Gradient boosting y XGBoost
El gradient boosting construye un modelo aditivo ajustando secuencialmente árboles de decisión superficiales al gradiente negativo de la función de pérdida. Cada árbol corrige los errores del ensemble actual. XGBoost refina esto con una expansión de Taylor de segundo orden de la pérdida, regularización explícita sobre los pesos de las hojas y submuestreo de columnas que reduce aún más el sobreajuste. Juntos son el algoritmo dominante en competiciones de datos tabulares.
La idea central: descenso por gradiente funcional
En lugar de minimizar la pérdida actualizando parámetros (como en el descenso por gradiente), el boosting minimiza la pérdida añadiendo funciones. La predicción en el paso \(m\) es:
\[F_m(\mathbf{x}) = F_{m-1}(\mathbf{x}) + \eta \cdot h_m(\mathbf{x})\]
donde \(h_m\) es el nuevo árbol y \(\eta\) es la tasa de aprendizaje (shrinkage). El árbol \(h_m\) se ajusta al gradiente negativo de la pérdida evaluado en las predicciones actuales:
\[r_i^{(m)} = -\left[\frac{\partial \mathcal{L}(y_i, F(\mathbf{x}_i))}{\partial F(\mathbf{x}_i)}\right]_{F=F_{m-1}}\]
Para la pérdida de error cuadrático \(\mathcal{L} = (y_i - F(\mathbf{x}_i))^2/2\): \(r_i^{(m)} = y_i - F_{m-1}(\mathbf{x}_i)\). Los árboles se ajustan a los residuos, que es la razón por la que las primeras descripciones del boosting hablaban de “ajustar residuos”. La visión del gradiente generaliza esto a cualquier pérdida diferenciable: log-loss para clasificación, error absoluto para regresión robusta, etc.
La analogía con el descenso por gradiente: el descenso por gradiente se mueve en la dirección del gradiente negativo en el espacio de parámetros; el descenso por gradiente funcional se mueve en la dirección del gradiente negativo en el espacio de funciones, añadiendo un árbol que apunta en esa dirección.
El algoritmo de gradient boosting
