Equilibrio sesgo-varianza
El equilibrio sesgo-varianza es la tensión central en el aprendizaje supervisado. Todo error de predicción se puede descomponer en tres componentes: sesgo (error sistemático por suposiciones incorrectas), varianza (sensibilidad a las fluctuaciones del conjunto de entrenamiento) y ruido irreducible. Reducir el sesgo tiende a aumentar la varianza y viceversa. Entender este equilibrio orienta cada decisión sobre la complejidad del modelo, la regularización y la recolección de datos.
La descomposición sesgo-varianza
Sea \(y = f(x) + \varepsilon\) donde \(f\) es la función verdadera y \(\varepsilon \sim (0, \sigma^2)\) es ruido irreducible. Para un modelo \(\hat{f}\) entrenado con el conjunto de datos \(\mathcal{D}\), el error de predicción esperado en un punto \(x\) es:
\[E\left[(y - \hat{f}(x))^2\right] = \underbrace{\left[f(x) - E[\hat{f}(x)]\right]^2}_{\text{Sesgo}^2} + \underbrace{E\left[\left(\hat{f}(x) - E[\hat{f}(x)]\right)^2\right]}_{\text{Varianza}} + \underbrace{\sigma^2}_{\text{Ruido irreducible}}\]
La esperanza se toma sobre todos los posibles conjuntos de entrenamiento \(\mathcal{D}\) del mismo tamaño:
- Sesgo: cuánto se aleja la predicción media del valor verdadero. Error derivado de suposiciones incorrectas incorporadas al modelo (p. ej., ajustar una recta a datos no lineales).
- Varianza: cuánto fluctúa la predicción entre distintos conjuntos de entrenamiento. Un modelo con alta varianza memoriza los datos de entrenamiento y no generaliza.
- Ruido irreducible \(\sigma^2\): la aleatoriedad inherente en \(y\) que ningún modelo puede eliminar. Cota inferior del error de predicción independientemente de la complejidad del modelo.
El error total esperado es la suma de los tres. Sesgo y varianza no pueden minimizarse simultáneamente con una cantidad fija de datos: este es el equilibrio.
Intuición: la analogía de la diana

