ANCOVA
El ANCOVA (Análisis de Covarianza) combina ANOVA y regresión lineal: compara las medias de un resultado entre grupos mientras ajusta por una o más variables continuas llamadas covariables. Al eliminar la variabilidad explicada por la covariable, el ANCOVA aumenta la potencia estadística y permite comparar medias ajustadas que serían las medias de grupo si todas las unidades tuvieran el mismo valor de la covariable.
El modelo
Para dos grupos (control vs tratamiento) y una covariable \(x\):
\[y_{ij} = \mu + \tau_j + \beta(x_{ij} - \bar{x}) + \varepsilon_{ij}\]
donde \(\tau_j\) es el efecto del grupo \(j\), \(\beta\) es el efecto lineal común de la covariable, y los errores \(\varepsilon_{ij} \sim N(0, \sigma^2)\) son independientes. En forma de regresión lineal:
\[y_i = \beta_0 + \beta_1 \cdot \mathbf{1}_{\text{tratamiento}} + \beta_2 x_i + \varepsilon_i\]
El supuesto clave es la homogeneidad de pendientes (o paralelismo): \(\beta\) es el mismo en todos los grupos. Esto significa que la recta de regresión de \(y\) sobre \(x\) tiene la misma pendiente en todos los grupos; solo los interceptos difieren.
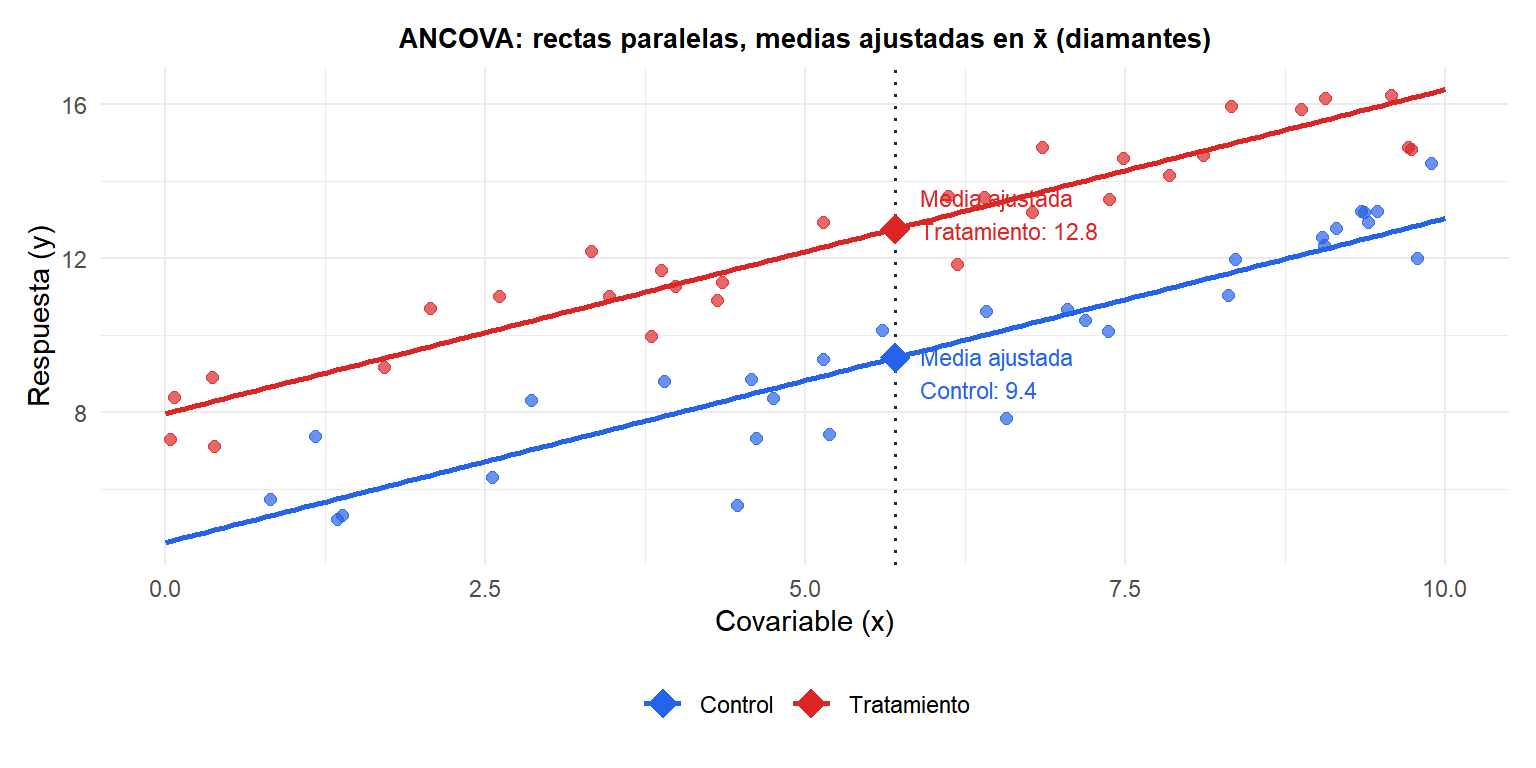
Las rectas son paralelas (misma pendiente \(\hat{\beta}_2\)) y las medias ajustadas (diamantes) son los valores predichos en \(x = \bar{x}\). La diferencia entre medias ajustadas es el efecto del tratamiento controlado por \(x\).