- Inicializa \(F_0(\mathbf{x}) = \arg\min_\gamma \sum_i \mathcal{L}(y_i, \gamma)\) (p. ej., la media de \(y\) para regresión).
- Para \(m = 1, \ldots, M\):
- Calcula los pseudo-residuos \(r_i^{(m)} = -\partial\mathcal{L}/\partial F(\mathbf{x}_i)|_{F_{m-1}}\).
- Ajusta un árbol superficial \(h_m\) a \(\{(\mathbf{x}_i, r_i^{(m)})\}\).
- Actualiza \(F_m = F_{m-1} + \eta \cdot h_m\).
- Devuelve \(F_M\).
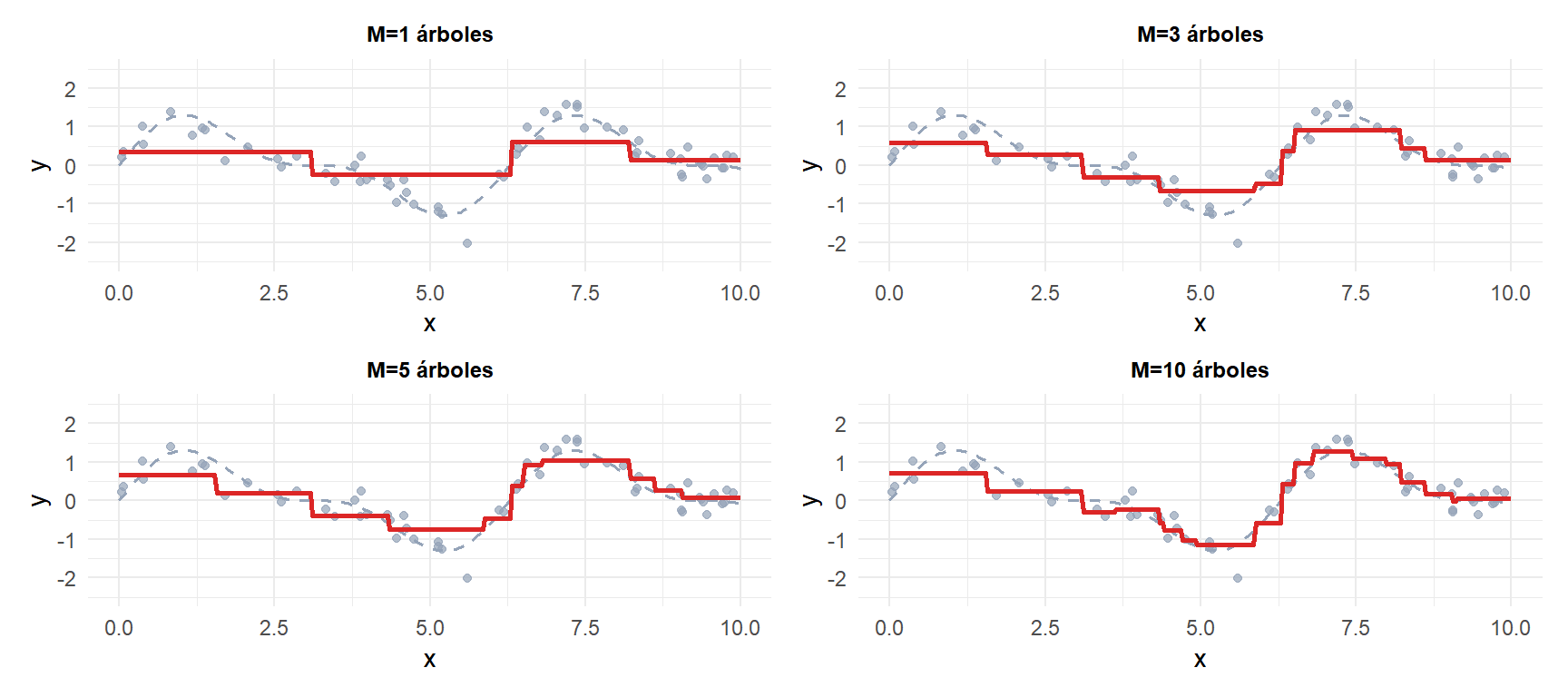
Con solo 1 árbol (arriba izquierda) el ajuste es muy brusco. A medida que se añaden más árboles, el ensemble sigue progresivamente la función real (gris discontinuo). La curva roja es la predicción actual del ensemble.
Regularización: los tres controles
El gradient boosting puede sobreajustar gravemente sin regularización. Tres controles clave:
Tasa de aprendizaje \(\eta\) (shrinkage)
Cada árbol contribuye \(\eta \cdot h_m\) en lugar de \(h_m\). Un \(\eta\) más pequeño requiere más árboles pero produce mejor generalización. La combinación óptima es \(\eta\) pequeño + \(M\) grande con parada temprana. Valores típicos: 0,01 a 0,3.
Gradient boosting estocástico (submuestreo de filas)
En cada iteración, solo se usa una fracción aleatoria \(s\) de las observaciones de entrenamiento (sin reemplazamiento) para ajustar el árbol. Esto introduce aleatoriedad que reduce el sobreajuste y acelera el entrenamiento. Valores típicos: \(s = 0,5\) a \(0,8\).
Profundidad del árbol
Los árboles superficiales (profundidad 1-6) son el estándar. Un árbol de profundidad 1 (tocón) ajusta solo efectos principales; los de profundidad 2 ajustan interacciones de pares; los más profundos ajustan interacciones de orden superior. El boosting suele funcionar mejor con árboles superficiales: la mayor parte de la complejidad proviene de combinar muchos árboles, no de árboles individuales profundos.