Disparos sobre una diana: cada disparo es una predicción de un modelo entrenado con un conjunto de datos diferente. Bajo sesgo significa que los disparos están centrados en el centro. Baja varianza significa que los disparos están agrupados. El modelo ideal (arriba a la izquierda) logra ambas cosas.
Complejidad del modelo y el equilibrio
A medida que aumenta la complejidad del modelo (más parámetros, mayor grado polinómico, menos restricciones de regularización):
- El sesgo disminuye: el modelo es suficientemente flexible para capturar el patrón real.
- La varianza aumenta: el modelo es sensible al conjunto de entrenamiento concreto y ajusta el ruido.
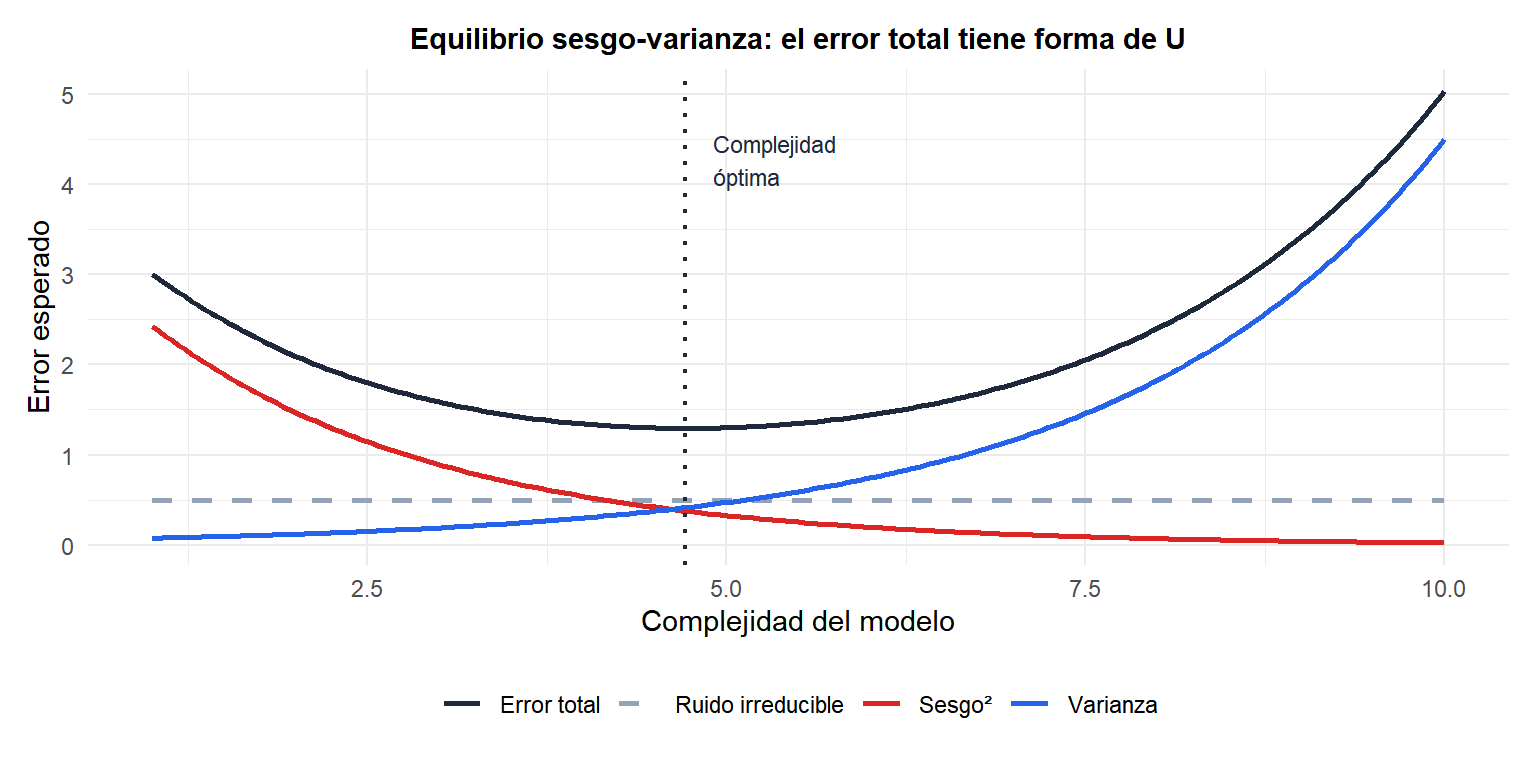
El error total (negro) tiene forma de U. La complejidad óptima minimiza la suma de sesgo y varianza. Demasiado simple (izquierda): domina el alto sesgo. Demasiado complejo (derecha): domina la alta varianza. El ruido irreducible (gris discontinuo) establece el suelo.
Ejemplo concreto: regresión polinómica
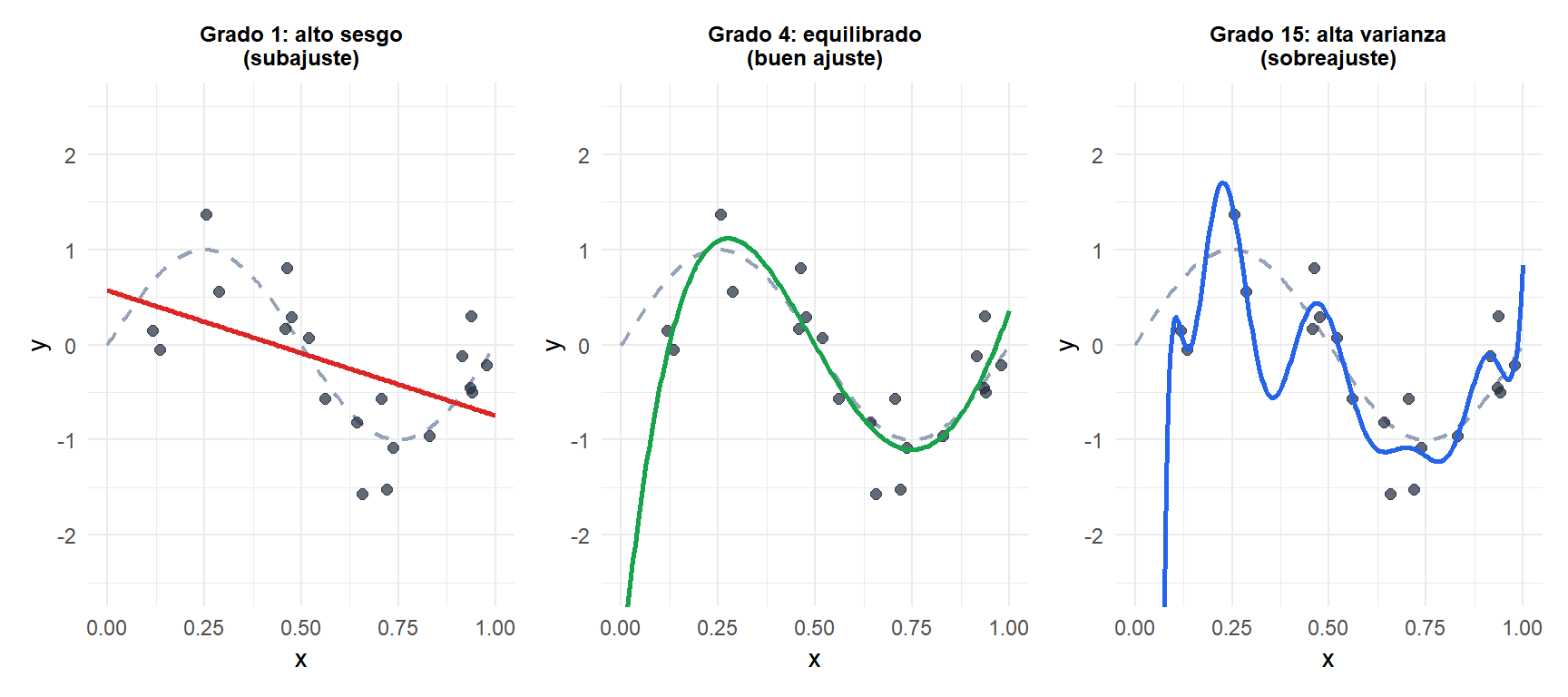
Discontinuo gris: función verdadera \(\sin(2\pi x)\). Puntos negros: datos de entrenamiento con ruido. Rojo (grado 1) no capta el patrón: alto sesgo. Verde (grado 4) se aproxima bien a la función real. Azul (grado 15) pasa por todos los puntos de entrenamiento pero oscila violentamente: alta varianza.
Gestionar el equilibrio en la práctica
Varias estrategias abordan directamente el equilibrio sesgo-varianza:
Reducir la varianza (con algún coste en sesgo):
- Regularización (Ridge, Lasso): penaliza la complejidad del modelo, contrayendo los coeficientes hacia cero. Aumenta ligeramente el sesgo, reduce la varianza de forma sustancial.
- Métodos ensemble (random forest, bagging): promedia las predicciones de muchos modelos con alta varianza para reducirla sin aumentar el sesgo.
- Más datos de entrenamiento: la varianza disminuye como \(O(1/n)\); el sesgo no se ve afectado. La solución más fiable cuando se dispone de datos.
- Dropout (redes neuronales): desactiva neuronas aleatoriamente durante el entrenamiento, actuando como un ensemble implícito.