Medias ajustadas
Las medias ajustadas son las medias de grupo predichas en el valor medio de la covariable \(\bar{x}\):
\[\hat{\mu}_j^{\text{adj}} = \hat{\beta}_0 + \hat{\tau}_j + \hat{\beta}_2 \bar{x}\]
Son las medias que observaríamos si todos los grupos tuvieran el mismo valor de la covariable. En un experimento aleatorizado bien diseñado, los grupos tendrán medias similares en la covariable y las medias crudas y ajustadas serán parecidas. En estudios observacionales, pueden diferir sustancialmente si los grupos difieren en la distribución de la covariable.
Verificar el supuesto de homogeneidad de pendientes
El supuesto de paralelismo puede contrastarse añadiendo la interacción grupo × covariable al modelo:
\[y_i = \beta_0 + \beta_1 D_i + \beta_2 x_i + \beta_3 (D_i \times x_i) + \varepsilon_i\]
Si \(\hat{\beta}_3\) es significativamente distinto de cero, las pendientes difieren entre grupos y el ANCOVA estándar no es apropiado: las diferencias entre grupos dependen del valor de la covariable.
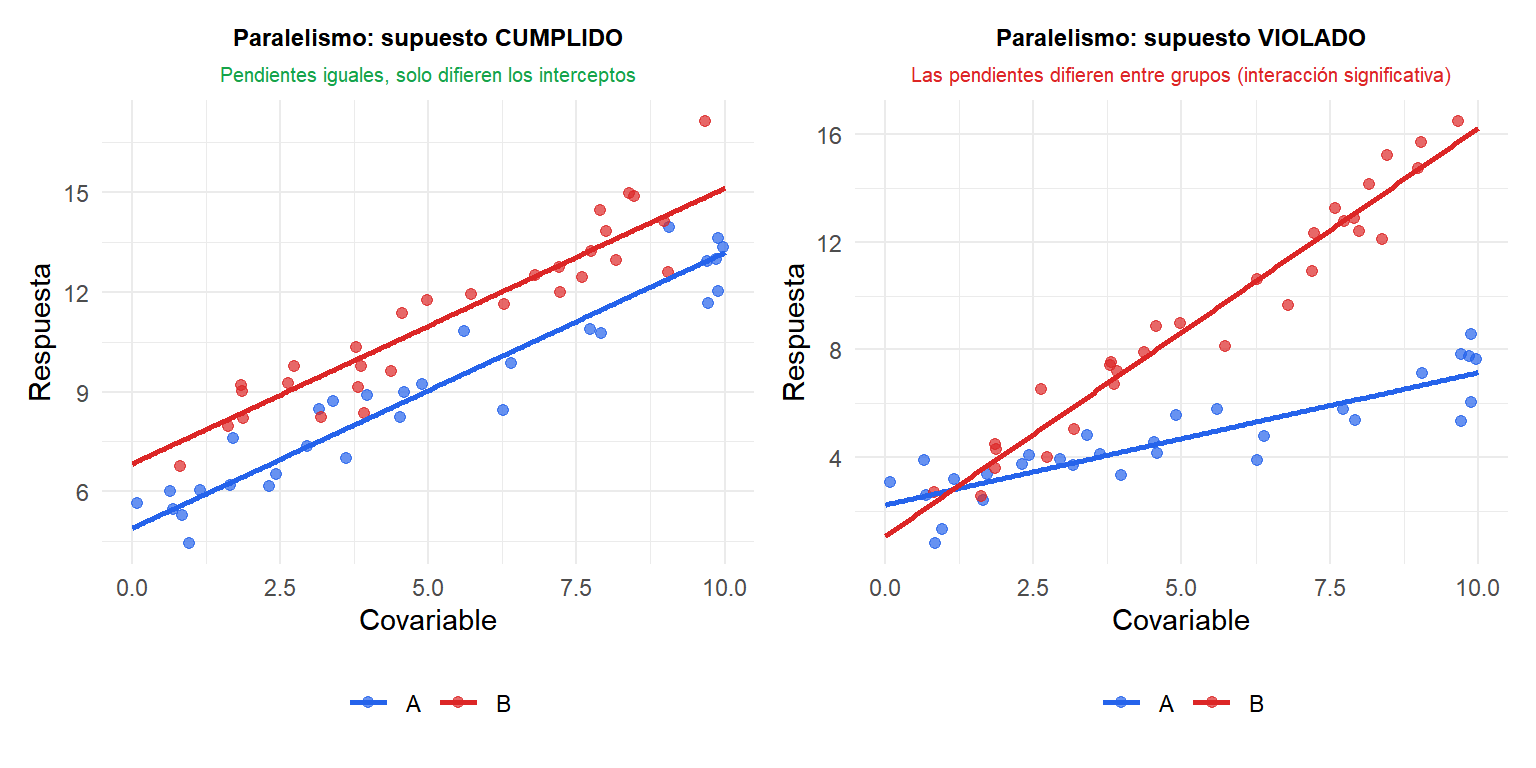
Cuando las rectas no son paralelas (panel derecho), el efecto del tratamiento no es constante: depende del valor de la covariable. En este caso, reporta la interacción directamente y describe el efecto diferencial a distintos valores de \(x\).
💡 ANCOVA en R
# ANCOVA básico: dos grupos y una covariable
fit <- lm(y ~ x + grupo, data = df)
summary(fit)
# Contraste de homogeneidad de pendientes
fit_int <- lm(y ~ x * grupo, data = df)
anova(fit, fit_int) # test F de la interacción
# Medias ajustadas
library(emmeans)
emm <- emmeans(fit, ~ grupo) # medias en x = x̄
pairs(emm) # comparaciones por pares
# Medias ajustadas en un valor específico de x
emmeans(fit, ~ grupo, at = list(x = 5))
# ANCOVA con más de una covariable
fit2 <- lm(y ~ x1 + x2 + grupo, data = df)