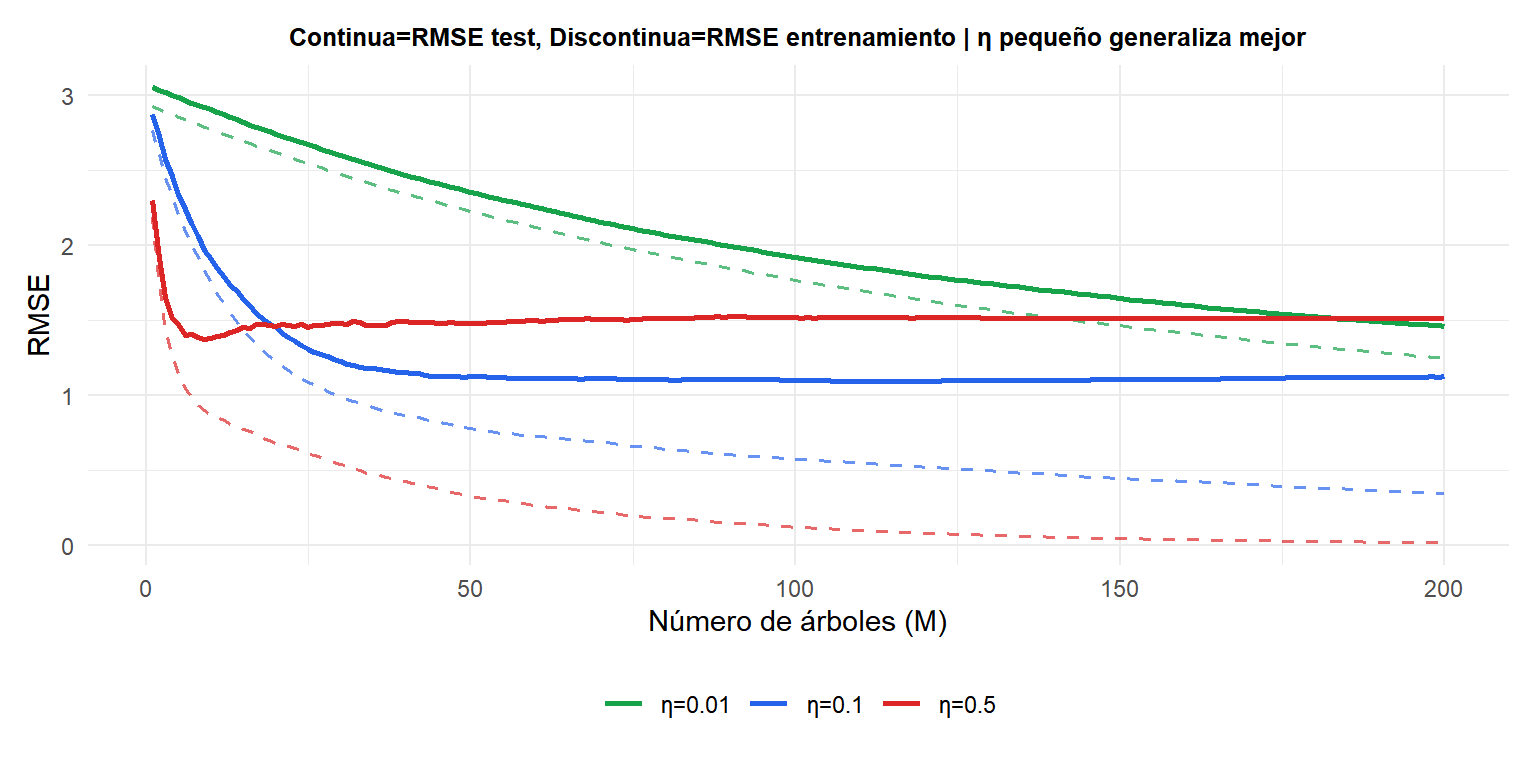
\(\eta=0{,}5\) grande (rojo) ajusta los datos de entrenamiento rápidamente pero el error de test sube pronto: sobreajuste. \(\eta=0{,}01\) pequeño (verde) desciende lentamente pero alcanza un error de test más bajo con más árboles. \(\eta=0{,}1\) medio (azul) equilibra ambos.