Reducir el sesgo (con algún coste en varianza):
- Modelos más complejos: más parámetros, polinomios de mayor grado, redes más profundas.
- Ingeniería de características: añadir variables relevantes que el modelo no tenía en cuenta.
- Boosting: construye modelos secuencialmente que corrigen el sesgo de los anteriores (XGBoost, AdaBoost).
⚠️ La validación cruzada estima el error total, no sesgo y varianza por separado
El error en test (estimado mediante validación cruzada) es la suma de sesgo, varianza y ruido. Un modelo con bajo error en test podría lograrlo por bajo sesgo, baja varianza o ambos. No se pueden observar los componentes individuales a partir del error en test únicamente.
Para descomponer empíricamente sesgo y varianza, se necesitan múltiples conjuntos de entrenamiento de la misma distribución: entrenar el modelo en cada uno, calcular las predicciones en los mismos puntos de test, y luego estimar el sesgo como la diferencia cuadrada entre la predicción media y la verdad, y la varianza como la dispersión de las predicciones entre conjuntos de entrenamiento. En la práctica esto raramente es factible; la descomposición es principalmente una guía teórica.
💡 El equilibrio sesgo-varianza y la selección de modelos
Usa el siguiente esquema mental cuando elijas entre modelos:
- Error alto en entrenamiento y en test: alto sesgo. El modelo es demasiado simple. Prueba más complejidad, más variables o una clase de modelo diferente.
- Bajo error en entrenamiento, alto error en test: alta varianza. El modelo sobreajusta. Prueba regularización, más datos o un modelo más simple.
- Ambos errores son similares y aceptables: el modelo generaliza bien. El equilibrio está bien gestionado.
La diferencia entre el error en entrenamiento y en test es un indicador directo de la varianza. El nivel del error en entrenamiento es un indicador del sesgo (relativo al suelo de ruido irreducible).

