias (de lo contrario, las características con rangos grandes dominan la distancia), y considera eliminar o ponderar menos los valores atípicos primero.
Además: k-medias no es determinista. Ejecuta siempre con múltiples inicializaciones aleatorias (nstart=20 o más) y toma la solución con la WCSS más baja. Una única ejecución puede converger a un mínimo local malo.
💡 K-medias en R
# K-medias con 20 inicializaciones aleatorias (se devuelve la mejor solución)
km <- kmeans(X, centers=3, nstart=20, iter.max=100)
km$cluster # asignaciones de cluster
km$centers # coordenadas de los centroides
km$tot.withinss # WCSS total
# Método del codo
wcss <- sapply(1:10, function(k)
kmeans(X, centers=k, nstart=20)$tot.withinss)
plot(1:10, wcss, type="b", xlab="K", ylab="WCSS")
# Puntuación de silueta
library(cluster)
sil <- silhouette(km$cluster, dist(X))
mean(sil[,3]) # silueta media
plot(sil)
# Estadístico Gap
gap <- clusGap(X, FUN=kmeans, nstart=20, K.max=10, B=50)
plot(gap)