XGBoost: optimización de segundo orden
El gradient boosting estándar usa solo la primera derivada (gradiente) para ajustar cada árbol. XGBoost usa una expansión de Taylor de segundo orden de la pérdida:
\[\mathcal{L}^{(m)} \approx \sum_i \left[g_i f_m(\mathbf{x}_i) + \frac{1}{2}h_i f_m(\mathbf{x}_i)^2\right] + \Omega(f_m)\]
donde \(g_i = \partial\mathcal{L}/\partial \hat{y}_i\) y \(h_i = \partial^2\mathcal{L}/\partial \hat{y}_i^2\) son las derivadas de primer y segundo orden de la pérdida en la predicción actual, y:
\[\Omega(f_m) = \gamma T + \frac{1}{2}\lambda\sum_{j=1}^T w_j^2\]
penaliza el número de hojas \(T\) y los pesos cuadráticos de las hojas \(w_j\) con parámetros \(\gamma\) y \(\lambda\).
Esta formulación da un peso óptimo de hoja en forma cerrada para cada hoja \(j\):
\[w_j^* = -\frac{\sum_{i \in \text{hoja}_j} g_i}{\sum_{i \in \text{hoja}_j} h_i + \lambda}\]
y una ganancia exacta para cada candidato de división, haciendo la construcción de árboles más rápida y mejor calibrada que los métodos de primer orden.
Mejoras adicionales de XGBoost sobre GBDT clásico:
- Submuestreo de columnas (características) a nivel de árbol y de división (como random forest).
- Búsqueda de divisiones consciente de la dispersión: maneja valores faltantes y datos dispersos de forma nativa.
- Búsqueda aproximada de divisiones con bocetos de cuantiles: más rápida que la búsqueda exacta para \(n\) grande.
- Validación cruzada y parada temprana integradas.
Random forest vs gradient boosting
| Random forest | Gradient boosting | |
|---|---|---|
| Construcción de árboles | Paralela (independiente) | Secuencial (dependiente) |
| Profundidad del árbol | Profunda (completa) | Superficial (profundidad 3-6) |
| Sesgo | Bajo | Decrece con \(M\) |
| Varianza | Reducida por promediado | Controlada por \(\eta\), profundidad, submuestreo |
| Riesgo de sobreajuste | Bajo (regularizado naturalmente) | Alto sin ajuste cuidadoso |
| Complejidad de ajuste | Baja (principalmente mtry) |
Mayor (muchos hiperparámetros) |
| Velocidad de entrenamiento | Rápida (paralelizable) | Más lenta (secuencial) |
| Precisión típica | Muy buena | Mejor en datos tabulares |
Random forest es un valor predeterminado más seguro: menos ajuste, más difícil de sobreajustar. El gradient boosting con XGBoost suele lograr mayor precisión pero requiere una selección cuidadosa de hiperparámetros.
⚠️ Usa siempre parada temprana con gradient boosting
Sin parada temprana, el gradient boosting acabará sobreajustando a medida que \(M\) aumenta: el error de entrenamiento sigue bajando mientras el error de test sube. Reserva siempre un conjunto de validación o usa validación cruzada con parada temprana:
- Monitoriza la métrica de validación en cada ronda.
- Para cuando el error de validación no haya mejorado durante \(k\) rondas consecutivas (típicamente \(k=10\) a \(50\)).
- Usa el modelo en la mejor ronda de validación, no la última.
Con \(\eta\) pequeño (p. ej., 0,01), puede que necesites miles de árboles antes de que se active la parada temprana: este es el comportamiento esperado.
💡 Gradient boosting en R
library(xgboost)
dtrain <- xgb.DMatrix(X_train, label=y_train)
dval <- xgb.DMatrix(X_val, label=y_val)
params <- list(
eta = 0.05,
max_depth = 5,
subsample = 0.8,
colsample_bytree = 0.8,
lambda = 1, # L2 sobre pesos de hojas
gamma = 0, # ganancia mínima para dividir
objective = "binary:logistic",
eval_metric = "auc"
)
fit <- xgb.train(
params = params,
data = dtrain,
nrounds = 1000,
watchlist = list(train=dtrain, val=dval),
early_stopping_rounds = 30,
verbose = 1
)
# Importancia de características
xgb.importance(model=fit)
xgb.plot.importance(xgb.importance(model=fit), top_n=15)
# Validación cruzada (sin conjunto de validación separado)
cv <- xgb.cv(params=params, data=dtrain, nfold=5,
nrounds=1000, early_stopping_rounds=30)
best_nrounds <- cv$best_iteration
